目录
5.3. 定制协议 (上) --- Protocol.hpp
7.7.2. 如何在Linux在正确编写一个进程守护进程化的代码?
1. 什么叫做应用层呢?
应用层是计算机网络体系结构中的一个概念,指的是网络通信协议栈中最顶层的一层,它负责处理用户的应用程序与网络之间的交互。
通常,程序员编写的网络程序都是在应用层进行开发的。
2. 再谈协议
协议我们以前说过,它本质是一种约定。
在以前,我们编写网络服务时, 传输的都是字符串, 可如果我想要传输结构化的数据那么该怎么办呢?
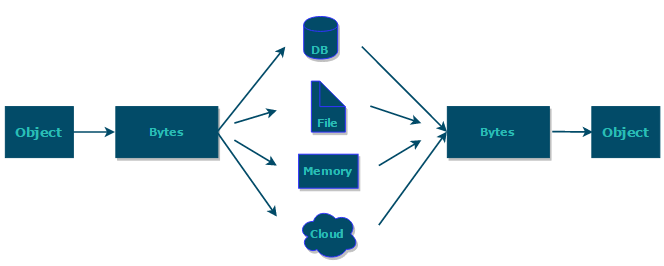
因此, 我们要认识和理解序列化和反序列化。
3. 什么叫做序列化 && 反序列化呢?
场景: 假设我要实现一个网络版本的计算器。
具体就是: 客服端需要传递两个操作数,以及一个操作符给服务端, 服务端接收后, 对其进行计算,并将结果返回给客户端。
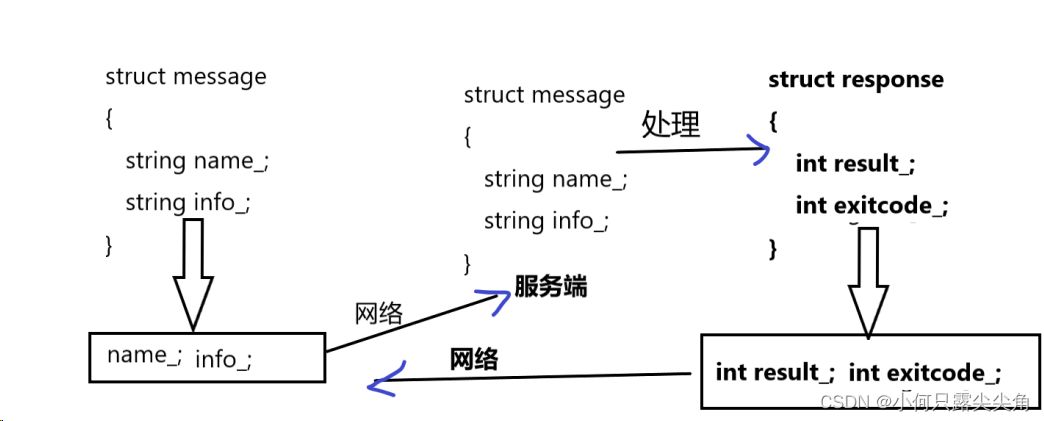
如何表示上面的数据呢? 我们发现,当客户端发送给服务端数据时, 本质是一个请求数据, 让服务端处理这个请求, 并返回其结果,也就是响应数据。
因此,我们可以用请求 (Request) 和 响应 (Responce) 分别表示它们, 具体如下:
class Request
{
public:
int _x;
int _y;
char _op;
};
class Responce
{
public:
int _result;
int _code; // 状态码
};同时我们约定:
服务端和客户端发送数据时, 首先需要将上面的结构化的数据按照特定规则转化成字符串,接收数据后需要再按照相应的规则转化成结构化的数据。
而上面这个过程,我们就称之为 "序列化" 和 "反序列化"。
序列化: 将结构化的数据转成字节流。
反序列化: 将字节流转化成结构化的数据。
4. 为什么需要序列化 && 反序列化呢?
有人说: 服务端和客户端在收发数据的时候, 为什么不直接收发结构化的数据呢? 为什么还要多做一步处理, 将结构化的数据序列化成字节流呢?
原因如下:
- 跨平台兼容性: 不同编译器对结构化的数据的处理可能不一致。 表现上就是内存对齐、大小端等问题。
- 可维护性和可扩展性:直接收发结构化的数据的可扩展性和可维护性太低。
一般而言, 关于序列化和反序列化是应用层经常做的。
但后续,我们会学习 (例如TCP、UDP) 等底层协议, 这些协议在传输的就是结构化的数据。
原因说两个:
- 稳定性和兼容性:底层协议通常不会频繁地改动,而且改动的幅度也很小。这是因为这些协议已经被广泛使用和验证,在不破坏现有系统的情况下进行改动可能会非常困难,并且可能会引入新的不稳定性和兼容性问题。因此,一旦确定了底层协议的设计,它们通常会保持相对稳定,并且需要兼容之前的版本,以确保现有的系统不会受到影响。
- 条件编译机制:内核层源码通常会使用条件编译机制,根据编译源码的平台自动选择相应的代码。这种机制允许在不同的平台上使用不同的代码路径,以确保源码在不同的操作系统或硬件上都能正确地运行。这种灵活性使得在底层协议中直接处理结构化数据成为可能,因为可以根据不同的平台选择合适的处理方式,而不需要在应用层面进行序列化和反序列化操作。
而应用层很少这样做, 首先,这样的成本很高, 而应用层需要我们保证高维护性、高扩展性, 当上层需求发生改变时,能及时做出相应调整。
总的来说, 结构化的数据一般都是给上层业务使用的, 而底层网络传输时,比较适合传输字节流式的数据, 当有了序列化和反序列化这个工作后, 就可以让上层业务和底层网络通信中间加一层中间软件层 (序列化和反序列化),以达到上层业务和网络通信一定程度上的解耦。
而我们之前说过, 协议本质就是一种约定, 那么如何体现这种约定呢? 这就取决于结构化数据的字段,换言之, 字段本身就是协议的一部分。
有了结构化数据,我们就可以做到对协议的定制工作。
5. 网络版计算器 --- 初始版本
其主要目的: 了解序列化以及反序列化的过程。
5.1. 封装套接字接口 --- Sock.hpp
代码如下:
#ifndef __SOCK_HPP_
#define __SOCK_HPP_
#include <iostream>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include "Log.hpp"
namespace Xq
{
class Sock
{
public:
Sock() :_sock(-1) {}
// 创建套接字
void Socket(void)
{
_sock = socket(AF_INET, SOCK_STREAM, 0);
if(_sock == -1)
{
LogMessage(FATAL, "%s,%d\n", strerror(errno));
exit(1);
}
LogMessage(DEBUG, "listen sock: %d create success\n", _sock);
}
// 将该套接字与传入的地址信息绑定到一起
void Bind(const std::string& ip, uint16_t port)
{
sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(port);
addr.sin_addr.s_addr = ip.empty() ? INADDR_ANY : inet_addr(ip.c_str());
int ret = bind(_sock, reinterpret_cast<const struct sockaddr*>(&addr), sizeof(addr));
if(ret == -1)
{
LogMessage(FATAL, "bind error\n");
exit(2);
}
}
// 封装listen 将该套接字设置为监听状态
void Listen(void)
{
int ret = listen(_sock, 10);
if(ret == -1)
{
LogMessage(FATAL, "listen error\n");
exit(3);
}
}
// 封装accept
// 如果想获得客户端地址信息
// 那么我们可以用输出型参数
// 同时我们需要将服务套接字返回给上层
int Accept(std::string& client_ip, uint16_t* port)
{
struct sockaddr_in client_addr;
socklen_t addrlen = sizeof client_addr;
bzero(&client_addr, addrlen);
int server_sock = accept(_sock, \
reinterpret_cast<struct sockaddr*>(&client_addr), &addrlen);
if(server_sock == -1)
{
LogMessage(FATAL, "%s,%d\n", strerror(errno));
return -1;
}
// 将网络字节序的整数转为主机序列的字符串
client_ip = inet_ntoa(client_addr.sin_addr);
// 网络字节序 -> 主机字节序
*port = ntohs(client_addr.sin_port);
// 返回服务套接字
return server_sock;
}
// 向特定服务端发起连接
void Connect(struct sockaddr_in* addr, const socklen_t* addrlen)
{
int ret = connect(_sock,\
reinterpret_cast<struct sockaddr*>(addr), \
*addrlen);
if(ret == -1)
{
LogMessage(FATAL, "%s%d\n", strerror(errno));
}
}
// 服务端结束时, 释放套接字
~Sock(void)
{
if(_sock != -1)
{
close(_sock);
LogMessage(DEBUG, "close listen sock: %d\n", _sock);
}
}
public:
int _sock; // 监听套接字
};
}
#endif5.2. 服务端的封装 --- TcpServer.hpp
#ifndef __TCPSERVER_HPP_
#define __TCPSERVER_HPP_
#include <functional>
