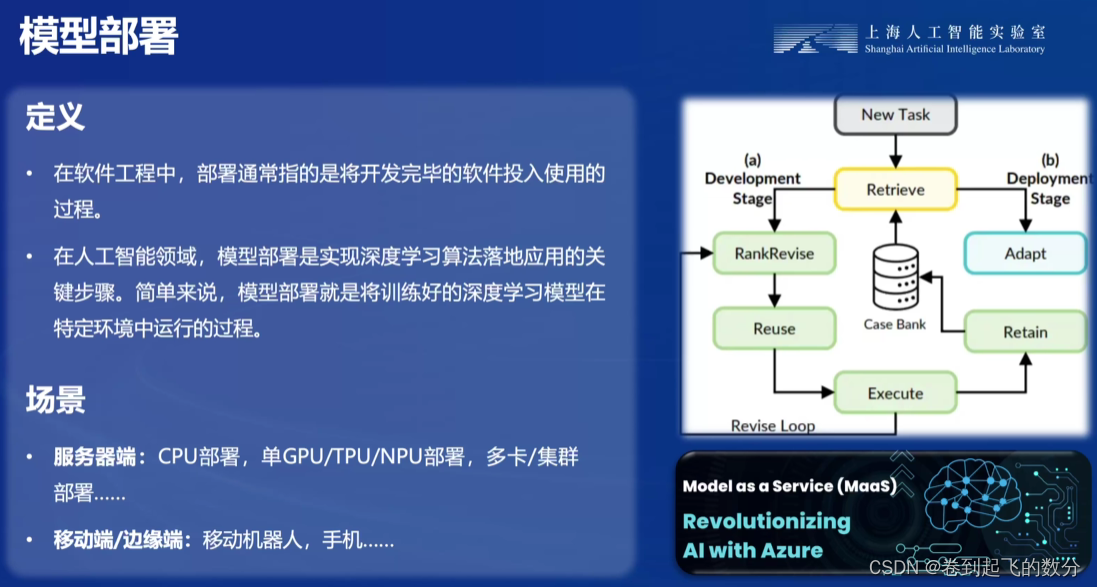
大模型部署背景

参数用FP16半精度也就是2字节,7B的模型就大约占14G

2.LMDeploy简介

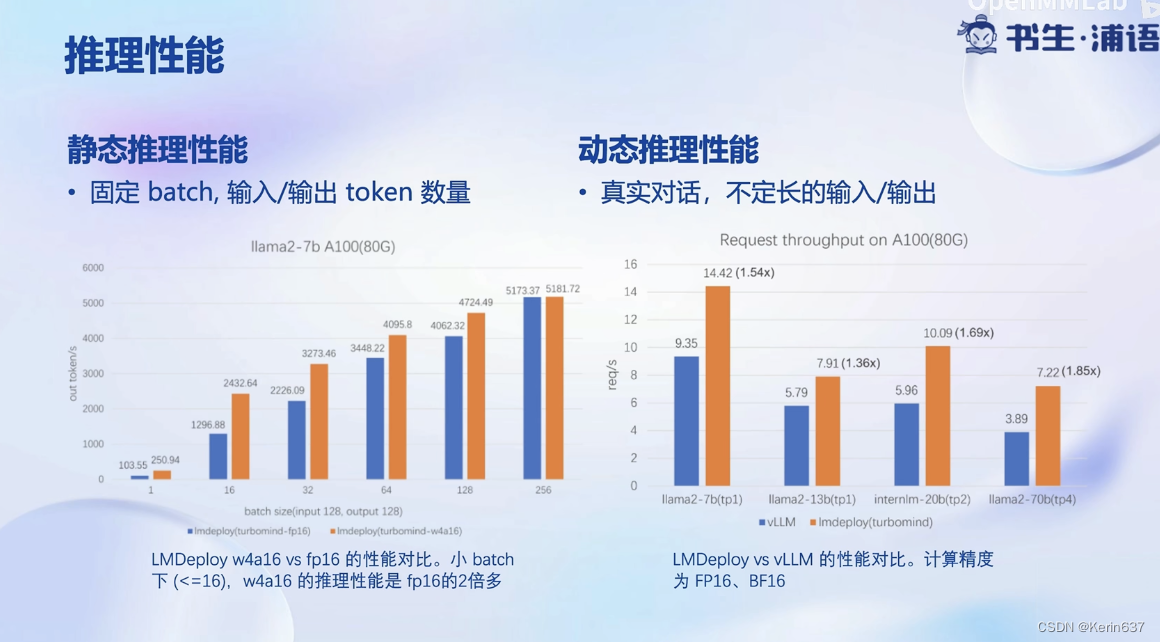
