【图像分割 2024】ParaTransCNN
论文题目:ParaTransCNN: Parallelized TransCNN Encoder for Medical Image Segmentation
中文题目:用于医学图像分割的并行TransCNN编码器
论文链接:https://arxiv.org/abs/2401.15307
论文代码:HongkunSun/ParaTransCNN (github.com)
论文团队:浙江工商大学,北京师范大学
发表时间:
DOI:
引用:
引用数:
摘要
基于卷积神经网络的医学图像分割方法以其优异的性能得到越来越多的应用。然而,它们很难捕获远程依赖关系,而远程依赖关系对于准确建模全局上下文相关性至关重要。由于能够通过扩展接受域来建立长期依赖关系的模型,基于转换器的方法已经获得了突出的地位。受此启发,我们提出了一种结合卷积神经网络和Transformer架构的先进二维特征提取方法。更具体地说,我们引入了一个并行编码器结构,其中一个分支使用ResNet从图像中提取局部信息,而另一个分支使用Transformer提取全局信息。此外,我们将金字塔结构集成到Transformer中,以不同分辨率提取全局信息,特别是在密集的预测任务中。为了在解码器阶段有效地利用并行编码器中的不同信息,我们使用信道关注模块来合并编码器的特征并通过跳过连接和瓶颈传播它们。在主动脉血管树、心脏和多器官数据集上进行了密集的数值实验。通过与现有医学图像分割方法的比较,我们的方法具有更好的分割精度,特别是对小器官的分割。
1. 介绍
人工标记医学图像中病变和非病变区域的不同特征对医生来说既耗时又具有挑战性。因此,计算机辅助诊断(ComputerAided Diagnosis, CAD)[45]、[40]系统可以准确分割病变区域,通过辅助医生决策,提高疾病筛查和诊断的有效性。
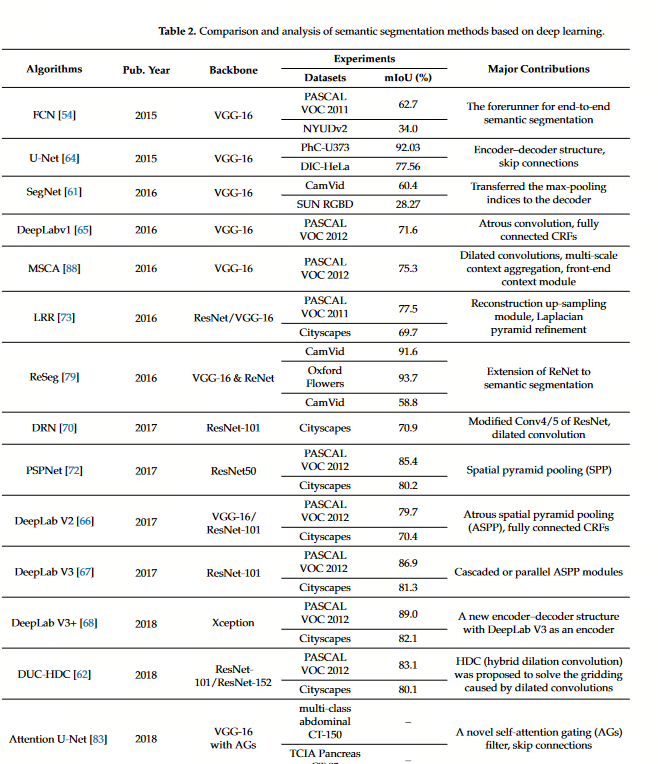
U-Net[39]是一种开创性的医学图像分割架构,在各种分割任务中取得了相当大的成功。在编码器中通过下采样学习输入图像的特征信息,通过跳过连接将低级和高级语义信息结合起来,通过上采样恢复图像的详细信息,生成分割掩码。此后,对称u型架构成为图像分割任务的标准结构,如Att U-Net[34]、FCRB U-Net[41]、V-Net[33]、HADCNet[15]等。然而,这些方法受到卷积核接受域的限制,只能对局部信息进行建模,缺乏全局建模的能力。DeepLab[11]引入了扩张卷积的概念来扩展卷积核的接受野。随后的版本DeepLabv3[12]和DeepLabv3+[13]使用不同扩张率的扩张卷积提取多尺度信息。然而,基于卷积神经网络(CNN)的方法只能对图像中的局部信息进行建模并且缺乏对序列之间的长期依赖关系进行建模的能力。
视觉变压器(Vision Transformer, ViT)[17]被引入到计算机视觉任务中,以解决CNN的局限性。
