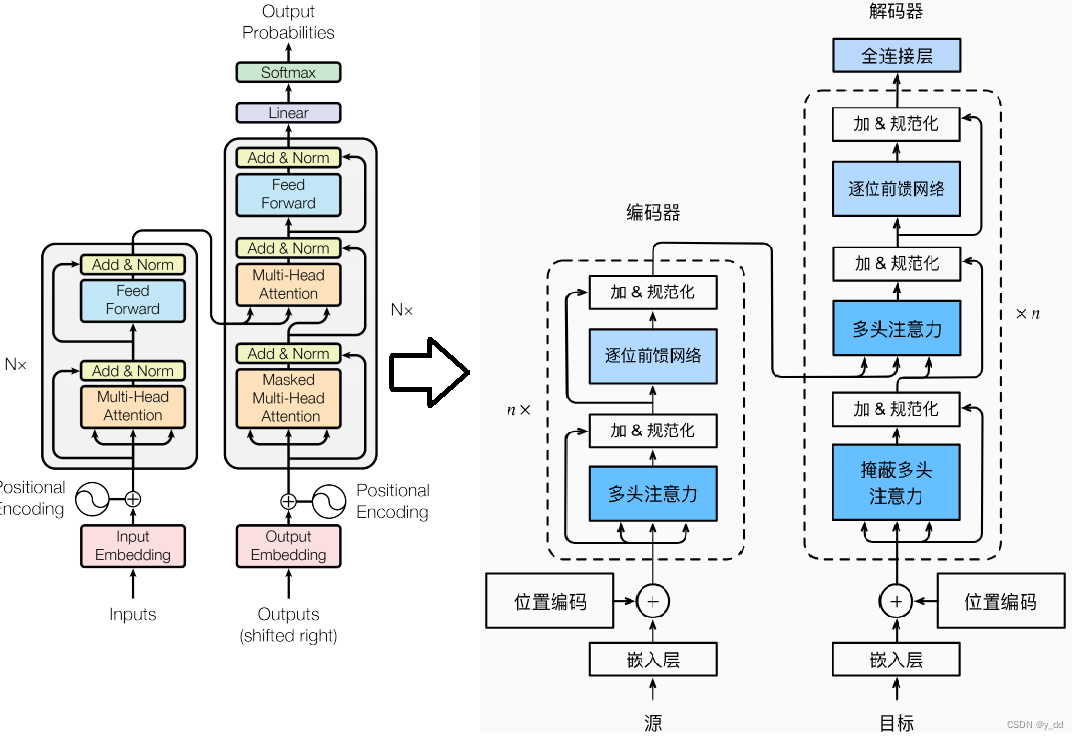
一:了解背景和动机
阅读Transformer论文:
阅读原始的Transformer论文:“Attention is All You Need”,由Vaswani等人于2017年提出,是Transformer模型的开创性工作。

二:理解基本构建块
注意力机制:
Transformer的核心在于自注意力机制。它允许模型在处理每个词时考虑句子中的所有其他词,从而有效捕获长距离依赖关系。这是通过计算查询(Q)、键(K)和值(V)之间的关系实现的,其中注意力分数是通过以下公式计算得出的:
Attention(Q, K, V) = softmax ( QK T d k ) V \text{Attention(Q, K, V)} = \text{softmax}\left(\frac{\text{QK}^T}{\sqrt{d_k}}\right)\text{V} Attention(Q, K, V)=softmax(dkQKT)V

位置编码:
在Transformer模型中,由于自注意力机制并不关注输入序列中元素的顺序,为了使模型能够处理序列数据的顺序信息,引入了位置编码(Positional Encoding)。
位置编码的主要目的是为模型提供一些关于输入序列中元素相对位置的信息。由于Transformer没有内置的对序列顺序的理解,位置编码的添加有助于模型区分不同位置的词或输入。位置编码通常是通过在输入嵌入向量中添加一个与位置相关的向量来实现的。这个向量的设计通常遵循一些规律,以便模型能够通过学习位置编码来理解输入序列的顺序。一种常见的方式是使用正弦和余弦函数:
位置 p o s pos pos 和嵌入维度 i i i 之间的位置编码 P E ( p o s , 2 i ) PE(pos, 2i) PE(pos,2i)和 P E ( p o s , 2 i + 1 ) PE(pos, 2i+1) PE(pos,2i+1) 分别计算如下:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d ) P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d ) PE(pos, 2i) = \sin\left(\frac{ {pos}}{ {10000^{2i/d}}}\right) \\ PE(pos, 2i+1) = \cos\left(\frac{ {pos}}{ {10000^{2i/d}}}\right) PE(pos,2i)=sin(100002i/dpos)PE(pos,2i+1)=cos(100002i/dpos)
其中,(pos) 是位置,(i) 是维度的索引,(d) 是嵌入的维度。这样设计的位置编码能够使得不同位置之间的编码有一些规律性的差异,以便模型学习到序列的顺序信息。在实际实现中,这个位置编码会被直接添加到输入嵌入向量中。这样,通过学习嵌入向量和位置编码之间的权重,模型就可以同时利用嵌入向量的语义信息和位置编码的顺序信息。以下是一个简化的Python代码示例,演示了如何生成位置编码:
import torch import torch.nn as nn import math class PositionalEncoding(nn.Module): def __init__(self, d_model, max_len=512): super(PositionalEncoding, self).__init__() self.encoding = torch.zeros(max_len, d_model) position = torch.arange(0, max_len).unsqueeze(1).float() div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)) self.encoding[:, 0::2] = torch.sin(position * div_term) self.encoding[:, 1::2] = torch.cos(position * div_term) self.encoding = self.encoding.unsqueeze(0) def forward(self, x): return x + self.encoding[:, :x.size(1)].detach() # Example usage d_model = 512 max_len = 100 positional_encoding = PositionalEncoding(d_model, max_len) # Assuming input is a tensor of shape (batch_size, sequence_length, d_model) input_sequence = torch.rand((32, 50, d_model)) output_sequence = positional_encoding(input_sequence)这个示例中,
PositionalEncoding模块可以添加到Transformer的输入嵌入中。你可以根据实际任务和模型的需要调整嵌入维度和序列的最大长度。
三:学习Transformer模型的结构
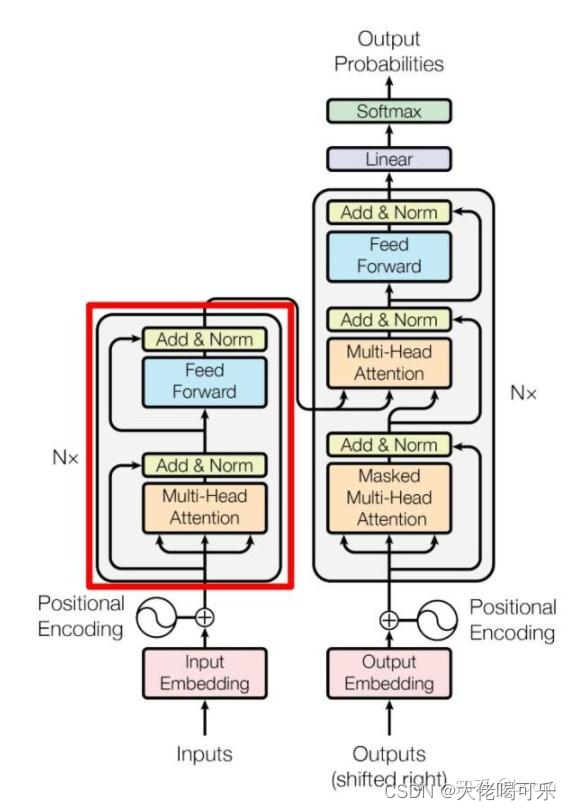
Encoder和Decoder结构:
- 理解Transformer模型的整体结构,包括Encoder和Decoder。了解Encoder中多头注意力(Multi-Head Attention)和前馈神经网络(Feedforward Network)的作用,以及Decoder中的掩码多头注意力。
Encoder结构:
- 多层自注意力机制(Multi-Head Self Attention):
