目录
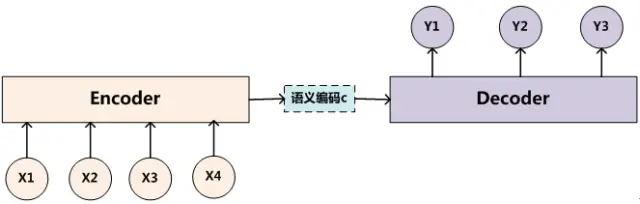
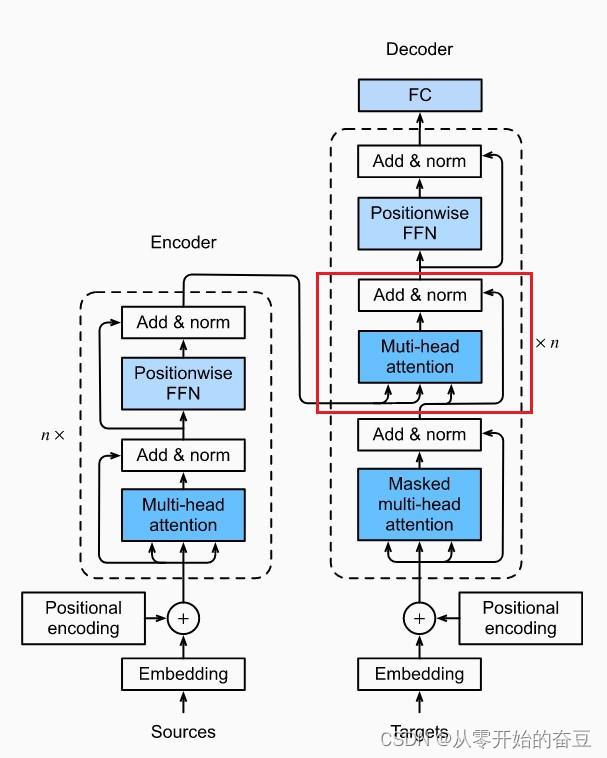
前述: Transformer总体结构框图

(1)嵌入层:编码器的输入是一系列的词嵌入(Word Embeddings),它将文本中的每个词映射到一个高维空间中的向量表示。
嵌入层的作用是将离散符号转换为连续的向量表示,降低数据维度同时保留语义信息,提供词语的上下文信息以及初始化模型参数,从而为深度学习模型提供了有效的输入表示。
class Embedder(nn.Module):
def __init__(self, vocab_size, d_model):
super().__init__()
self.d_model = d_model
self.embed = nn.Embedding(vocab_size, d_model)
def forward(self, x):
return self.embed(x)
(2)位置编码器:为了使 Transformer 能够处理序列信息,位置编码被引入到词嵌入中,以区分不同位置的词。通常使用正弦和余弦函数来生成位置编码。
一句话中同一个词,如果词语出现位置不同,意思可能发生翻天覆地的变化,就比如:我爱你 和 你爱我。这两句话的意思完全不一样。可见获取词语出现在句子中的位置信息是一件很重要的事情。但是Transformer 的是完全基于self-Attention地,而self-attention是不能获取词语位置信息的,就算打乱一句话中词语的位置,每个词还是能与其他词之间计算attention值,就相当于是一个功能强大的词袋模型,对结果没有任何影响。所以在我们输入的时候需要给每一个词向量添加位置编码。
class PositionalEncoder(nn.Module):
def __init__(self, d_model, max_seq_len = 200, dropout = 0.1):
super().__init__()
self.d_model = d_model
self.dropout = nn.Dropout(dropout)
# create constant 'pe' matrix with values dependant on
# pos and i
pe = torch.zeros(max_seq_len, d_model)
for pos in range(max_seq_len):
for i in range(0, d_model, 2):
pe[pos, i] = math.sin(pos / (10000 ** ((2 * i)/d_model)))
pe[pos, i + 1] = math.cos(pos / (10000 ** ((2 * (i + 1))/d_model)))
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
# make embeddings relatively larger
x = x * math.sqrt(self.d_model)
#add constant to embedding
seq_len = x.size(1)
pe = Variable(self.pe[:,:seq_len], requires_grad=False)
if x.is_cuda:
pe.cuda()
x = x + pe
return self.dropout(x)
(3)多头注意力层:这是编码器的核心组件之一。它允许模型在输入序列中学习词与词之间的依赖关系,通过计算每个词对其他词的注意力权重来实现。多头机制允许模型在不同的表示空间中并行地学习多种关注方向。
多头注意力层详情查看地址!
