🎉AI学习星球推荐: GoAI的学习社区 知识星球是一个致力于提供《机器学习 | 深度学习 | CV | NLP | 大模型 | 多模态 | AIGC 》各个最新AI方向综述、论文等成体系的学习资料,配有全面而有深度的专栏内容,包括不限于 前沿论文解读、资料共享、行业最新动态以、实践教程、求职相关(简历撰写技巧、面经资料与心得)多方面综合学习平台,强烈推荐AI小白及AI 1;;爱好者学习,性价比非常高!加入星球➡️点击链接
【 书生·浦语大模型实战营】学习笔记(五):LMDeploy 量化部署
👨💻导读: 本篇笔记内容主要分为模型部署理论进行介绍。从量化、剪枝、知识蒸馏方面引入。主要对LMDeploy框架支持的模型、安装过程、base | chat对话 | Lite量化等进行介绍,欢迎大家交流学习!
本次学习资料
1.【视频】:LMDeploy 量化部署 LLM
2.【文档】:https://github.com/InternLM/Tutorial/blob/camp2/lmdeploy/README.md
3.【作业】:https://github.com/InternLM/Tutorial
基础作业
- 配置 LMDeploy 运行环境
- 以命令行方式与 InternLM2-Chat-1.8B 模型对话
4.【环境】开发机:InternStudio 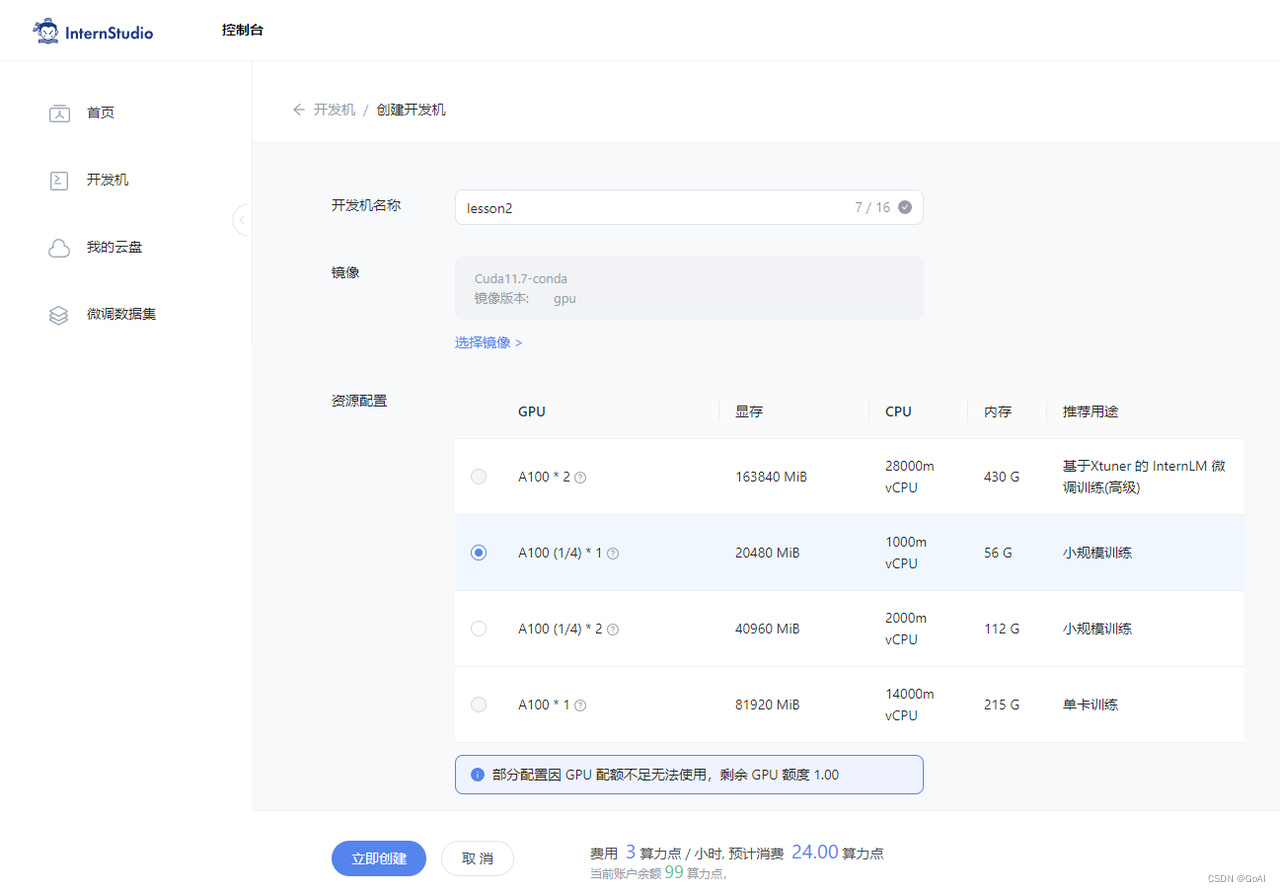
模型部署定义
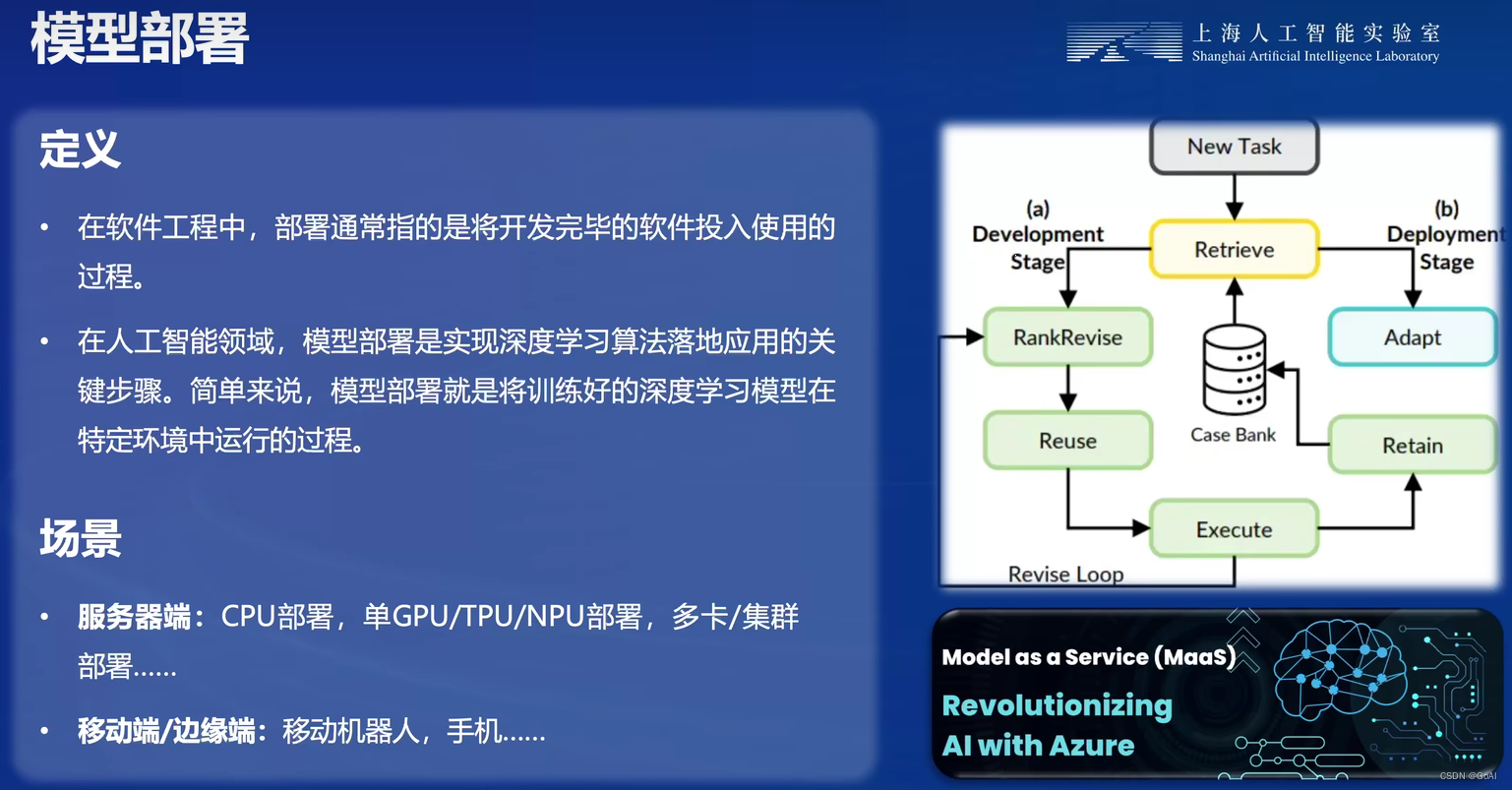
模型部署挑战