#include <pthread.h>
#include "Protocol.hpp"
namespace Xq
{
class Server;
class ThreadData
{
public:
ThreadData(Server* ptr, int ServerSock)
:_SerPtr(ptr)
,_ServerSock(ServerSock)
{}
Server* _SerPtr;
int _ServerSock;
};
using func_t = std::function<void(int)>;
class Server
{
private:
static void* Thread_Routine(void* arg)
{
// 分离自己, 避免了后期一些处理
pthread_detach(pthread_self());
// TD_Ptr 包含对象的地址以及服务套接字
ThreadData* TD_Ptr = static_cast<ThreadData*>(arg);
// 执行服务
TD_Ptr->_SerPtr->Execute(TD_Ptr->_ServerSock);
// 执行完后, 关闭服务套接字
close(TD_Ptr->_ServerSock);
LogMessage(DEBUG, "close server sock: %d\n", TD_Ptr->_ServerSock);
// 释放这个 ThreadDate
delete TD_Ptr;
return nullptr;
}
public:
Server(uint16_t port = -1)
:_server_port(port)
{
// 创建套接字
_sock.Socket();
// 绑定套接字
// 内部会做适当的字节序转换
_sock.Bind("0.0.0.0", _server_port);
// 将该套接字设置为监听状态
_sock.Listen();
LogMessage(DEBUG, "server init success\n");
}
// 服务端要进行什么服务
// 外部传进来就可以
void BindServer(func_t func)
{
_func = func;
}
void Execute(int server_sock)
{
// 服务端需要执行的服务
_func(server_sock);
}
void start(void)
{
for(;;)
{
// 获取客户端连接
// 成功后, 返回一个服务套接字
// 同时, 如果想要获取客户端的地址信息
// 可以传递给Accept, 其内部会返回客户端地址信息(主机序列)
std::string client_ip;
uint16_t client_port;
int server_sock = _sock.Accept(client_ip, &client_port);
if(server_sock == -1)
{
LogMessage(ERROR, "accept error\n");
continue;
}
// 走到这里, 一定成功的获取了一个服务套接字
LogMessage(DEBUG, "client address info:[%s][%d], get a server sock: %d\n", client_ip.c_str(), client_port, server_sock);
pthread_t tid;
// 未来这个线程是为了提供网络服务的
// 因此这个服务套接字需要交给我们所创建的线程
// 同时这个线程还需要处理外部绑定的方法
// 外部如何绑定呢? --- 通过BindServer
// 因此这个线程还需要访问Server里的公有成员
// 而由于此时的线程回调需要避免this指针
// 因此设置为了静态成员函数, 故为了满足上面的需求
// 定义了一个ThreadData 结构
// 其包含了Server对象的地址以及服务套接字
ThreadData* TD = new ThreadData(this, server_sock);
pthread_create(&tid, nullptr, Thread_Routine, static_cast<void*>(TD));
}
}
private:
Sock _sock; // 该对象提供套接字接口
uint16_t _server_port; // 服务器端口
func_t _func; // 要执行的服务
};
}
#endif5.3. 定制协议 (上) --- Protocol.hpp
此时的协议还是未完善的, 因为我们此时只做了一个工作: 将请求和响应进行序列化和反序列化,并且这个序列化和反序列化是我们自己的方案,未来我们可能会使用更成熟的方案。
#ifndef _PROTOCOL_HPP_
#define _PROTOCOL_HPP_
#include <iostream>
#include <string>
#include <cstring>
#include "Sock.hpp"
#define SPACE " "
#define SPACE_LEN (strlen(SPACE))
namespace Xq
{
class Request
{
public:
Request(){}
Request(int x, int y, char op)
:_x(x), _y(y) ,_op(op)
{}
// Request的序列化
// 约定为: "_x _op _y"
// eg: 10 + 20
std::string Serialize(void)
{
std::string data_stream = std::to_string(_x);
data_stream += SPACE;
data_stream += _op;
data_stream += SPACE;
data_stream += std::to_string(_y);
return data_stream;
}
// Request的反序列化
bool Deserialize(const std::string& data_stream)
{
size_t left = data_stream.find(SPACE);
if(left == std::string::npos) return false;
size_t right = data_stream.rfind(SPACE);
if(right == std::string::npos) return false;
_x = atoi(data_stream.substr(0,left).c_str());
_op = data_stream[left + SPACE_LEN];
_y = atoi(data_stream.substr(right + SPACE_LEN).c_str());
return true;
}
public:
int _x;
int _y;
char _op;
};
// result code
class Responce
{
public:
Responce() {}
Responce(int result, int code)
:_result(result), _code(code)
{}
// Responce的序列化
std::string Serialize()
{
std::string data_stream = std::to_string(_result);
data_stream += SPACE;
data_stream += std::to_string(_code);
return data_stream;
}
// Responce的反序列化
bool Deserialize(const std::string& data_stream)
{
size_t pos = data_stream.find(SPACE);
if(pos == std::string::npos) return false;
_result = atoi(data_stream.substr(0, pos).c_str());
_code = atoi(data_stream.substr(pos+1).c_str());
return true;
}
public:
int _result;
int _code; // 计算结果的状态码
};
// 接收数据
std::string Recv(int sock)
{
char buffer[1024] = {0};