ViT通过自身的自注意机制,可以有效地对图像内序列和序列之间的关系进行建模,实现全局信息的提取。各种方法,如ViTAE[49]、Swin Transformer[32]和PVT[47]已经证明了Transformer在计算机视觉任务中的适用性和有效性。随后,对变形金刚在医学图像分割中的应用进行了探讨。
纯Transformer架构,如Swin U-Net [8], TransDeepLab [4], misformer[24]和DAE-Former[3],将Transformer应用于编码器和解码器,允许在多个分辨率下提取全局特征。
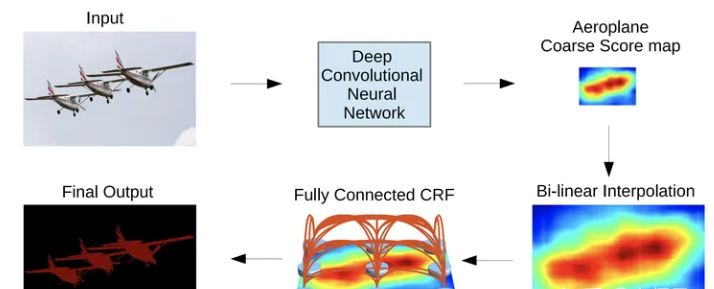
然而,这些方法忽略了CNN在学习局部特征方面的优势,导致无法从医学图像中提取出足够的详细信息。为了解决这一问题,人们提出了将CNN和Transformer相结合的混合网络用于医学图像分割,如TransUNet[10]、HiFormer[22]、TransCeption[5]、MSRAformer[48]。这些方法将Transformer合并为编码器中的瓶颈或解码器的一部分,通常使用跳过连接。然而,尽管融合了CNN和Transformer,这些方法仍然没有充分利用Transformer在不同分辨率下的特征提取能力。此外,单个编码器(见图1)限制了CNN和Transformer在复杂图像处理任务中的潜力。因此,有必要进一步开发医学图像分割模型,有效地利用这两个Transformer的优势和CNN,整合各自捕获全局和局部信息的能力,以提高医学图像分割性能,特别是对于复杂的解剖结构,如多器官和主动脉血管树。

考虑到CNN和Transformer所具有的独特优势,我们提出了一种新的并行编码器架构,称为paratransscnn,用于医学图像分割。如图1所示,编码器和解码器有三种常见配置:基于CNN、Transformer或CNN和Transformer的组合。而TransUNet[10]等方法只是简单地将CNN和Transformer的特征进行整合和叠加,无法充分发挥局部特征和全局特征的融合效果。因此,我们提出了一种新的特征融合技术,利用信道关注模块在不同尺度上融合局部和全局特征。具体来说,我们的编码器包括两个分支:一个利用Transformer捕获全局特征,另一个利用CNN提取局部特征。利用信道关注和跳变连接,将不同尺度的特征有效融合并传递给解码器。综上所述,我们的贡献可以总结如下
- 我们提出了paratransscnn网络,这是一个u形医学图像分割架构,涉及一个由CNN和Transformer组成的并行编码器。我们的编码器可以提取不同维度的局部和全局特征,并将它们有效地融合在一起,为解码器提供丰富的像素级语义信息。
- Transformer分支采用金字塔结构来学习不同尺度的全局信息,而CNN分支使用相同的下采样策略来学习局部信息。为了实现有效的多尺度特征融合,设计了通道关注模块,激活有用的通道特征,抑制不必要的通道特征。
- 我们提供了主动脉血管树、心脏和多器官分割的数值实验,并将其与最新的分割方法进行了比较。我们的模型显示了令人满意的分割精度。尤其是在细小的血管分支和胰腺、肾脏、胃等小器官上。