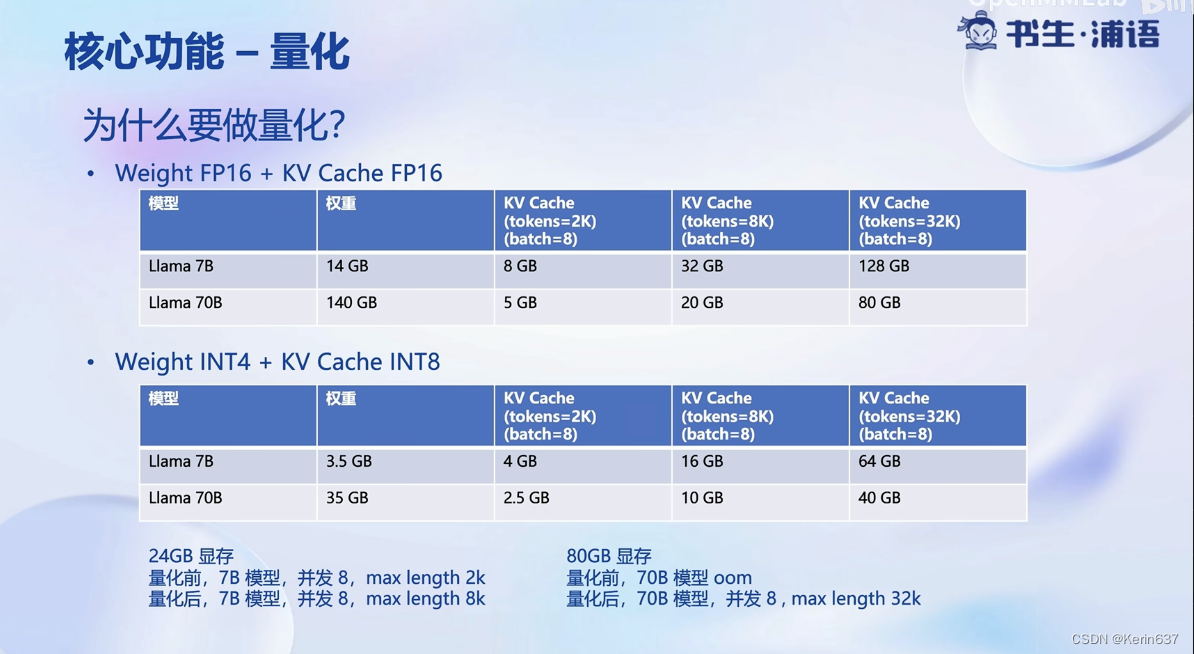
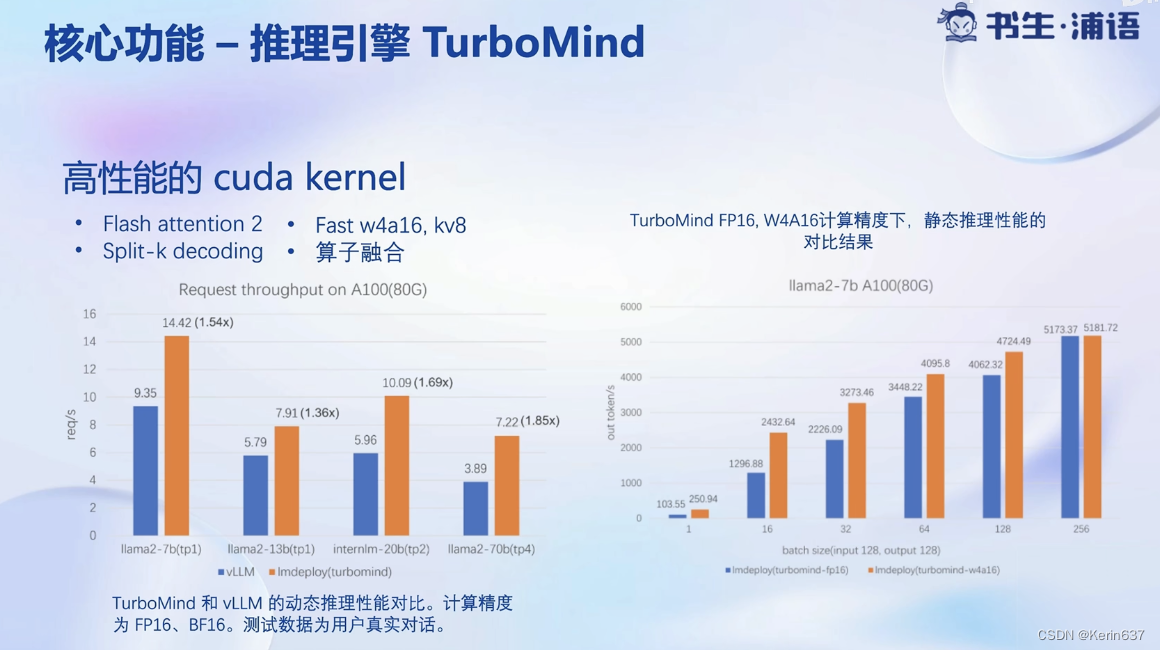
量化降低显存需求量,提高推理速度

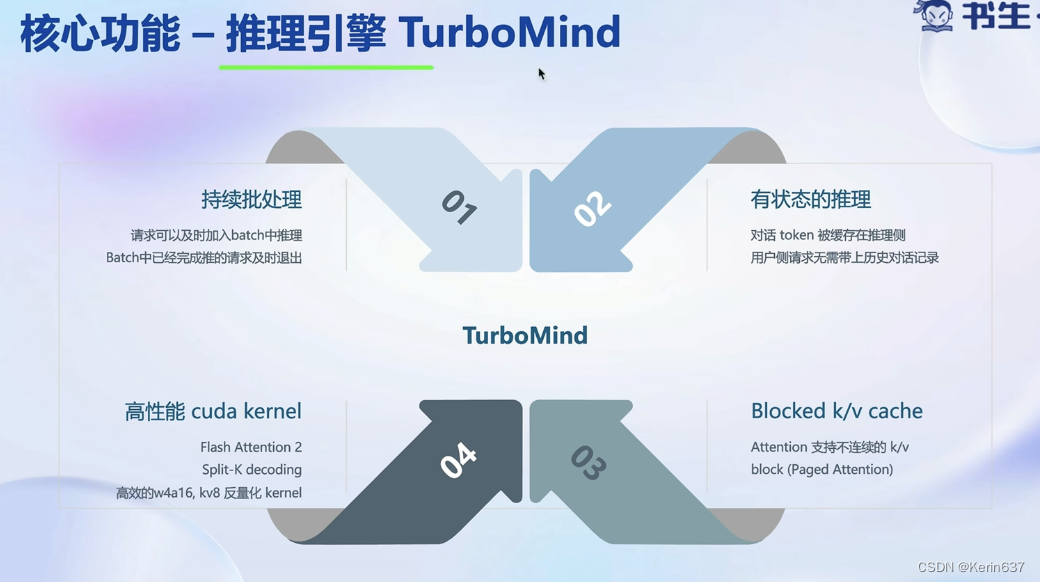