- 每个注意力头学习不同的注意力表示,从而捕捉输入序列中不同位置的信息。
- 每个注意力头的输出通过线性层进行变换和组合。
- 前馈神经网络(Feedforward Neural Network):
- 每个注意力头的输出通过一个全连接前馈神经网络进行非线性映射。
- 层归一化(Layer Normalization)和残差连接(Residual Connection):
- 在每个子层(自注意力和前馈神经网络)的输出后都应用层归一化和残差连接。
- 这有助于梯度的流动和训练稳定性。
Decoder结构:
- 多层自注意力机制(Multi-Head Self Attention):
- 类似于Encoder,但在Decoder中,自注意力机制要注意到输入序列和输出序列的不同位置。
- 多层编码-解码注意力机制(Multi-Head Encoder-Decoder Attention):
- 将Encoder的输出用作Query,将Decoder的自注意力输出用作Key和Value。这允许Decoder关注输入序列的不同部分。
- 前馈神经网络(Feedforward Neural Network):
- 与Encoder中的结构类似,用于处理解码器的注意力输出。
- 层归一化(Layer Normalization)和残差连接(Residual Connection):
- 同样,在每个子层后应用层归一化和残差连接。
Layer Normalization 和残差连接:
- 学习如何在Transformer的层中使用Layer Normalization和残差连接。
1. Layer Normalization(层归一化):
层归一化是一种用于神经网络中的归一化技术,其目的是减少内部协变量转移(Internal Covariate Shift)。在每个训练小批量上,层归一化对每个特征进行归一化,使其均值为零,标准差为一。
在Transformer中,Layer Normalization通常在每个子层的输出上应用,例如自注意力层或前馈神经网络层。其数学表达式如下:
L a y e r N o r m ( x ) = γ ( ( x − μ ) / σ ) + β LayerNorm(x)=γ((x−μ)/σ)+β LayerNorm(x)=γ((x−μ)/σ)+β
其中,x 是输入张量,μ 和 σ 分别是其均值和标准差,γ 和 β 是可学习的缩放和平移参数。2. 残差连接(Residual Connection):
残差连接是一种通过将输入直接添加到输出上的机制,用于解决梯度消失问题。在Transformer的每个子层的输出后都使用了残差连接。其数学表达式如下:
O u t p u t = I n p u t + S u b l a y e r ( I n p u t ) Output=Input+Sublayer(Input) Output=Input+Sublayer(Input)
其中,Sublayer(⋅) 是子层的变换,可以是自注意力、编码-解码注意力或前馈神经网络等。
四:使用现有的实现进行实践
PyTorch或TensorFlow实现:
- 使用PyTorch或TensorFlow,了解如何实现一个简单的Transformer模型。可以参考开源实现或教程。
import torch import torch.nn as nn import torch.nn.functional as F class MultiHeadAttention(nn.Module): def __init__(self, d_model, num_heads): super(MultiHeadAttention, self).__init__() self.d_model = d_model self.num_heads = num_heads self.Q = nn.Linear(d_model, d_model) self.K = nn.Linear(d_model, d_model) self.V = nn.Linear(d_model, d_model) self.fc_out = nn.Linear(d_model, d_model) def forward(self, Q, K, V, mask): # Q, K, V: (batch_size, seq_len, d_model) Q = self.Q(Q) K = self.K(K) V = self.V(V) Q = self.split_heads(Q) K = self.split_heads(K) V = self.split_heads(V) scores = torch.matmul(Q, K.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.d_model, dtype=torch.float32)) if mask is not None: scores = scores.masked_fill(mask == 0, float("-inf")) attention = F.softmax(scores, dim=-1) x = torch.matmul(attention, V) x = self.combine_heads(x) x = self.fc_out(x) return x def split_heads(self, x): return x.view(x.size(0), -1, self.num_heads, self.d_model // self.num_heads).transpose(1, 2) def combine_heads(self, x): return x.transpose(1, 2).contiguous().view(x.size(0), -1, self.num_heads * (self.d_model // self.num_heads)) class PositionwiseFeedforward(nn.Module): def __init__(self, d_model, d_ff, dropout=0.1): super(PositionwiseFeedforward, self).