def attention(q, k, v, d_k, mask=None, dropout=None):
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
mask = mask.unsqueeze(1)
scores = scores.masked_fill(mask == 0, -1e9)
scores = F.softmax(scores, dim=-1)
if dropout is not None:
scores = dropout(scores)
output = torch.matmul(scores, v)
return output
class MultiHeadAttention(nn.Module):
def __init__(self, heads, d_model, dropout = 0.1):
super().__init__()
self.d_model = d_model
self.d_k = d_model // heads
self.h = heads
self.q_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.out = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
bs = q.size(0)
# perform linear operation and split into N heads
k = self.k_linear(k).view(bs, -1, self.h, self.d_k)
q = self.q_linear(q).view(bs, -1, self.h, self.d_k)
v = self.v_linear(v).view(bs, -1, self.h, self.d_k)
# transpose to get dimensions bs * N * sl * d_model
k = k.transpose(1,2)
q = q.transpose(1,2)
v = v.transpose(1,2)
scores = attention(q, k, v, self.d_k, mask, self.dropout)
concat = scores.transpose(1,2).contiguous().view(bs, -1, self.d_model)
output = self.out(concat)
return output
(4) 残差连接与规范化层:在多头自注意力层之后,通常会添加残差连接和规范化层来加速训练和提高模型稳定性。残差连接主要是保存原图信息,防止过拟合
"""规范化层"""
class Norm(nn.Module):
def __init__(self, d_model, eps = 1e-6):
super().__init__()
self.size = d_model
# create two learnable parameters to calibrate normalisation
self.alpha = nn.Parameter(torch.ones(self.size))
self.bias = nn.Parameter(torch.zeros(self.size))
self.eps = eps
def forward(self, x):
norm = self.alpha * (x - x.mean(dim=-1, keepdim=True)) \
/ (x.std(dim=-1, keepdim=True) + self.eps) + self.bias
return norm
(5) 前馈全连接层:在多头自注意力层之后,还有一个前馈全连接层,它对每个位置的词向量进行非线性变换和映射。
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff=2048, dropout = 0.1):
super().__init__()