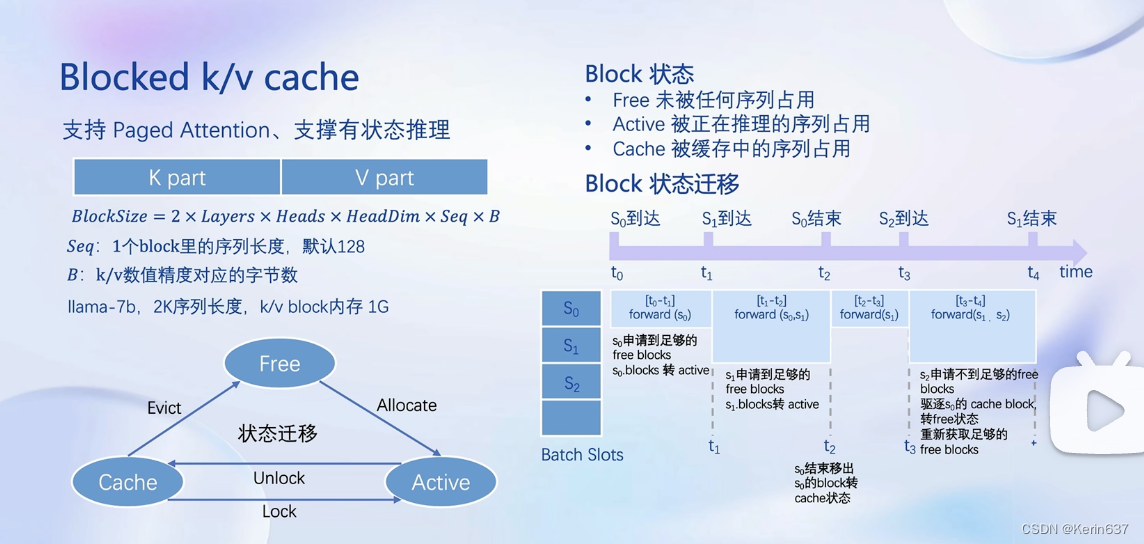
大语言模型推理是典型的访问密集型,因为是decoder only的架构,需要token by token的生成,因此需要频繁读取之前生成过的token。
这个量化只是在存储时做的, 在推理时还要反量化回FP16.