__init__() self.linear1 = nn.Linear(d_model, d_ff) self.dropout = nn.Dropout(dropout) self.linear2 = nn.Linear(d_ff, d_model) def forward(self, x): x = F.relu(self.linear1(x)) x = self.dropout(x) x = self.linear2(x) return x class PositionalEncoding(nn.Module): def __init__(self, d_model, max_len=512): super(PositionalEncoding, self).__init__() self.encoding = torch.zeros(max_len, d_model) position = torch.arange(0, max_len).unsqueeze(1).float() div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)) self.encoding[:, 0::2] = torch.sin(position * div_term) self.encoding[:, 1::2] = torch.cos(position * div_term) self.encoding = self.encoding.unsqueeze(0) def forward(self, x): return x + self.encoding[:, :x.size(1)].detach() class TransformerEncoderLayer(nn.Module): def __init__(self, d_model, num_heads, d_ff, dropout=0.1): super(TransformerEncoderLayer, self).__init__() self.self_attention = MultiHeadAttention(d_model, num_heads) self.feedforward = PositionwiseFeedforward(d_model, d_ff, dropout) self.layer_norm1 = nn.LayerNorm(d_model) self.layer_norm2 = nn.LayerNorm(d_model) self.dropout = nn.Dropout(dropout) def forward(self, x, mask): attention_output = self.self_attention(x, x, x, mask) x = x + self.dropout(attention_output) x = self.layer_norm1(x) feedforward_output = self.feedforward(x) x = x + self.dropout(feedforward_output) x = self.layer_norm2(x) return x class TransformerEncoder(nn.Module): def __init__(self, vocab_size, d_model, num_heads, d_ff, num_layers, max_len=512, dropout=0.1): super(TransformerEncoder, self).__init__() self.embedding = nn.Embedding(vocab_size, d_model) self.positional_encoding = PositionalEncoding(d_model, max_len) self.layers = nn.ModuleList([ TransformerEncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers) ]) def forward(self, x, mask): x = self.embedding(x) x = self.positional_encoding(x) for layer in self.layers: x = layer(x, mask) return x class TransformerDecoderLayer(nn.Module): def __init__(self, d_model, num_heads, d_ff, dropout=0.1): super(TransformerDecoderLayer, self).