ssize_t real_size = recv(sock, buffer, sizeof buffer, 0);
if(real_size == -1)
{
LogMessage(ERROR, "%s%d\n", strerror(errno));
}
return buffer;
}
// 发送数据
void Send(int sock, const std::string& info)
{
ssize_t real_size = send(sock, info.c_str(), info.size(), 0);
if(real_size == -1)
{
LogMessage(ERROR, "%s%d\n", strerror(errno));
}
}
}
#endif5.4. CalServer.cc
#include "TcpServer.hpp"
#include <unordered_map>
#include <signal.h>
void Usage(void)
{
printf("please ./server port\n");
exit(5);
}
using cal_func_t = std::function<int(int, int)>;
std::unordered_map<char, cal_func_t> table;
static void BuildCalTable(void)
{
table['+'] =[](int x, int y){return x + y;};
table['-'] =[](int x, int y){return x - y;};
table['*'] =[](int x, int y){return x * y;};
table['/'] =[](int x, int y){return x / y;};
table['%'] =[](int x, int y){return x % y;};
}
void calculate(int sock)
{
// 获得客户端序列化后发送的数据
std::string data_stream = Xq::Recv(sock);
// 因此我们需要反序列化, 得到结构化数据
Xq::Request data;
data.Deserialize(data_stream);
// 定义返回给客户端的计算结果
Xq::Responce ret_data(0, 0);
// 处理数据
if(data._op == '/' || data._op == '%')
{
// 非法情况
if(data._y == 0)
{
LogMessage(ERROR, "_y == 0, can not calculate\n");
ret_data._code = 1;
}
}
else
{
// 计算
ret_data._result = table[data._op](data._x, data._y);
}
// 计算完成
// 将Response数据序列化后返回给客户端
Xq::Send(sock, ret_data.Serialize());
LogMessage(DEBUG, "server send data to client success\n");
}
int main(int argc, char** argv)
{
if(argc != 2)
{
Usage();
}
signal(SIGPIPE, SIG_IGN);
uint16_t port = atoi(argv[1]);
// 网络功能
Xq::Server* server = new Xq::Server(port);
// 服务
server->BindServer(calculate);
// 加载处理表
BuildCalTable();
// 将网络功能和服务进行解耦
server->start();
delete server;
return 0;
}5.5. CalClient.cc
#include <memory>
#include "Protocol.hpp"
#include "Sock.hpp"
#include "Log.hpp"
void Usage(void)
{
std::cout << "Please usage ./client ip port \n";
}
int main(int argc, char** argv)
{
if(argc != 3)
{
Usage();
exit(1);
}
Xq::Sock sock;
sock.Socket();
// 客户端不需要绑定
// 但需要 connect 发起连接
std::string ip = argv[1];
uint16_t port = atoi(argv[2]);
sockaddr_in client_addr;
client_addr.sin_family = AF_INET;
client_addr.sin_port = htons(port);
inet_aton(ip.c_str(), &client_addr.sin_addr);
socklen_t addrlen = sizeof client_addr;
sock.Connect(&client_addr, &addrlen);
// 构造请求
//Xq::Request* request = new Xq::Request(10,20,'+');
//delete request;
int x, y;
char op;
std::cout << "please input x:> " ;
std::cin >> x;
std::cout << "please input y:> " ;
std::cin >> y;
std::cout << "please input op:> " ;
std::cin >> op;
std::unique_ptr<Xq::Request> ptr(new Xq::Request(x, y, op));
// 在这里不推荐直接发送结构化的数据
// 我们先将其序列化, 并发送给服务端
Xq::Send(sock._sock, ptr->Serialize());
LogMessage(DEBUG, "client send data to server success\n");
Xq::Responce responce;
std::string data_stream = Xq::Recv(sock._sock);
// 此时的data_stream 是序列化后的数据
// 需要我们将其反序列化
responce.Deserialize(data_stream);
std::cout << "result: " << responce._result << std::endl;
std::cout << "code: " << responce._code << std::endl;
LogMessage(DEBUG, "server deal with data, client gain success\n");
return 0;
}上面,我们实际上只是多做了一个工作 (较于以前的网络代码), 那就是用我们的方案实现序列化和反序列化。而这样的目的单纯的只是为了让我们理解序列化和反序列化的这个过程,这个过程对于理解网络通信、数据存储以及系统间交互非常重要。
但在实际的生产环境中,更多时候我们会使用已经成熟的、由专业团队开发和维护的序列化库或框架,因为这些方案经过了广泛的测试和优化,可以提供更高的性能、更好的稳定性,并且通常会考虑到各种不同的边界条件和特殊情况。
在进入下一个环节之前, 我们需要解决上面的一些潜在问题,即服务器经常遇到的一个问题:
当服务器正在向客户端写数据时,如果客户端关闭了连接或者不再读取数据,服务器端继续写数据就可能导致SIGPIPE信号被触发,从而导致服务器挂掉。为了解决这个问题,可以采取以下措施:
在编写服务器代码时,需要有严谨的逻辑判断,处理可能出现的异常情况。在写数据之前,应该先判断客户端连接的状态,如果连接已经关闭,则不再继续写数据,避免触发SIGPIPE信号。
服务器一般会忽略SIGPIPE信号 。这样在写数据时如果发生了SIGPIPE信号,服务器不会挂掉,而是可以捕获这个信号并做相应的处理。一种常见的做法是使用 signal 函数将SIGPIPE信号的处理动作设置为SIG_IGN,这样当写数据时发生SIGPIPE信号时,服务端不会终止,而是忽略该信号继续执行。
而上面 Protocol.hpp 中,对于一个 Request请求, 服务端和客户端知道 _x,_op,_y 分别是什么吗? 知道如何处理它们吗?