2. 相关工作
2.1 CNN用于医学图像分割
基于cnn的医学图像分割方法被广泛应用,被认为是医学图像分割中最突出的方法之一。Ronneberger等人[39]最初提出了U-Net模型,该模型由一个编码器和一个解码器组成,可以有效地捕捉图像中的局部和细节特征。随后,Oktay等人[34]提出了Att U-net,通过加入注意门来丰富不同维度特征图的语义信息,从而改善了分割结果。Shu等[41]提出了一种新的基于全连接残差块的FCRB U-Net胎儿小脑超声图像分割方法。用全连通残差块代替原有模型中的双卷积运算,并嵌入有效的通道关注模块,增强对有意义特征的提取。此外,在解码阶段使用特征重用模块,形成全连接的解码器,充分利用深度特征。Liu等[31]开发了一种u型非局部可变形卷积网络来准确预测边界的局部几何形状。此外,基于cnn的方法已被应用于各种医学图像分割任务,包括视网膜图像分割[18]、皮肤分割[52,37]等。这些方法在各种医学图像分割任务中表现出良好的性能,并因其在实施和培训方面的可用性和有效性而得到认可
2.2 用于医学图像分割的视觉ViT
近年来,基于transform的医学图像分割方法受到了广泛关注。转换器利用其自关注机制对远程依赖关系进行建模,并在自然语言处理方面取得了重大突破。Dosovitskiy等[17]提出了视觉变压器(vision transformer, ViT),这是第一次成功的应用变压器在视觉任务中,展示了变压器在计算机视觉中的潜力。随后,Liu等人[32]提出了基于窗口的变压器Swin transformer用于图像分类和目标检测任务。基于窗口的注意机制将图像分割成小块,并在每个小块上进行自注意操作,降低了计算复杂度。Wang等[47]设计了一种用于图像分类和分割的金字塔结构(PVT)视觉转换器,在不同层次上应用不同大小的自注意窗口。它有助于同时捕获全局和局部上下文信息,从而有助于增强对复杂图像细节和总体结构组件的理解。
Cao等[8]首先提出了Swin U-Net,这是一种纯基于变压器的医学图像分割模型,用于多器官分割任务。它在u形分段网络中使用Swin Transformer。Azad等[4]提出了用于皮肤病变分割的TransDeepLab,该方法在DeepLab的基础上应用了不同的窗口策略。Huang等人[24]提出了MISSFormer,旨在利用不同尺度的全局信息进行心脏分割任务,Azad等人[5]提出的TransCeption重新设计了编码器中的补丁合并模块,使其能够在单个阶段内捕获多尺度表示。如图所示,基于transformer的方法在医学图像分割任务中显示出巨大的潜力
2.3 结合CNN和Transformer进行医学图像分割
对于医学图像分割,Chen等[10]提出了TransUNet,这是将transformer应用于多器官分割网络的编码器部分的首次尝试。TransUNet将CNN的局部信息与U-Net的编码器-解码器架构相结合,取得了显著的效果。Li等[28]提出了ATTransUNet,这是TransUNet的改进版本,用于超声和组织病理学图像分割。Heidari等人[22]提出的HiFormer利用Swin Transformer和基于cnn的编码器的组合来设计两种不同的多尺度特征表示。此外,在编码器-解码器结构的跳过连接中引入了双级融合(DLF)模块,以促进全局特征和局部特征的有效融合。
