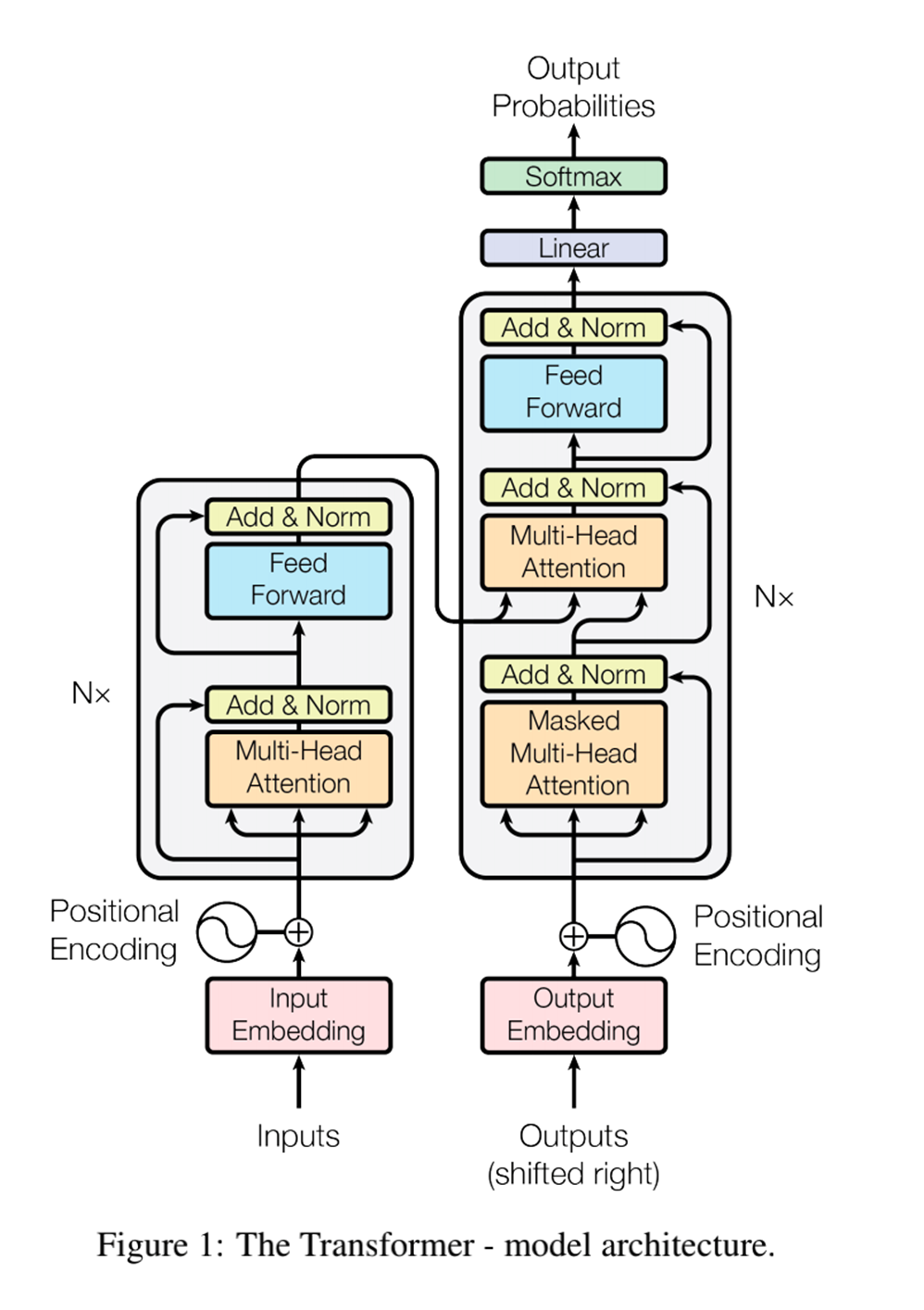
在自然语言处理领域,Transformer 模型以其革命性的架构和卓越的性能,成为了研究和应用的热门选择。其中,Transformer 编码器和解码器作为其重要组成部分,编码器在文本表示和特征提取方面发挥着重要作用,而解码器将编码器产生的上下文向量转换为目标序列。本文将深入探讨 Transformer 编码器和解码器的原理,并通过代码示例演示其实现过程。
1. 编码器介绍
Transformer 编码器是 Transformer 模型中的核心组件之一,其主要任务是将输入序列转换为上下文向量表示。相比于传统的循环神经网络(RNNs)和卷积神经网络(CNNs),Transformer 编码器采用了自注意力机制,使得模型能够并行处理输入序列,从而获得更好的性能和训练效率。
2. Transformer 编码器架构
2.1 自注意力机制
自注意力机制是 Transformer 编码器的核心,它允许模型在处理输入序列时为每个位置分配不同的注意力权重。通过计算每个位置与其他位置的相关性,自注意力机制能够捕捉输入序列中的长距离依赖关系,从而更好地理解整个序列的语义信息。
2.2 多头注意力机制
为了进一步提高模型的表达能力,Transformer 编码器引入了多头注意力机制。通过在不同的子空间上进行注意力计算,多头注意力机制使得模型能够关注输入序列中不同层次和不同方面的信息,从而更好地进行特征提取和表示学习。
2.3 前馈神经网络
除了自注意力机制外,Transformer 编码器还包含了一种全连接的前馈神经网络结构。这个网络结构通常由两个线性层和一个激活函数组成,用于对每个位置的特征进行非线性变换和映射,从而进一步提高模型的表达能力。
2.4 位置编码
由于 Transformer 编码器不具备显式的循环结构,因此需要一种方式来表示输入序列中不同位置的顺序信息。为此,Transformer 使用了位置编码(Positional Encoding)来将位置信息嵌入到输入序列中,使得模型能够感知到序列中不同位置的顺序关系。
3. Transformer 编码器实现
下面是一个简化的 Transformer 编码器的实现示例,我们将重点关注其中的关键组件:自注意力层和前馈神经网络层。
import torch
import torch.nn as nn
class EncoderLayer(nn.Module):
def __init__(self, embed_size, heads, forward_expansion, dropout):
super(EncoderLayer, self).__init__()
self.self_attention = SelfAttention(embed_size, heads)
self.norm = nn.LayerNorm(embed_size)
self.transformer_block = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size),
nn.Dropout(dropout)
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
attention = self.self_attention(x, x, x, mask)
query = self.dropout(self.norm(attention + x))
out = self.transformer_block(query)
return out
class Encoder(nn.Module):
def __init__(self, src_vocab_size, embed_size, num_layers, heads, forward_expansion, dropout, max_length):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[EncoderLayer(embed_size, heads, forward_expansion, dropout) for _ in range(num_layers)]
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(device)
x = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))
for layer in self.layers:
x = layer(x, mask)
return x
以上是一个简单的 Transformer 编码器的实现示例,其中包括了编码器层和整个编码器模型的定义。编码器通过多层编码器层堆叠来逐步提取输入序列的特征,并将其转换为上下文向量表示。
Transformer 编码器作为 Transformer 模型的重要组成部分,为文本表示和特征提取提供了一种全新的思路和方法。通过深入理解其原理,并通过代码实现,我们可以更好地掌握 Transformer 编码器的运作方式,为各种文本处理任务提供更加强大和高效的解决方案。