模型剪枝:

量化:

知识蒸馏:

LMDeploy
LMDeploy 由 MMDeploy 和 MMRazor 团队联合开发,是涵盖了 LLM 任务的全套轻量化、部署和服务解决方案。 这个强大的工具箱提供以下核心功能:
核心功能:

高效推理引擎 TurboMind:基于 FasterTransformer,我们实现了高效推理引擎 TurboMind,支持 InternLM、LLaMA、vicuna等模型在 NVIDIA GPU 上的推理。
交互推理方式:通过缓存多轮对话过程中 attention 的 k/v,记住对话历史,从而避免重复处理历史会话。
多 GPU 部署和量化:我们提供了全面的模型部署和量化支持,已在不同规模上完成验证。
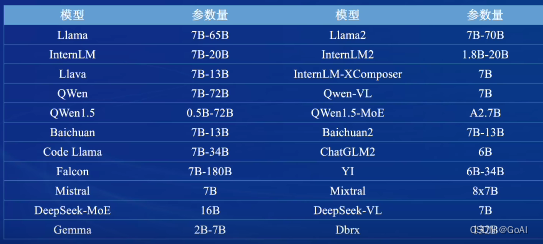
LMDeploy 支持的大模型:
LMDeploy模型对话(chat)
1.HuggingFace
托管在HuggingFace社区的模型通常采用HuggingFace格式存储,简写为HF格式。
2.TurboMind
TurboMind是LMDeploy团队开发的一款关于LLM推理的高效推理引擎,它的主要功能包括:
LLaMa 结构模型的支持,
continuous batch 推理模式
可扩展的 KV 缓存管理器。
1.LMDeploy环境部署
InternStudio开发机创建conda环境
studio-conda -t lmdeploy -o pytorch-2.1.2
激活环境并安装lmdeploy
conda activate lmdeploy
pip install lmdeploy[all]==0.3.0
2.LMDeploy模型对话(chat)
2.2 下载模型
开发机的共享目录中常用的预训练模型,运行如下命令查看:
ls /root/share/new_models/Shanghai_AI_Laboratory/
执行指令由开发机的共享目录软链接或拷贝模型:
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/