答案是:知道, 而这就是约定。 因此,约定不仅仅体现在数据的结构化成员,也包括了对数据的处理方式。
可是,这个网络计算器就到此结束了吗? 答案是, 远远不够, 其中还有很多潜在的问题。
6. 网络计算器 --- 更新版本
UDP是一种面向数据报的传输协议。在UDP通信中,发送方将数据封装成数据报(也称为UDP报文),然后通过网络发送给接收方。接收方通过 recvfrom 函数或类似的机制从网络中读取数据报。发送方发一个报文, 接收方 recvfrom 读的时候,就只会读到一个完整的报文,因此它是面向数据报的。
而我们知道, TCP是面向字节流的传输协议, 那么就有可能出现下面的情况:
发送方发送的数据可能会被接收方分成不同的片段接收,也可能多个发送的数据被一次性接收到;
那么问题就来了:
当服务端 (客户端) 在进行 recv 的时候, 怎么保证读到 buffer 里面的内容是一个完整完善的请求 ( 响应) 呢?
就上面的代码而言, 我们无法保证。
- TCP 和 UDP 我们称之为传输控制协议。
- 在TCP协议中,是存在发送和接收缓冲区的。
- send / write:你认为你是把数据发送到网络甚至是对方的主机中。 这种认识是错误的。
- send / write 只是把你自己在应用层定义的缓冲区拷贝到了 TCP协议中的发送缓冲区中;
- 而在 read / recv 时 ,你只是把TCP协议中的接收缓冲区中的数据拷贝到上层用户在应用层定义的缓冲区中。
而TCP中的发送和接收缓冲区的数据如何处理 (什么时候发、发多少、出错了怎么办等问题) ,这些问题并不是由应用层考虑的, 而是由传输控制协议 TCP决定的, 而这也正体现了传输控制这个特定。
因此, 对于上面我们的总结就是:
- IO类函数 (类似于 send / recv / write / read) 本质上都是拷贝函数。
- 在TCP协议中,发送数据的次数和接收数据的次数没有任何关系, 我们称之为面向字节流。
- TCP是一种面向字节流的协议,它将数据视为连续的字节流而不是分割成独立的消息或数据包。
因此,由于TCP 协议是面向字节流的, 为了保证每一次获取的数据是一个完整的请求 (响应),我们需要对协议 ( Protocol.hpp ) 做进一步定制。
而我们采取的策略就是:
- 消息长度前缀: 在通信协议中加入消息长度前缀,告诉接收方在接收到多少字节后可以认为是一个完整的消息。接收方根据消息长度来决定何时停止接收数据,并开始处理接收到的完整消息。
- 特定分隔符: 在消息的结尾添加特定的分隔符,例如换行符 \n,使接收方可以根据分隔符来确定消息的边界,从而区分不同的消息。
我们以 Request 请求数据为例:
class Request
{
//...