__init__() self.self_attention = MultiHeadAttention(d_model, num_heads) self.encoder_decoder_attention = MultiHeadAttention(d_model, num_heads) self.feedforward = PositionwiseFeedforward(d_model, d_ff, dropout) self.layer_norm1 = nn.LayerNorm(d_model) self.layer_norm2 = nn.LayerNorm(d_model) self.layer_norm3 = nn.LayerNorm(d_model) self.dropout = nn.Dropout(dropout) def forward(self, x, encoder_output, src_mask, tgt_mask): attention_output = self.self_attention(x, x, x, tgt_mask) x = x + self.dropout(attention_output) x = self.layer_norm1(x) encoder_attention_output = self.encoder_decoder_attention(x, encoder_output, encoder_output, src_mask) x = x + self.dropout(encoder_attention_output) x = self.layer_norm2(x) feedforward_output = self.feedforward(x) x = x + self.dropout(feedforward_output) x = self.layer_norm3(x) return x class TransformerDecoder(nn.Module): def __init__(self, vocab_size, d_model, num_heads, d_ff, num_layers, max_len=512, dropout=0.1): super(TransformerDecoder, self).__init__() self.embedding = nn.Embedding(vocab_size, d_model) self.positional_encoding = PositionalEncoding(d_model, max_len) self.layers = nn.ModuleList([ TransformerDecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers) ]) self.fc_out = nn.Linear(d_model, vocab_size) def forward(self, x, encoder_output, src_mask, tgt_mask): x = self.embedding(x) x = self.positional_encoding(x) for layer in self.layers: x = layer(x, encoder_output, src_mask, tgt_mask) x = self.fc_out(x) return x class Transformer(nn.Module): def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, d_ff, num_layers, max_len=512, dropout=0.1): super(Transformer, self).__init__() self.encoder = TransformerEncoder(src_vocab_size, d_model, num_heads, d_ff, num_layers, max_len, dropout) self.decoder = TransformerDecoder(tgt_vocab_size, d_model, num_heads, d_ff, num_layers, max_len, dropout) def forward(self, src_input, tgt_input, src_mask, tgt_mask): encoder_output = self.encoder(src_input, src_mask) decoder_output = self.decoder(tgt_input, encoder_output, src_mask, tgt_mask) return decoder_output # Example usage: src_vocab_size = 1000 tgt_vocab_size = 1000 d_model = 512 num_heads = 8 d_ff = 2048 num_layers = 6 max_len = 100 dropout = 0.1 model = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, d_ff, num_layers, max_len, dropout)
五:深入细节
超参数调整:
- 学习调整Transformer模型的超参数,包括学习率、层数、隐藏单元数等。
更深入的理解多头注意力:
- 了解多头注意力是如何工作的,以及它如何在不同的子空间上学到不同的表示。
多头注意力机制的工作原理:
考虑一个输入序列 X X X,通过线性变换分别生成 Q u e r y ( Q ) Query(Q) Query(Q)、 K e y ( K ) Key(K) Key(K)和 V a l u e ( V ) Value(V) Value(V)的表示。对于每个注意力头 i i i,通过计算注意力分数并对Value进行加权,得到头 i i i 的输出 O i O_i Oi。
多头注意力的输出 O O O 是所有注意力头输出的拼接:
O = C o n c a t ( O 1 , O 2 , . . . , O h ) O=Concat(O_1,O_2,...,O_h) O=Concat(O1,O2,...,Oh)
其中, h ℎ h 是注意力头的数量。学习不同表示的子空间:
每个注意力头都有独立的权重矩阵 ( W i Q , W i K , W i V ) (W_i^Q,W_i^K,W_i^V) (WiQ,WiK,WiV),这意味着每个头可以学到不同的表示。这种独立性使得每个头都能够关注输入序列的不同部分,捕捉不同方面的信息。