# We set d_ff as a default to 2048
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
x = self.dropout(F.relu(self.linear_1(x)))
x = self.linear_2(x)
return x
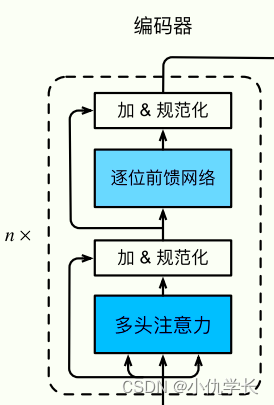
一、编码器encoder
1. 编码器作用
编码器的作用是将输入序列转换为语义表示,学习输入序列中词与词之间的依赖关系,并提取输入序列的特征表示,为解码器生成目标序列提供有用的信息。
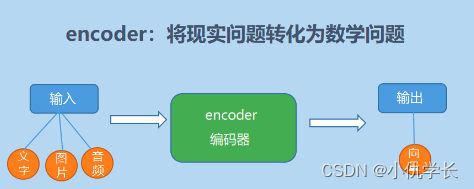
2. 编码器部分
(1)单个编码器层代码
class EncoderLayer(nn.Module):
def __init__(self, d_model, heads, dropout=0.1):
super().__init__()
self.norm_1 = Norm(d_model) #定义规范化层
self.norm_2 = Norm(d_model)
self.attn = MultiHeadAttention(heads, d_model, dropout=dropout) #定义多头注意力层
self.ff = FeedForward(d_model, dropout=dropout) #前馈全连接层
self.dropout_1 = nn.Dropout(dropout) #丢弃层
self.dropout_2 = nn.Dropout(dropout)
def forward(self, x, mask):
x2 = self.norm_1(x)
x = x + self.dropout_1(self.attn(x2,x2,x2,mask)) #残差连接
x2 = self.norm_2(x)
x = x + self.dropout_2(self.ff(x2))
return x
(2)编码器总体代码
这里需要将上述的编码器层进行克隆复制n份。
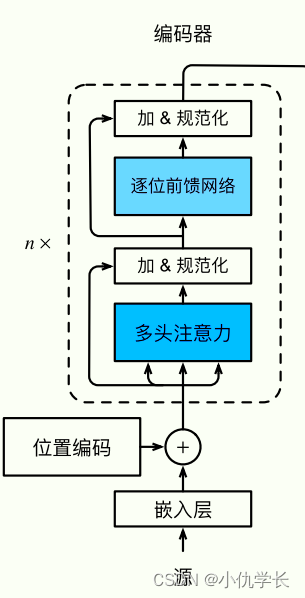
"""编码器总体""
#克隆多层编码器层
def get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
class Encoder(nn.Module):
def __init__(self, vocab_size, d_model, N, heads, dropout):
super().__init__()
self.N = N #n个编码器层
self.embed = Embedder(vocab_size, d_model) #嵌入层
self.pe = PositionalEncoder(d_model, dropout=dropout) #位置编码
self.layers = get_clones(EncoderLayer(d_model, heads, dropout), N) #复制n个编码器层
self.norm = Norm(d_model) #规范化层
def forward(self, src, mask):
x = self.embed(src)
x = self.pe(x)
for i in range(self.N):
x = self.layers[i](x, mask)
return self.norm(x)
二、解码器decoder
1. 解码器作用
2. 解码器部分
(1)单个解码器层代码
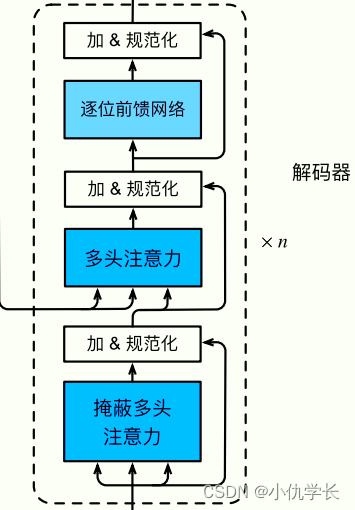
class DecoderLayer(nn.Module):
def __init__(self, d_model, heads, dropout=0.1):
super().__init__()
self.norm_1 = Norm(d_model) #定义规范化层
self.norm_2 = Norm(d_model)
self.norm_3 = Norm(d_model)