3. 方法
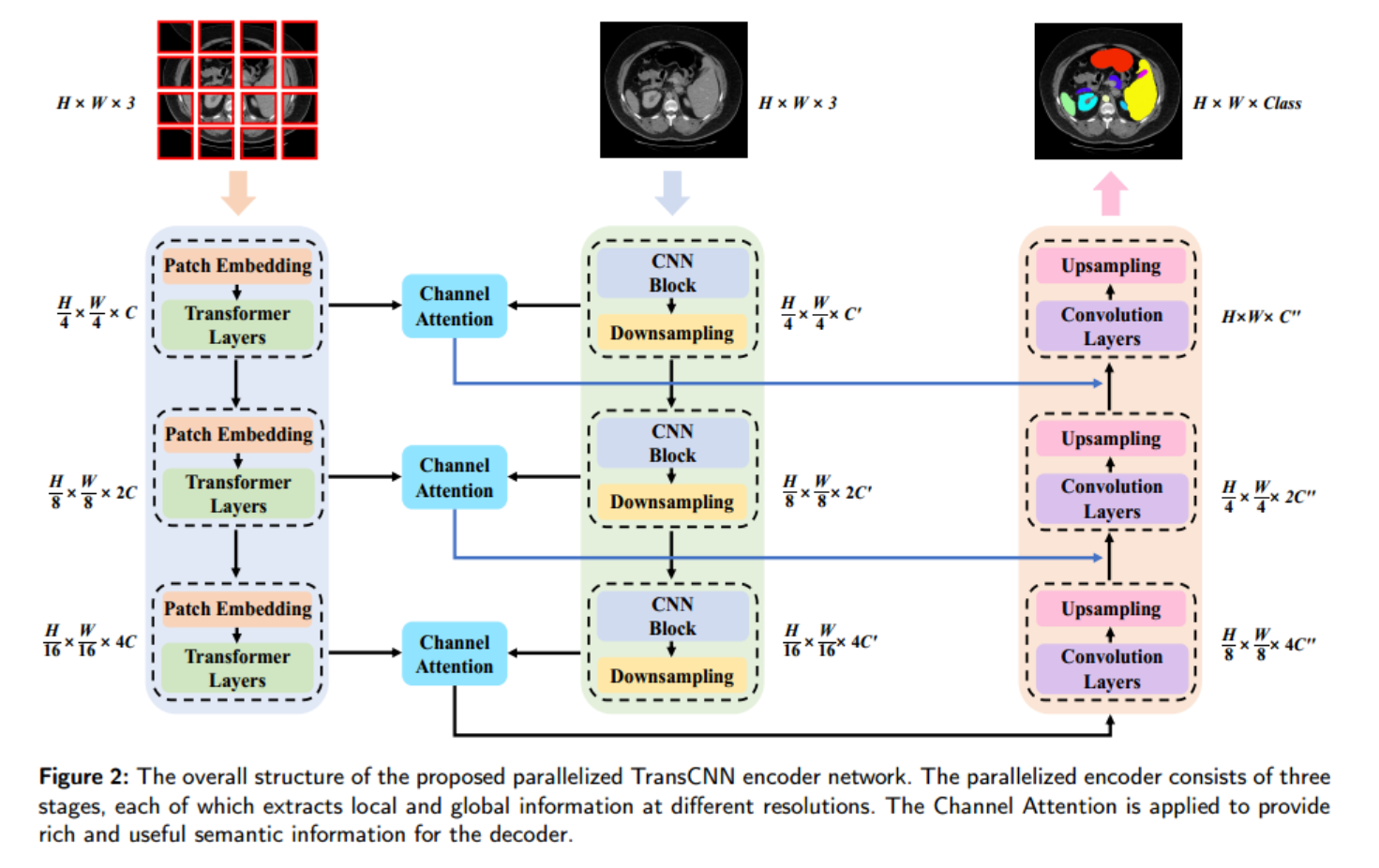
如图2所示,我们提出了一个用于医学图像分割的并行编码器模型。传统的分割模型仅依赖于单个编码器分支来整合图像中的全局和局部信息,而我们的方法结合了两个独立的分支,分别从输入图像中捕获语义信息
paratransnn的整体架构遵循类似于U-Net的编码器-解码器范式,由编码器、信道注意模块、跳过连接、和译码器。值得注意的是,并行编码器结合了作为骨干网的ResNet[21]和Transformer的优点。在Transformer组件中,引入了金字塔结构来以多种分辨率捕获全局特性。此外,采用信道注意模块增强并行编码器的表达能力,丰富提取的特征,为后续解码过程提供全面的指导。我们还利用跳过连接和解码器模块来估计最终的分割掩码。详细的方法将在下面解释。
3.1 并行TransCNN编码器
受前面提到的基于CNN或Transformer的分割模型的启发,我们提出了一种并行编码器来解决单分支编码器的局限性。我们在Transformer中引入金字塔结构来获得不同尺度的全局特征映射。本文提出的并行编码器分为三个阶段,可以提取更全面、更多样的特征表示。
更具体地说,我们采用patch大小为4的patch嵌入层对尺寸为𝐻×𝑊× 3(3为通道)的2D输入图像进行操作,确保没有重叠的patch。然后通过Transformer层对得到的分辨率大小为𝐻4 ×𝑊4 × 的特征图进行处理,获取其全局信息。进入第二阶段,为了保留补丁嵌入层中的详细信息,我们将补丁大小减小到2。这产生分辨率大小为𝐻8 ×𝑊8 × 2 的特征图,该特征图随后通过Transformer层进行进一步处理。在第三阶段,斑块大小保持在2。使用金字塔结构的Transformer编码器,我们按4、8和16的因子顺序对特征映射进行下采样。这种下采样过程对于生成不同尺度的特征图是必不可少的,允许更广泛的接受域和捕获输入图像的分层表示。分支编码器的描述如下:
F V i T 1 = T L 1 ( P a t c h _ E m b e d 1 ( X ) ) ∈ R H 4 × W 4 × C F_{ViT}^{1}=TL_{1}(Patch\_Embed_{1}(X))\in\mathbb{R}^{\frac{H}{4}\times\frac{W}{4}\times C} FViT1=TL1(Patch_Embed1(X))∈R4H×4W×C
F V i T 2 = T L 2 ( P a t c h _ E m b e d 2 ( F V i T 1 ) ) ∈ R H 8 × W 8 × 2 C ( 2 ) F_{ViT}^{2}=TL_{2}(Patch\_Embed_{2}(F_{ViT}^{1}))\in\mathbb{R}^{\frac{H}{8}}\times\frac{W}{8}\times2C\quad(2) FViT2=TL2(Patch_Embed2(FViT1))∈R8H×8W×2C(2)