# cp -r /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/
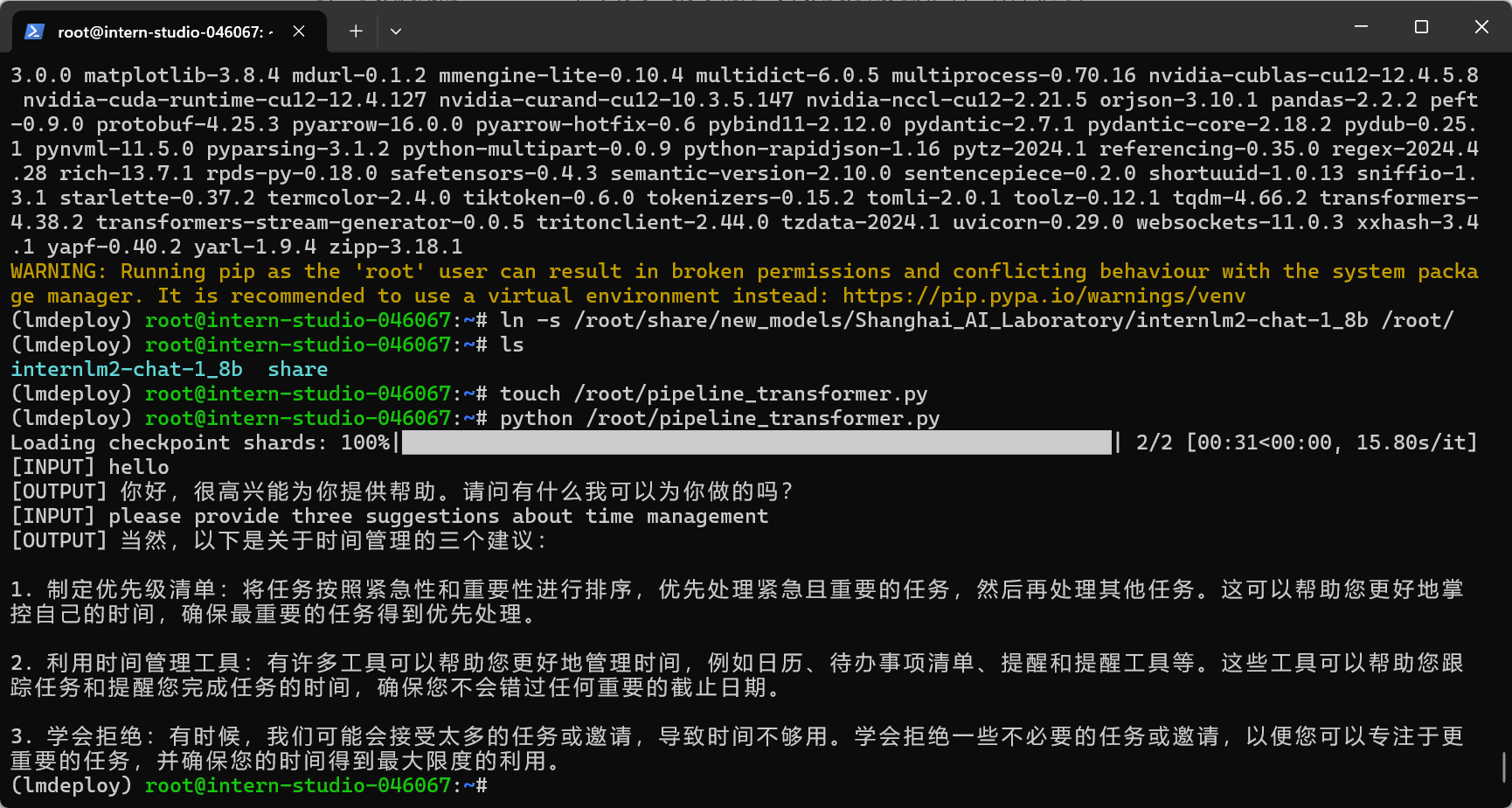
2.3 使用Transformer库运行模型
用Transformer来直接运行InternLM2-Chat-1.8B模型,终端中输入如下指令,新建pipeline_transformer.py。
touch /root/pipeline_transformer.py
将以下内容复制粘贴进入pipeline_transformer.py。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("/root/internlm2-chat-1_8b", trust_remote_code=True)
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and cause OOM Error.
model = AutoModelForCausalLM.from_pretrained("/root/internlm2-chat-1_8b", torch_dtype=torch.float16, trust_remote_code=True).cuda()
model = model.eval()
inp = "hello"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=[])
print("[OUTPUT]", response)
inp = "please provide three suggestions about time management"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=history)
print("[OUTPUT]", response)
运行代码:
python /root/pipeline_transformer.py