举例来说,考虑一个翻译任务,输入是一个包含动词的句子。不同的注意力头可以分别关注主语、宾语、谓语等不同的语法成分,从而更好地捕捉句子的语法结构。
六:应用到实际任务
语言建模或翻译任务:
- 尝试将学到的Transformer模型应用于语言建模或翻译任务。使用开源的语料库和模型预训练,然后微调模型以适应你的任务。
import torch import torch.nn as nn import torch.optim as optim from torchtext.data import Field, BucketIterator from torchtext.datasets import Multi30k from torch.nn import Transformer # 设置随机种子以保证可重复性 torch.manual_seed(42) # 定义Field对象 SRC = Field(tokenize='spacy', tokenizer_language='en', init_token='<sos>', eos_token='<eos>', lower=True) TRG = Field(tokenize='spacy', tokenizer_language='fr', init_token='<sos>', eos_token='<eos>', lower=True) # 加载Multi30k数据集 train_data, valid_data, test_data = Multi30k.splits(exts=('.en', '.fr'), fields=(SRC, TRG)) # 构建词汇表 SRC.build_vocab(train_data, min_freq=2) TRG.build_vocab(train_data, min_freq=2) # 定义Transformer模型 class TransformerModel(nn.Module): def __init__(self, src_vocab_size, trg_vocab_size, d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6): super(TransformerModel, self).__init__() self.embedding = nn.Embedding(src_vocab_size, d_model) self.transformer = Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers) self.fc = nn.Linear(d_model, trg_vocab_size) def forward(self, src, trg): src = self.embedding(src) trg = self.embedding(trg) output = self.transformer(src, trg) output = self.fc(output) return output # 初始化模型和优化器 model = TransformerModel(len(SRC.vocab), len(TRG.vocab)) optimizer = optim.Adam(model.parameters(), lr=0.001) criterion = nn.CrossEntropyLoss() # 定义训练函数 def train(model, iterator, optimizer, criterion): model.train() for batch in iterator: src = batch.src trg = batch.trg optimizer.zero_grad() output = model(src, trg) output = output.view(-1, output.shape[-1]) trg = trg.view(-1) loss = criterion(output, trg) loss.backward() optimizer.step() # 构建BucketIterator BATCH_SIZE = 32 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') train_iterator, valid_iterator, test_iterator = BucketIterator.splits( (train_data, valid_data, test_data), batch_size=BATCH_SIZE, device=device) # 训练模型 for epoch in range(10): train(model, train_iterator, optimizer, criterion) # 在测试集上评估模型(简化,实际应用中需要更详细的评估过程) def evaluate(model, iterator, criterion): model.eval() total_loss = 0 with torch.no_grad(): for batch in iterator: src = batch.src trg = batch.trg output = model(src, trg) output = output.view(-1, output.shape[-1]) trg = trg.view(-1) loss = criterion(output, trg) total_loss += loss.item() return total_loss / len(iterator) test_loss = evaluate(model, test_iterator, criterion) print(f'Test Loss: { test_loss:.3f}')