public:
int _x;
int _y;
char _op;
};假设, 某个请求数据为 10,20,'+', 数据经过序列化后变成字节流:
"10 + 20"
可是由于_x 和 _y 是变化的, 因此, 上面这个字符串的长度也是变化的,因此,我们使用长度length表示上面字节流的长度,例如:
"length10 + 20"
可是, 由于 _x 和 _y 是变化的,那么这个字节流的长度也是变化的,因此,这里的 length 你该如何判断呢?因此,我们添加特定字符表明长度,例如:
"length\r\n10 + 20\r\n"
此时, 我们就可以通过特定字符标识 length, 然后再用 length 标识这个字节流的长度,这样我们就可以判断 recv 时是否获得的是一个完整数据。
而这个完整数据我们可以理解为完整报文。 前面的 length\r\n 我们可以称之为报头信息,而真正要传输的信息就是报文的有效载荷。
具体到上面 "10+20"这个字节流,那么完整报文就是 "7\r\n10 + 20\r\n"
主要更新的文件就是: Protocol.hpp、CalServer.cc、CalClient.cc
6.1. Protocol.hpp
代码如下:
#ifndef _PROTOCOL_HPP_
#define _PROTOCOL_HPP_
#include <iostream>
#include <string>
#include <cstring>
#include "Sock.hpp"
#define SPACE " "
#define SPACE_LEN (strlen(SPACE))
#define SEP "\r\n"
#define SEP_LEN (strlen(SEP))
namespace Xq
{
class Request
{
public:
Request(){}
Request(int x, int y, char op)
:_x(x), _y(y) ,_op(op)
{}
// 序列化
// 约定为: "_x _op _y"
// eg: 10 + 20
std::string Serialize(void)
{
std::string data_stream = std::to_string(_x);
data_stream += SPACE;
data_stream += _op;
data_stream += SPACE;
data_stream += std::to_string(_y);
return data_stream;
}
// 反序列化
bool Deserialize(const std::string& data_stream)
{
size_t left = data_stream.find(SPACE);
if(left == std::string::npos) return false;
size_t right = data_stream.rfind(SPACE);
if(right == std::string::npos) return false;
_x = atoi(data_stream.substr(0,left).c_str());
_op = data_stream[left + SPACE_LEN];
_y = atoi(data_stream.substr(right + SPACE_LEN).c_str());
return true;
}
public:
int _x;
int _y;
char _op;
};
// result code
class Responce
{
public:
Responce() {}
Responce(int result, int code)
:_result(result), _code(code)
{}
std::string Serialize()
{
std::string data_stream = std::to_string(_result);
data_stream += SPACE;
data_stream += std::to_string(_code);
return data_stream;
}
bool Deserialize(const std::string& data_stream)
{
size_t pos = data_stream.find(SPACE);
if(pos == std::string::npos) return false;
_result = atoi(data_stream.substr(0, pos).c_str());
_code = atoi(data_stream.substr(pos+1).c_str());
return true;
}
public:
int _result;
int _code;
};
// recv 的数据全部放到out中
int Recv(int sock, std::string& out)
{
char buffer[1024] = {0};
ssize_t real_size = recv(sock, buffer, sizeof buffer, 0);
if(real_size > 0)
{
// recv 读取成功
// 但是无法保证读取了多少数据
// 因此我们全部添加到 out 中
buffer[real_size] = 0;
out += buffer;
return 0;
}
else if(real_size == 0)
{
// 写端退出
return 1;
}
else
{
// 读取出错
return -1;
}
}
void Send(int sock, const std::string& info)
{
ssize_t real_size = send(sock, info.c_str(), info.size(), 0);
if(real_size == -1)
{
LogMessage(ERROR, "%s%d\n", strerror(errno));
}
}
// Decode 对 out进行解析
// 确保可以获得一个完整报文
// 如果没有完整报文,就返回空
// 继续 Recv 数据
// 例如: length\r\n10 + 20\r\n
std::string Decode(std::string& out)
{
// step 1: 我们找这个特殊标识 "\r\n", 看是否存在
size_t pos = out.find(SEP);
// 如果不存在,那么说明当前的out没有完整的报文
// 因此返回空串即可
if(pos == std::string::npos)
{
return "";
}
// 此时的pos就是这个报文的有效载荷的长度
size_t len = atoi(out.substr(0, pos).c_str());
// 走到这里, 说明有可能存在完整的报文
// 我们需要由长度判定, 也就是length
if(out.size() - len - 2 * SEP_LEN >= 0)
{
// 此时就一定存在一个完整的报文
// 首先删除lenght\r\n
out.erase(0, pos + SEP_LEN);
// 有效载荷
std::string true_info = out.substr(0, len);
// 在删除10 + 20\r\n
out.erase(0, len + SEP_LEN);
return true_info;
}
else
{
// 说明此时没有完整的报文
// 返回空串
return "";
}
}
// 添加协议报头信息 (长度, 特殊字符)
void Encode(std::string &data_stream)
{
std::string len = std::to_string(data_stream.size());
len += SEP;
len += data_stream;
len += SEP;
data_stream = len;
}
}
#endif6.2. CalServer.cc
代码如下:
#include "TcpServer.hpp"
#include <unordered_map>
#include <signal.h>
void Usage(void)
{
printf("please ./server port\n");
exit(5);
}
using cal_func_t = std::function<int(int, int)>;
std::unordered_map<char, cal_func_t> table;
static void BuildCalTable(void)
{
table['+'] =[](int x, int y){return x + y;};
table['-'] =[](int x, int y){return x - y;};
table['*'] =[](int x, int y){return x * y;};
table['/'] =[](int x, int y){return x / y;};
table['%'] =[](int x, int y){return x % y;};
}
//void func(int sock)
//{
// std::cout << "sock: " << sock << " are you ready ?" << std::endl;
//}
void calculate(int sock)
{
// 服务端读取的信息全部存入all_info中
std::string all_info;