4. 解码器介绍
Transformer 解码器是 Transformer 模型中的一个核心组件,其主要功能是生成目标序列。与编码器相比,解码器需要处理两种类型的输入:编码器输出的上下文向量和之前生成的部分目标序列。通过自注意力机制和位置编码,解码器能够有效地捕捉输入序列的信息并生成连贯的输出序列。
5. Transformer 解码器架构
5.1 自注意力机制
与编码器类似,解码器也使用自注意力机制来对输入序列进行建模。通过关注输入序列中不同位置的相关性,解码器能够在生成每个目标标记时考虑到整个输入序列的信息。
5.2 上下文向量与位置编码
解码器的输入包括编码器输出的上下文向量和已生成的部分目标序列。上下文向量提供了输入序列的全局信息,而位置编码则确保模型能够区分不同位置的标记,并将它们嵌入到模型中。
5.3 解码器层堆叠
与编码器类似,解码器由多个层堆叠而成。每一层都包括自注意力子层和前馈神经网络子层,通过多层堆叠,模型能够逐渐提取并转换输入序列的信息,从而生成准确的目标序列。
6. Transformer 解码器实现
下面是一个简化的 Transformer 解码器实现示例,我们将关注其中的关键组件:自注意力层、前馈神经网络层以及整个解码器模型的组装。
import torch
import torch.nn as nn
class DecoderLayer(nn.Module):
def __init__(self, embed_size, heads, forward_expansion, dropout):
super(DecoderLayer, self).__init__()
self.self_attention = SelfAttention(embed_size, heads)
self.norm = nn.LayerNorm(embed_size)
self.transformer_block = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size),
nn.Dropout(dropout)
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, value, key, src_mask, trg_mask):
attention = self.self_attention(x, x, x, trg_mask)
query = self.dropout(self.norm(attention + x))
out = self.transformer_block(query)
return out
class Decoder(nn.Module):
def __init__(self, trg_vocab_size, embed_size, num_layers, heads, forward_expansion, dropout, max_length):
super(Decoder, self).__init__()
self.embed_size = embed_size
self.word_embedding = nn.Embedding(trg_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[DecoderLayer(embed_size, heads, forward_expansion, dropout) for _ in range(num_layers)]
)
self.fc_out = nn.Linear(embed_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_out, src_mask, trg_mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(device)
x = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))
for layer in self.layers:
x = layer(x, enc_out, enc_out, src_mask, trg_mask)
out = self.fc_out(x)
return out
以上是一个简单的 Transformer 解码器的实现示例,其中包括了解码器层和整个解码器模型的定义。我们可以看到,解码器通过多层解码器层堆叠来逐步生成目标序列,其中每一层包括自注意力机制和前馈神经网络。
7. 结语
Transformer 编码器和解码器在自然语言处理任务中扮演着至关重要的角色,其强大的建模能力和高效的并行计算使其成为了一种热门的架构选择。通过深入理解其原理,并通过代码实现,我们可以更好地掌握 Transformer 编码器和解码器的运作方式,为解决各种序列生成任务提供更加丰富和有效的工具。
希望本文能够帮助读者更好地理解 Transformer编码器和 解码器,并在实践中取得更加出色的成果。