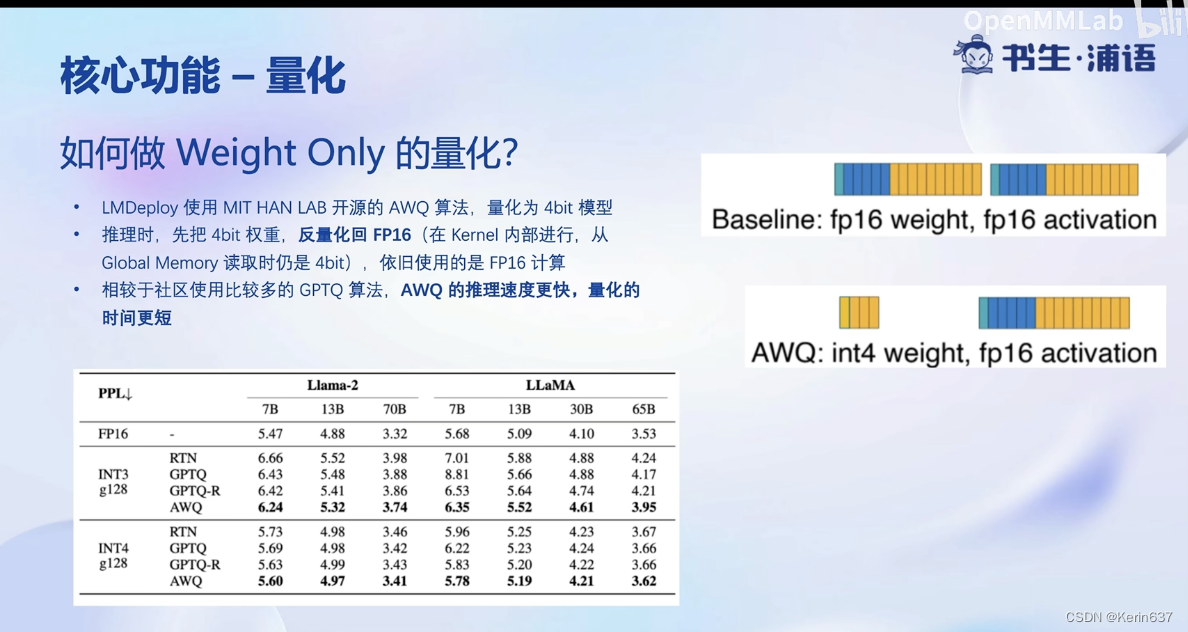
w4a16意思是参数4bit量化,激活时是16bit
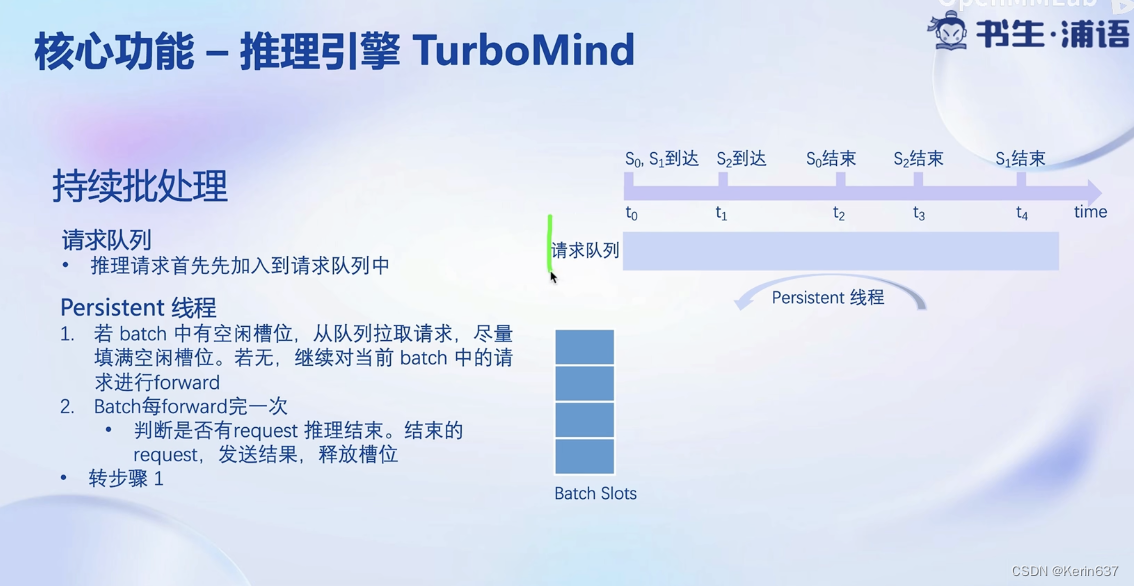
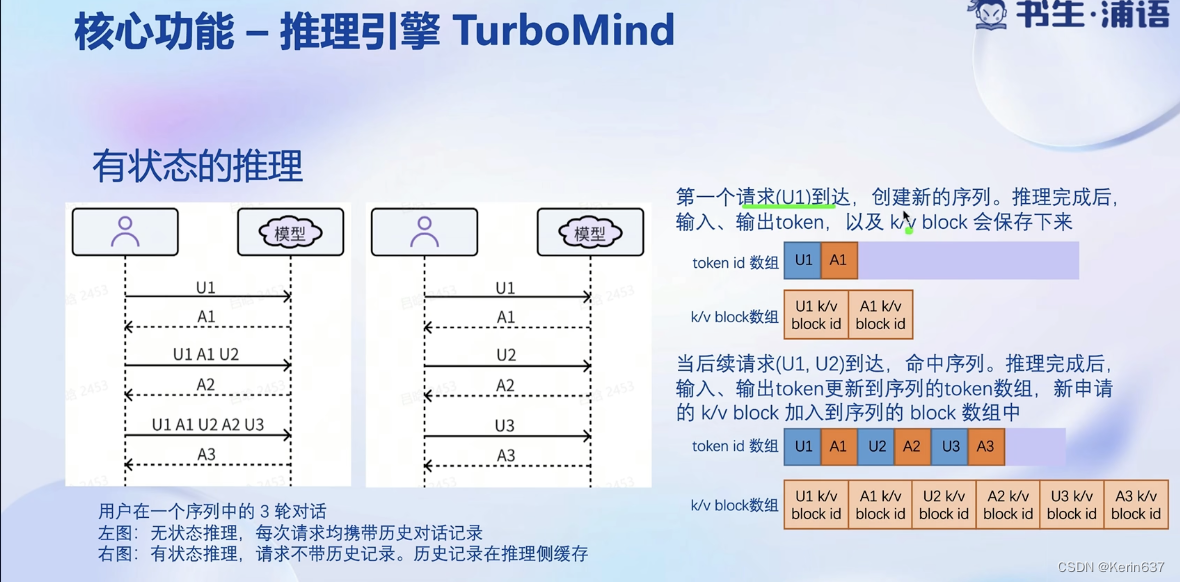
不用等一个batch的请求全部执行完才退出。
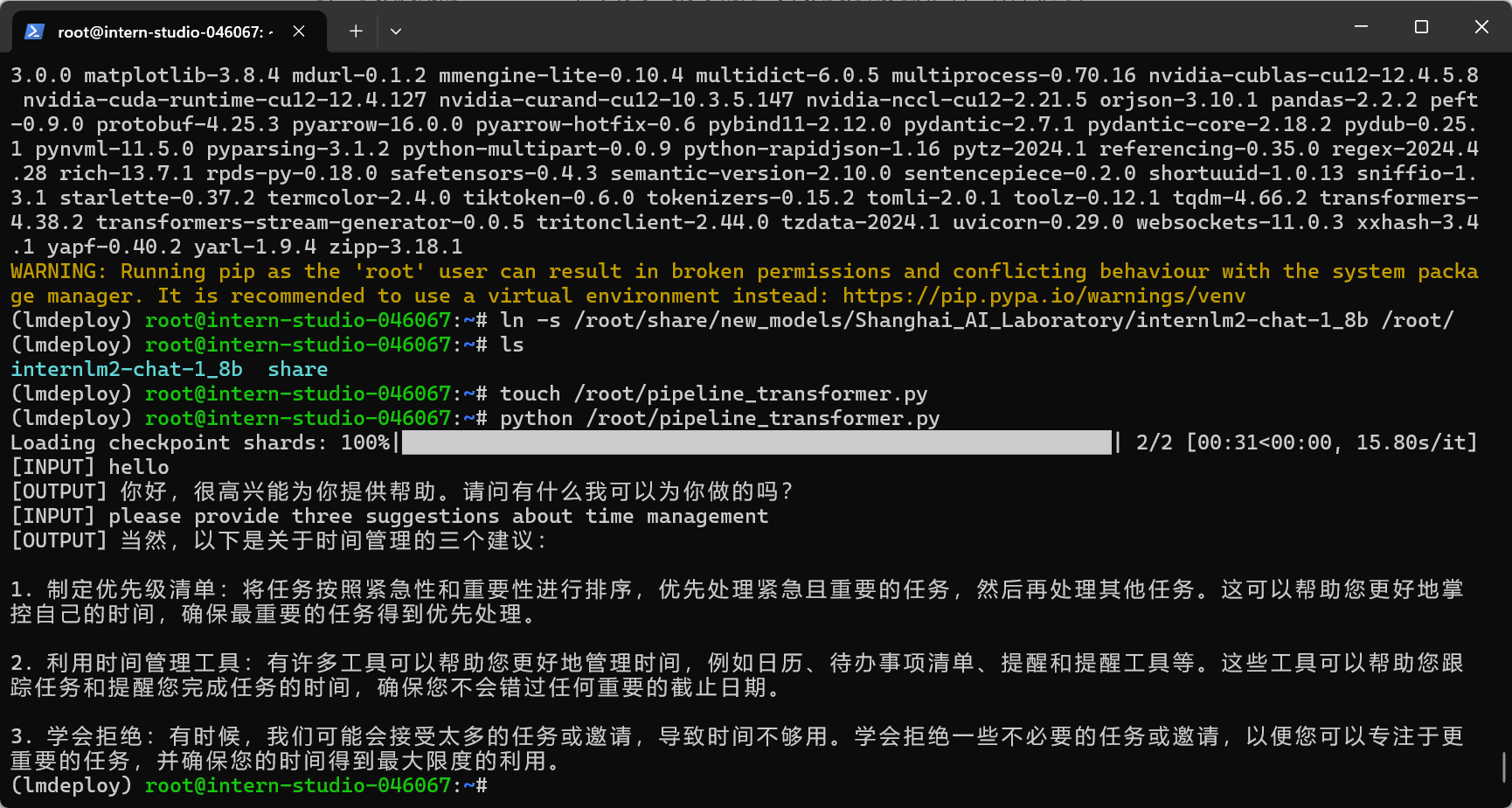
3.动手实践-安装、部署、量化






![[书生·浦语<span style='color:red;'>大</span><span style='color:red;'>模型</span><span style='color:red;'>实战</span>营]——<span style='color:red;'>LMDeploy</span> <span style='color:red;'>量化</span><span style='color:red;'>部署</span> LLM <span style='color:red;'>实践</span>](https://img-blog.csdnimg.cn/direct/8d577c3ced1b42588c295eb8f7ad0e7f.png)



















![[C#] 如何调用Python脚本程序](https://img-blog.csdnimg.cn/direct/bc94975f80bb43b095ac4cab3c5e379f.png)