// 有效载荷
std::string data_stream;
while(true)
{
// 获得客户端序列化后发送的数据
int ret = Xq::Recv(sock, all_info);
if(ret == 1)
{
LogMessage(ERROR, "client exit\n");
break;
}
else if(ret == -1)
{
LogMessage(FATAL, "recv error\n");
exit(1);
}
else
{
// 对读取到的数据 all_info 进行解析
data_stream = Xq::Decode(all_info);
if(data_stream.empty())
{
// 如果返回值是空串, 那么就说明没有完整的报文
continue;
}
else
{
// 走到这里, data_stream 就是一个完整的有效载荷
break;
}
}
}
// 因此我们需要反序列化, 得到结构化数据
Xq::Request data;
data.Deserialize(data_stream);
// 定义返回给客户端的计算结果
Xq::Responce ret_data(0, 0);
// 处理数据
if(data._op == '/')
{
// 非法情况
if(data._y == 0)
ret_data._code = 1;
}
if(data._op == '%')
{
// 非法情况
if(data._y == 0)
ret_data._code = 2;
}
if(data._y != 0)
{
// 计算
ret_data._result = table[data._op](data._x, data._y);
LogMessage(NORMAL, "[%d %c %d = ?]:[%d, %d]\n", data._x, data._op,data._y,\
ret_data._result, ret_data._code);
}
// 计算完成
// 将Response数据序列化, 得到初始化字节流数据
// "_result _code"
std::string Responce_data_stream = ret_data.Serialize();
// 添加协议报头, 让其处于 "lenght\r\n_result _code\r\n"
Xq::Encode(Responce_data_stream);
// 添加报头信息后, 再进行发送
Xq::Send(sock, Responce_data_stream);
if(ret_data._code == 1)
{
LogMessage(ERROR, "除0错误, code: %d\n", ret_data._code);
}
else if(ret_data._code == 2)
{
LogMessage(ERROR, "模0错误, code: %d\n", ret_data._code);
}
else
{
LogMessage(DEBUG, "deal with data success\n");
}
}
int main(int argc, char** argv)
{
if(argc != 2)
{
Usage();
}
signal(SIGPIPE, SIG_IGN);
uint16_t port = atoi(argv[1]);
// 网络功能
Xq::Server* server = new Xq::Server(port);
// 服务
server->BindServer(calculate);
// 加载处理表
BuildCalTable();
// 将网络功能和服务进行解耦
server->start();
delete server;
return 0;
}6.3. CalClient.cc
代码如下:
#include <memory>
#include "Protocol.hpp"
#include "Sock.hpp"
#include "Log.hpp"
void Usage(void)
{
std::cout << "Please usage ./client ip port \n";
}
int main(int argc, char** argv)
{
if(argc != 3)
{
Usage();
exit(1);
}
Xq::Sock sock;
sock.Socket();
// 客户端不需要绑定
// 但需要 connect 发起连接
std::string ip = argv[1];
uint16_t port = atoi(argv[2]);
sockaddr_in client_addr;
client_addr.sin_family = AF_INET;
client_addr.sin_port = htons(port);
inet_aton(ip.c_str(), &client_addr.sin_addr);
socklen_t addrlen = sizeof client_addr;
sock.Connect(&client_addr, &addrlen);
// 构造请求
//Xq::Request* request = new Xq::Request(10,20,'+');
//delete request;
int x, y;
char op;
while(true)
{
std::cout << "notice: operator(+ - * / %) " << std::endl;
std::cout << "please input (eg:1 + 2):> " ;
std::cin >> x >> op >> y;
if (op != '+' && op != '-'
&& op != '*' && op != '/'
&& op != '%')
{
std::cout << "unknown operatror, resume load\n";
continue;
}
break;
}
std::unique_ptr<Xq::Request> ptr(new Xq::Request(x, y, op));
// 在这里不推荐直接发送结构化的数据
// 我们先将其序列化, 并发送给服务端
std::string data_stream = ptr->Serialize();
// 添加报头信息(长度信息以及特殊字符)
Xq::Encode(data_stream);
// 添加后, 在发送给服务端
Xq::Send(sock._sock, data_stream);
LogMessage(DEBUG, "client send data to server success\n");
Xq::Responce responce;
// 读到的数据都放入all_data中
std::string all_data;
// 有效载荷
std::string true_data;
while(true)
{
int ret = Xq::Recv(sock._sock, all_data);
if(ret == 1)
{
LogMessage(ERROR, "server exit\n");
break;
}
else if(ret == -1)
{
LogMessage(FATAL, "recv error\n");
exit(1);
}
else
{
// 读取成功
true_data = Xq::Decode(all_data);
if(true_data.empty())
continue;
else
break;
}
}
// 此时的true_stream 是报文的有效载荷
// 需要我们将其反序列化
responce.Deserialize(true_data);
if(responce._code == 0)
printf("[result: %d, code: %d] success\n", responce._result, responce._code);
else if(responce._code == 1)
printf("除0错误\n");
else if(responce._code == 2)
printf("模0错误\n");
return 0;
}7. 守护进程
7.1. 终端 && Shell
- 终端(Terminal)是用户与计算机系统进行交互的界面,通常提供一个命令行界面(CLI),用户可以通过输入命令来与系统进行通信和执行各种操作。终端允许用户输入命令、查看输出结果,并与系统进行交互。
- Shell:Shell 是用户与操作系统内核之间的接口 (在 Linux 下默认是bash) ,它是一个命令解释器,负责解释和执行用户输入的命令。当用户在终端中输入命令时,这些命令实际上是由 bash 解释执行的。bash 提供了各种功能,包括执行命令、管理文件系统、进行进程控制等。
- 终端和Shell之间的联系在于,终端提供了一个用户界面,用户可以在其中输入命令;而Shell则是解释和执行这些命令的程序。终端通过Shell来实现用户与操作系统之间的交互。通常情况下,终端会启动一个Shell进程,用户在终端中输入的命令都会由这个Shell进程来解释和执行。
7.2. 什么叫做前台进程呢?
在 Unix/Linux 系统中,前台进程通常是指当前用户正在与之交互的进程。
前台进程通常与终端或控制台相关联。这些进程能够接收用户的输入,并且通常会将输出显示在用户的屏幕上。
因此大部分情况下,在一个终端窗口中运行的 shell (bash) 本身就是前台进程。
7.3. 什么叫做后台进程呢?
