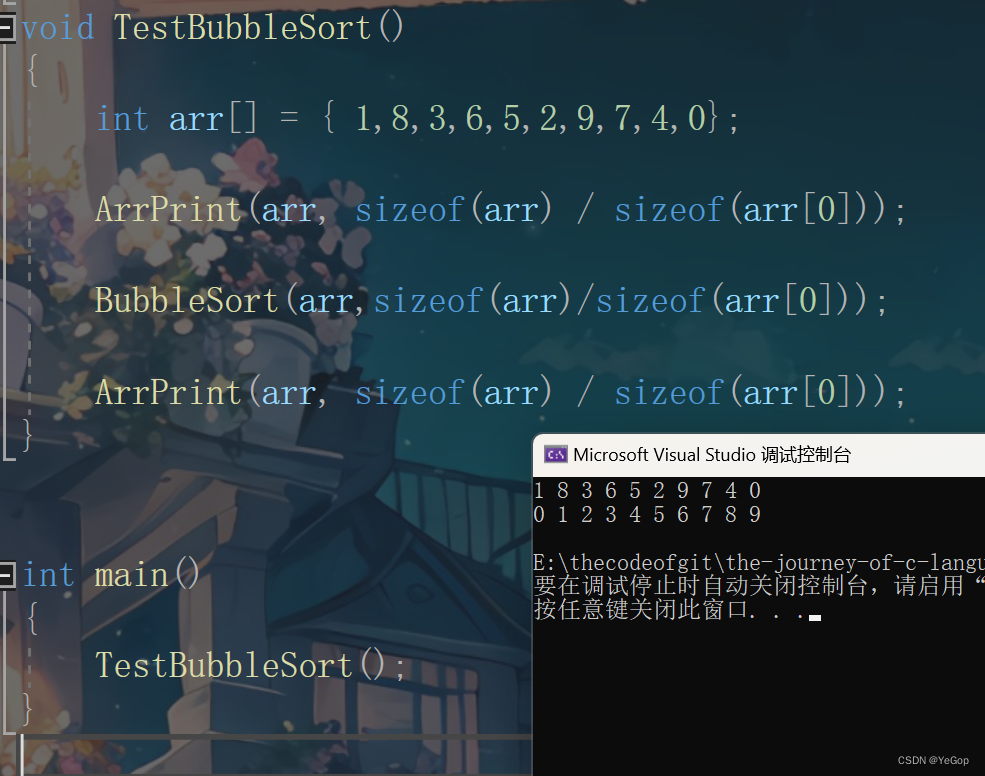
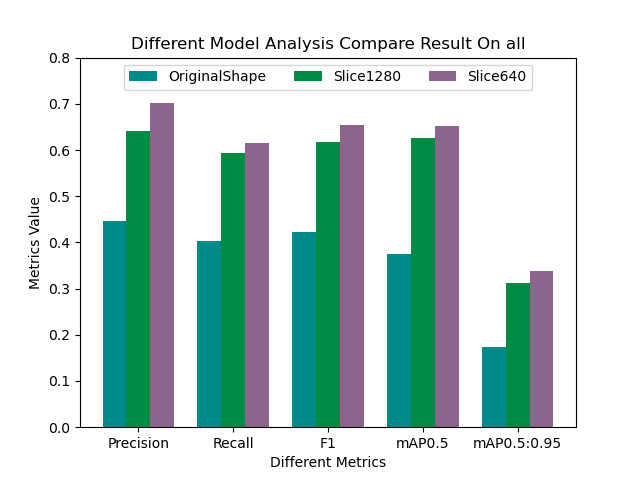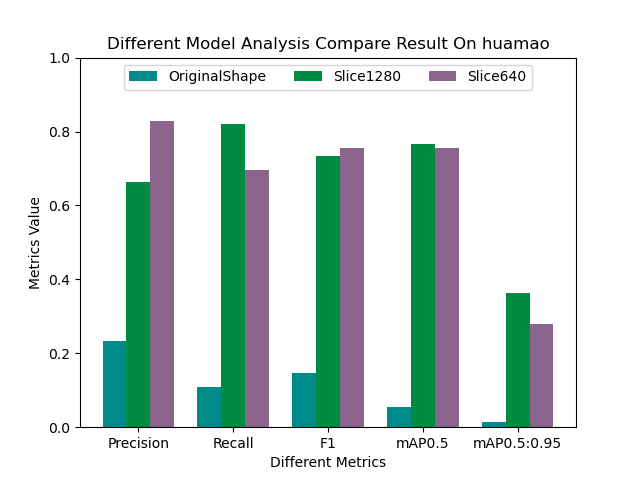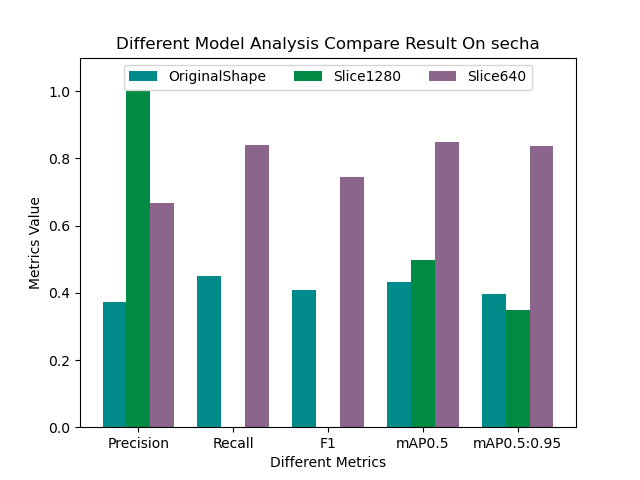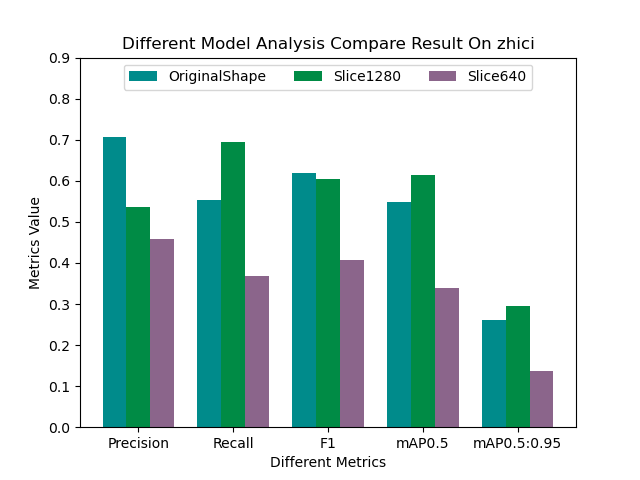
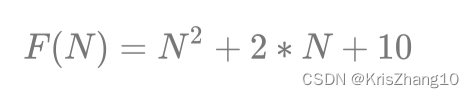常见的排序算法有很多种,每种算法都有其特定的实现方式和复杂度。以下是几种常见的排序算法及其复杂度:
冒泡排序(Bubble Sort)
- 原理:通过相邻元素之间的比较和交换,将每一轮中最大的元素“冒泡”到序列的末尾。
- 时间复杂度:
- 最优情况:O(n) (当输入序列已经有序时)
- 平均情况:O(n^2)
- 最坏情况:O(n^2)
- 空间复杂度:O(1)
选择排序(Selection Sort)
- 原理:在未排序序列中找到最小(或最大)元素,存放到排序序列的起始位置,然后再从剩余未排序元素中继续寻找最小(或最大)元素,然后放到已排序序列的末尾。
- 时间复杂度:
- 最优情况:O(n^2)
- 平均情况:O(n^2)
- 最坏情况:O(n^2)
- 空间复杂度:O(1)
插入排序(Insertion Sort)
- 原理:将未排序序列中的一个元素插入到已排序序列的适当位置,直到所有元素都插入完毕。
- 时间复杂度:
- 最优情况:O(n) (当输入序列已经有序时)
- 平均情况:O(n^2)
- 最坏情况:O(n^2)
- 空间复杂度:O(1)
归并排序(Merge Sort)
- 原理:采用分治策略,将待排序序列划分为若干个子序列,每个子序列是有序的;然后再把有序子序列合并为整体有序序列。
- 时间复杂度:
- 最优情况:O(n log n)
- 平均情况:O(n log n)
- 最坏情况:O(n log n)
- 空间复杂度:O(n)(递归调用需要额外的空间)
快速排序(Quick Sort)
- 原理:通过一次排序将待排序序列分割成独立的两部分,其中一部分的所有数据都比另一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行。
- 时间复杂度:
- 最优情况:O(n log n)
- 平均情况:O(n log n)
- 最坏情况:O(n^2) (当输入序列已经有序或逆序时)
- 空间复杂度:O(log n)(递归调用栈空间)
堆排序(Heap Sort)
- 原理:利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。
- 时间复杂度:
- 最优情况:O(n log n)
- 平均情况:O(n log n)
- 最坏情况:O(n log n)
- 空间复杂度:O(1)
希尔排序(Shell Sort)
- 原理:是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。该算法是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
- 时间复杂度:与增量序列的选择有关,通常较插入排序好。
- 空间复杂度:O(1)
每种排序算法都有其适用的场景和优缺点,需要根据具体的应用场景和需求来选择合适的排序算法。