2.4 使用LMDeploy与模型对话
使用LMDeploy与模型进行对话的通用命令格式为:
lmdeploy chat [HF格式模型路径/TurboMind格式模型路径]
chat-1_8b为例:
lmdeploy chat /root/internlm2-chat-1_8b
参数展示:

效果展示:


注:有关LMDeploy的chat功能的更多参数可通过-h命令查看。
3.LMDeploy模型量化(lite)
量化:主要包括 KV8量化和W4A16量化。总的来说,量化是一种以参数或计算中间结果精度下降换空间节省(以及同时带来的性能提升)的策略。
- 计算密集(compute-bound): 指推理过程中,绝大部分时间消耗在数值计算上;针对计算密集型场景,可以通过使用更快的硬件计算单元来提升计算速。
- 访存密集(memory-bound): 指推理过程中,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般通过减少访存次数、提高计算访存比或降低访存量来优化。
使用KV8量化和W4A16量化来优化 LLM 模型推理中的访存密集问题:
KV8量化是指将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用。
W4A16 量化,将 FP16 的模型权重量化为 INT4,Kernel 计算时,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本。Weight Only 是指仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)。
3.1 设置最大KV Cache缓存大小
KV Cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。当显存空间不足时,也可以将KV Cache放在内存,通过缓存管理器控制将当前需要使用的数据放入显存。
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、KV Cache占用的显存,以及中间运算结果占用的显存。LMDeploy的KV Cache管理器可以通过设置--cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例。默认的比例为0.8。
调整--cache-max-entry-count参数的效果。首先保持不加该参数(默认0.8),运行1.8B模型。
lmdeploy chat /root/internlm2-chat-1_8b
与模型对话,查看右上角资源监视器中的显存占用情况。

改变--cache-max-entry-count参数,设为0.5。
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.5
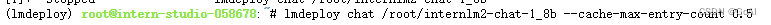
与模型对话,再次查看右上角资源监视器中的显存占用情况。
看到显存占用明显降低。
3.2 使用W4A16量化
LMDeploy使用AWQ算法,实现模型4bit权重量化。推理引擎TurboMind提供了非常高效的4bit推理cuda kernel,性能是FP16的2.4倍以上。它支持以下NVIDIA显卡:
- 图灵架构(sm75):20系列、T4
- 安培架构(sm80,sm86):30系列、A10、A16、A30、A100
- Ada Lovelace架构(sm90):40 系列
安装依赖库:
pip install einops==0.7.0
模型量化命令:
lmdeploy lite auto_awq \
/root/internlm2-chat-1_8b \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir /root/internlm2-chat-1_8b-4bit
量化工作结束后,新的HF模型被保存到internlm2-chat-1_8b-4bit目录。
使用Chat功能运行W4A16量化后的模型:
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq
将KV Cache比例再次调为0.01,查看显存占用情况,显存占用明显降低。
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq --cache-max-entry-count 0.01
总结
本篇笔记内容主要分为模型部署理论进行介绍。从量化、剪枝、知识蒸馏方面引入。主要对LMDeploy框架支持的模型、安装过程、base|chat对话|Lite量化等进行介绍,欢迎大家交流学习!
![[<span style='color:red;'>书生</span>·<span style='color:red;'>浦</span><span style='color:red;'>语</span><span style='color:red;'>大</span><span style='color:red;'>模型</span><span style='color:red;'>实战</span><span style='color:red;'>营</span>]——<span style='color:red;'>LMDeploy</span> <span style='color:red;'>量化</span><span style='color:red;'>部署</span> LLM <span style='color:red;'>实践</span>](https://img-blog.csdnimg.cn/direct/8d577c3ced1b42588c295eb8f7ad0e7f.png)