后台进程是在后台运行的进程,通常不与用户直接交互,而是在后台默默地执行任务。
后台进程有以下特征:
- 不占用终端: 后台进程通常不会占用用户当前正在使用的终端,用户可以在终端中输入命令而不会被后台进程打断。
- 不需要用户交互: 后台进程通常是不需要用户交互的,它们可能是系统服务、守护进程或者在用户注销后仍然在后台运行的任务。
- 通过特殊字符表示: 在 Unix/Linux 系统中,可以使用特殊的字符 '&' 将一个命令或程序放到后台运行 (例如 ./a.out &,其就是一个后台进程),这样它就成为了后台进程。
- 常驻后台: 后台进程通常是长时间运行的,它们可能会在系统启动时启动并持续运行,直到系统关闭或被手动终止。
7.4. 前台进程 && 后台进程
一个 xshell 登录会话中,一般情况下,只有一个前台进程和多个后台进程。
- 一个前台进程:这意味着在任何给定的时刻,只有一个前台进程能够直接接收用户输入并与用户进行交互。
- 多个后台进程:用户可以在一个 xshell 登录会话中启动多个后台任务,这些后台进程可以并行地执行任务,而不会阻碍用户的交互。
7.5. 进程组ID --- PGID
进程组ID(Process Group ID,简称PGID)是在Unix/Linux系统中用来组织和管理一组相关进程的标识符。进程组是由一个或多个进程组成的集合,这些进程通常被视为一个单独的单位,它们共享同一个控制终端,并且可以接收相同的信号。
为了方便描述, 我们以下面这条命令举例:
sleep 10000 | sleep 20000 | sleep 30000现象如下:
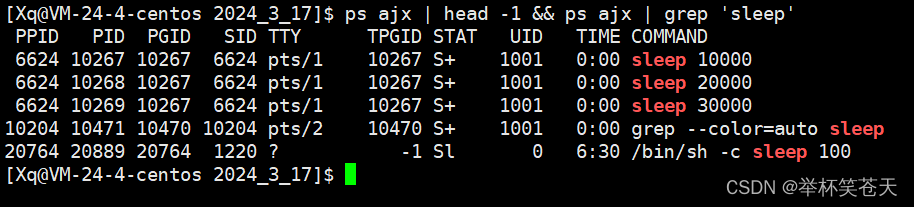
可以发现:
此时这三个 sleep 进程的 PGID是一样的, 即这三个进程同属一个进程组;
同时这个进程组 ID 是第一个进程的PID, 换言之, 进程组的组长ID一般情况下是第一个进程的PID。
其次,我们发现,这三个进程的PPID是一致的, 那么这个PPID是谁呢? 如下:

可以发现,这个进程就是Bash。
- 因此,在命令行中,同时用匿名管道启动多个进程, 而这多个进程是兄弟关系, 父进程都是 bash, 故这些兄弟进程可以通过匿名管道进行通信。
- 而同时被创建的多个进程可以成为一个进程组 (PGID) 的概念,组长一般是第一个进程。
7.6. 会话ID --- SID
会话ID(Session ID,简称SID)是在Unix/Linux系统中用来标识一个登录会话的标识符。而 "会话" 通常指的是用户从登录到注销期间的整个交互过程,包括可能的多个终端或窗口。在这个过程中,会话ID是唯一的,用于区分不同的会话。
在Unix/Linux系统中,会话的概念是由登录Shell来管理的。当用户登录系统时,系统会为该用户创建一个新的会话,并分配一个唯一的会话ID(SID)。这个SID会一直伴随着整个会话过程,直到用户最终注销或退出登录。
一般情况下, 用户登录Shell后, 系统会自动创建一个新的会话, 这个会话中默认会有一个默认的Shell (例如 bash) 和 一个终端, 随后用户在该终端下启动的所有进程,无论是前台还是后台,都会被分配给该会话,因此它们的会话ID(SID)是一致的。

同时,我们发现, bash 是自成一组的, 即 bash 的 PGID 就是它的PID;
而在该终端下启动的进程它们是自成一组的。 如图所示:
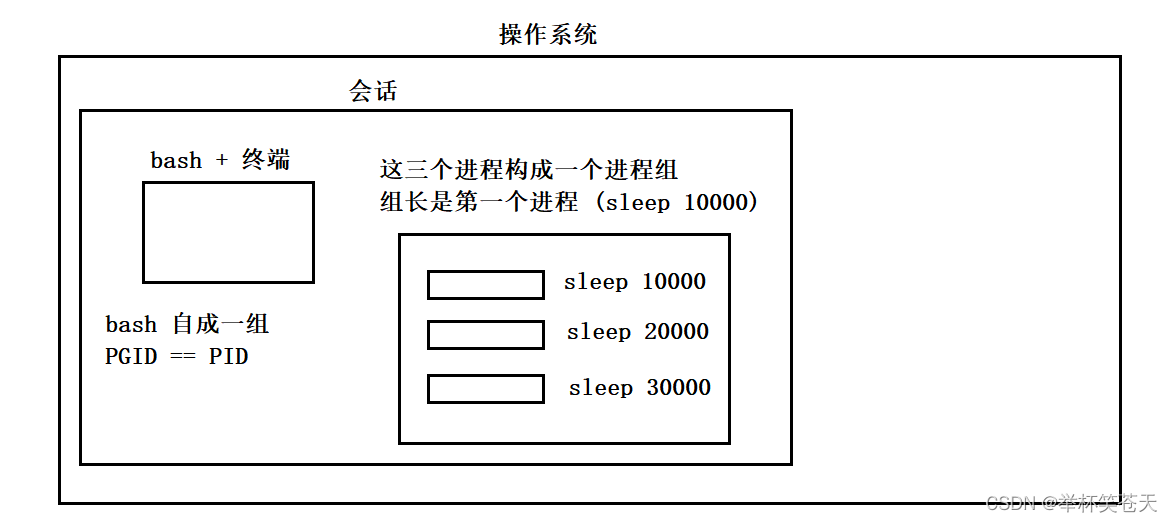
在一个会话中,可以只有终端和bash而没有其他进程或服务运行。
上面我们讨论的是用户登录时, 操作系统会为我们创建一个会话,然后创建bash;
可是, 用户退出登录了, 如何处理呢?
理论上,用户退出登录时,会话会被释放掉,这通常会导致会话中的所有相关进程都被终止。在大多数情况下,当用户退出登录时,操作系统会发送信号给与该会话相关的进程,通知它们会话即将结束,并要求它们进行清理和终止。这样做是为了确保用户退出后不会有残留的进程继续在系统中运行。
可是,对于服务器而言,如果会话被关闭,就导致该服务器退出了, 这是不是不太合理啊。
因此, 我们需要一种策略,当这个会话退出时,不要让服务器挂掉, 而是让服务器继续运行, 因此我们提出了守护进程, 即将服务器守护进程化。
7.7. 守护进程
自成一个会话的进程, 我们称之为守护进程。
那么如何将一个进程守护进程化呢?
不就是将该进程变成一个自成一个会话的进程吗?
那么如何将一个进程变成自成会话呢?调用 setsid 系统调用。
7.7.1. setsid 系统调用
NAME
setsid - creates a session and sets the process group ID
SYNOPSIS
#include <unistd.h>
pid_t setsid(void);
RETURN VALUE
On success, the (new) session ID of the calling process is returned.
On error, (pid_t) -1 is returned, and errno is set to indicate the error.注意: setsid 要成功被调用, 必须保证当前进程不是进程组的组长。
那么如何保证该进程不是组长呢?
答案是:首先,通过fork() 创建子进程,在调用 setsid 之前,先让父进程结束,这样子进程就不会是进程组的组长。然后子进程调用 setsid 就能成功创建一个新的会话。
7.7.2. 如何在Linux在正确编写一个进程守护进程化的代码?