self.dropout_1 = nn.Dropout(dropout) #定义丢弃层
self.dropout_2 = nn.Dropout(dropout)
self.dropout_3 = nn.Dropout(dropout)
self.attn_1 = MultiHeadAttention(heads, d_model, dropout=dropout) #多头注意力层
self.attn_2 = MultiHeadAttention(heads, d_model, dropout=dropout)
self.ff = FeedForward(d_model, dropout=dropout) #前馈全连接层
def forward(self, x, e_outputs, src_mask, trg_mask):
x2 = self.norm_1(x)
x = x + self.dropout_1(self.attn_1(x2, x2, x2, trg_mask))
x2 = self.norm_2(x)
x = x + self.dropout_2(self.attn_2(x2, e_outputs, e_outputs, \
src_mask))
x2 = self.norm_3(x)
x = x + self.dropout_3(self.ff(x2))
return x
(2)解码器总体代码
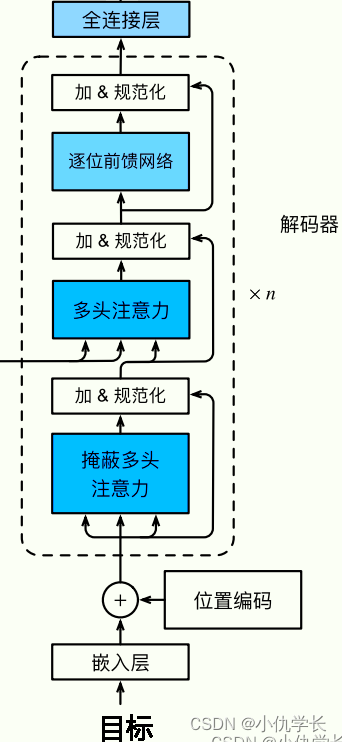
def get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
class Decoder(nn.Module):
def __init__(self, vocab_size, d_model, N, heads, dropout):
super().__init__()
self.N = N
self.embed = Embedder(vocab_size, d_model) #嵌入层
self.pe = PositionalEncoder(d_model, dropout=dropout) #位置编码
self.layers = get_clones(DecoderLayer(d_model, heads, dropout), N) #复制n层解码器层
self.norm = Norm(d_model) #规范化层
def forward(self, trg, e_outputs, src_mask, trg_mask):
x = self.embed(trg)
x = self.pe(x)
for i in range(self.N):
x = self.layers[i](x, e_outputs, src_mask, trg_mask)
return self.norm(x)
三、Transformer
1. 框图
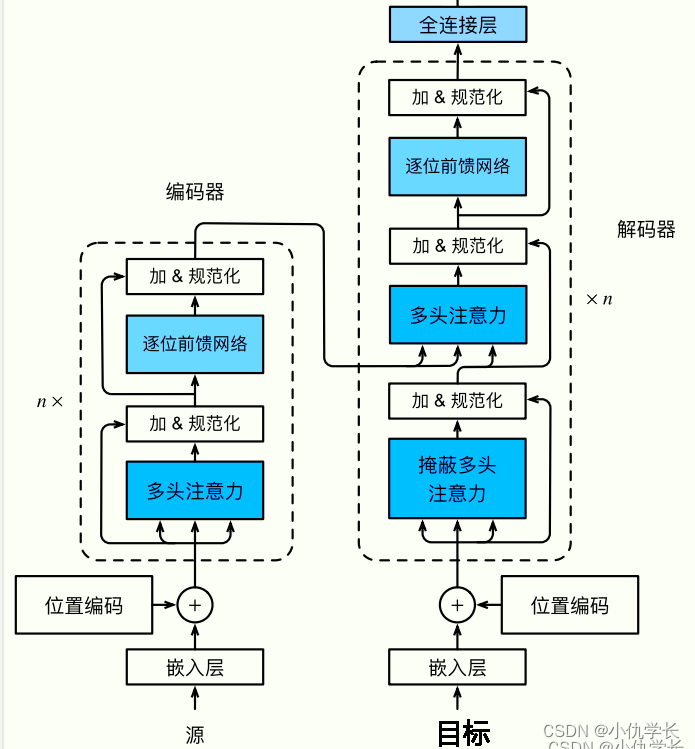
2. 代码
class Transformer(nn.Module):
def __init__(self, src_vocab, trg_vocab, d_model, N, heads, dropout):
super().__init__()
self.encoder = Encoder(src_vocab, d_model, N, heads, dropout) #编码器总体
self.decoder = Decoder(trg_vocab, d_model, N, heads, dropout) #解码器总体
self.out = nn.Linear(d_model, trg_vocab) #全连接层输出
def forward(self, src, trg, src_mask, trg_mask):
e_outputs = self.encoder(src, src_mask)
d_output = self.decoder(trg, e_outputs, src_mask, trg_mask)
output = self.out(d_output)
return output