Linux系统中已经了一个成熟的方案, daemon 调用,这是一个创建守护进程的函数,通常用于Linux系统中。该函数会将当前进程变成一个守护进程。该函数原型如下:
int daemon(int nochdir, int noclose);
- nochdir:如果该参数为非零值,则表示在调用 daemon 函数后,进程的当前工作目录不会被改变,即进程不会切换到根目录 /。如果该参数为零,则表示进程的当前工作目录会被切换到根目录。
- noclose:如果该参数为非零值,则表示在调用 daemon 函数后,进程的标准输入、标准输出和标准错误不会被关闭。如果该参数为零,则表示这些文件描述符会被关闭,进程不再与终端关联。
通常情况下,调用 daemon(0, 0) 可以将当前进程变成一个守护进程,并且将工作目录切换到根目录,关闭标准输入、输出和错误。
但是,在很多的项目中, 使用的并不多, 我们更趋向于自己定制一个函数,让进程变成守护进程。 因此,实现逻辑如下:
- 忽略信号, 诸如 SIGCHLD、SIGPIPE,不要因为某些特殊信号导致服务器挂了;
- 不要让自己成为进程组的组长, fork() 创建子进程;
- 调用 setsid, 让子进程自成一个会话;
- 标准输入、标准输出、标准错误的重定向 (通过 dup2 系统调用)。守护进程不能直接向显示器打印消息 (守护进程自成一个会话 ),一旦打印,守护进程会被阻塞;
- 通常情况下,守护进程会将标准输入、标准输出和标准错误重定向到 /dev/null,向dev/null 写入的内容默认会被全部丢弃,如果从 dev/null 文件读内容,它不会阻塞你,并且什么内容都读不到。
- 由于我们已经将标准输入、标准输出、标准错误都重定向到了 /dev/null 文件中,因此服务器不可以再用诸如std::cout,std::cerr,printf等,因为它们写入的内容都会被丢弃,故服务器端写日志,就需要向文件中写入,例如通过 fprintf 等接口。
7.7.3. Daemon.hpp
代码实现如下:
#ifndef _DAEMON_HPP_
#define _DAEMON_HPP_
#include <iostream>
#include <cstring>
#include <signal.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include "Log.hpp"
namespace Xq
{
void Daemon(void)
{
// step 1
signal(SIGCHLD, SIG_IGN);
signal(SIGPIPE, SIG_IGN);
// step 2
if(fork() > 0) exit(0);
// step 3
int sid = setsid();
if(sid == -1)
{
LogMessage(FATAL, "%s%d\n",strerror(errno));
exit(1);
}
// step 4
int fd = open("/dev/null", O_WRONLY | O_RDONLY);
if(fd == -1)
{
LogMessage(FATAL, "%s%d\n", strerror(errno));
exit(2);
}
else
{
dup2(fd, 0);
dup2(fd, 1);
dup2(fd, 2);
close(fd);
}
// Daemon done
}
}
#endif7.7.4. CalServer.cc
更改后的服务端, 让服务端调用我们实现的Daemon,让服务端进程守护进程化:
#include "TcpServer.hpp"
#include "Daemon.hpp"
#include <unordered_map>
// 省略
int main(int argc, char** argv)
{
if(argc != 2)
{
Usage();
}
uint16_t port = atoi(argv[1]);
// 网络功能
Xq::Server* server = new Xq::Server(port);
// 服务
server->BindServer(calculate);
// 加载处理表
BuildCalTable();
// 将进程守护进程化
Xq::Daemon();
// 将网络功能和服务进行解耦
server->start();
delete server;
return 0;
}7.7.5. Log.hpp
此时我们的日志就需要向特定文件写入了,代码如下:
#pragma once
#include "Date.hpp"
#include <iostream>
#include <map>
#include <string>
#include <cstdarg>
#define LOG_SIZE 1024
// 日志等级
enum Level
{
DEBUG, // DEBUG信息
NORMAL, // 正常
WARNING, // 警告
ERROR, // 错误
FATAL // 致命
};
const char* pathname = "./log.txt";
void LogMessage(int level, const char* format, ...)
{
// 如果想打印DUBUG信息, 那么需要定义DUBUG_SHOW (命令行定义, -D)
#ifndef DEBUG_SHOW
if(level == DEBUG)
return ;
#endif
std::map<int, std::string> level_map;
level_map[0] = "DEBUG";
level_map[1] = "NORAML";
level_map[2] = "WARNING";
level_map[3] = "ERROR";
level_map[4] = "FATAL";
std::string info;
va_list ap;
va_start(ap, format);
char stdbuffer[LOG_SIZE] = {0}; // 标准部分 (日志等级、日期、时间)
snprintf(stdbuffer, LOG_SIZE, "[%s],[%s],[%s] ", level_map[level].c_str(), Xq::Date().get_date().c_str(), Xq::Time().get_time().c_str());
info += stdbuffer;
char logbuffer[LOG_SIZE] = {0}; // 用户自定义部分
vsnprintf(logbuffer, LOG_SIZE, format, ap);
info += logbuffer;
FILE* fp = fopen(pathname, "a");
fprintf(fp, "%s", info.c_str());
fclose(fp);
va_end(ap);
}实验现象如下:

可以看到,此时这个服务端的 PID == PGID == SID, 自成进程组组, 自成会话, 这就是一个守护进程。
并且我们发现,此时的服务端的进程的父进程的ID是谁? 1号进程, 也就是操作系统。
换言之, 守护进程就是孤儿进程中的一种。
孤儿进程可能属于某个会话, 但是守护进程自成会话。
此时这个服务就可以在公网对外提供服务了,如果要给别人使用,我们只需要将客户端分发给所有人,让别人安装客户端,通过客户端就可以访问我的服务了。
这就是我们在日常生活中使用的服务在后端的工作模式,服务端以守护进程的方式运行。
8. 总结
如上就是我们自己写的一个应用层代码,目前我们解决了三个问题:
- 序列化和反序列化;
- 定制了自己的协议;
- 将我们的服务守护进程化, 让它变成一个网络服务;