F V i T 3 = T L 3 ( P a t c h _ E m b e d 3 ( F V i T 2 ) ) ∈ R H 16 × W 16 × 4 C ( 3 ) F_{ViT}^{3}=TL_{3}(Patch\_Embed_{3}(F_{ViT}^{2}))\in\mathbb{R}^{\frac{H}{16}}\times\frac{W}{16}\times4C\quad(3) FViT3=TL3(Patch_Embed3(FViT2))∈R16H×16W×4C(3)
分别。其中, X ∈ R H × W × 3 X\in\mathbb{R}^{H\times W\times3} X∈RH×W×3为输入图像, P a t c h _ E m b e d j ( ⋅ ) Patch\_Embed_j(\cdot) Patch_Embedj(⋅)为𝑗th阶段的补丁嵌入层,𝑇𝐿𝑗(⋅)为 j ∈ { 1 , 2 , 3 } j\in\{1,2,3\} j∈{ 1,2,3}在𝑗th阶段的ViT特征。
对于另一个分支,我们采用ResNet[21]作为骨干网来捕获图像的局部细节。
我们分别按4、8和16的因子进行降采样,以确保ResNet提取的局部信息与由变压器支路。我们可以这样描述CNN分支:
F C N N 1 = R L 1 ( X ) ∈ R H 4 × W 4 × C ′ F C N N 2 = R L 2 ( F C N N 1 ) ∈ R H 8 × W 8 × 2 C ′ F C N N 3 = R L 3 ( F C N N 2 ) ∈ R H 16 × W 16 × 4 C ′ \begin{aligned}F_{CNN}^1&=RL_1(X)\in\mathbb{R}^{\frac{H}{4}\times\frac{W}{4}\times C^{\prime}}\\\\F_{CNN}^2&=RL_2(F_{CNN}^1)\in\mathbb{R}^{\frac{H}{8}\times\frac{W}{8}\times2C^{\prime}}\\\\\\F_{CNN}^3&=RL_3(F_{CNN}^2)\in\mathbb{R}^{\frac{H}{16}\times\frac{W}{16}\times4C^{\prime}}\end{aligned} FCNN1FCNN2FCNN3=RL1(X)∈R4H×4W×C′=RL2(FCNN1)∈R8H×8W×2C′=RL3(FCNN2)∈R16H×16W×4C′
分别。其中, X ∈ R H × W × 3 X\in\mathbb{R}^{H\times W\times3} X∈RH×W×3为输入图像,𝑅𝐿(⋅)表示 i ∈ { 1 , 2 , 3 } i\in\{1,2,3\} i∈{ 1,2,3}在𝑖th阶段的CNN分支特征。
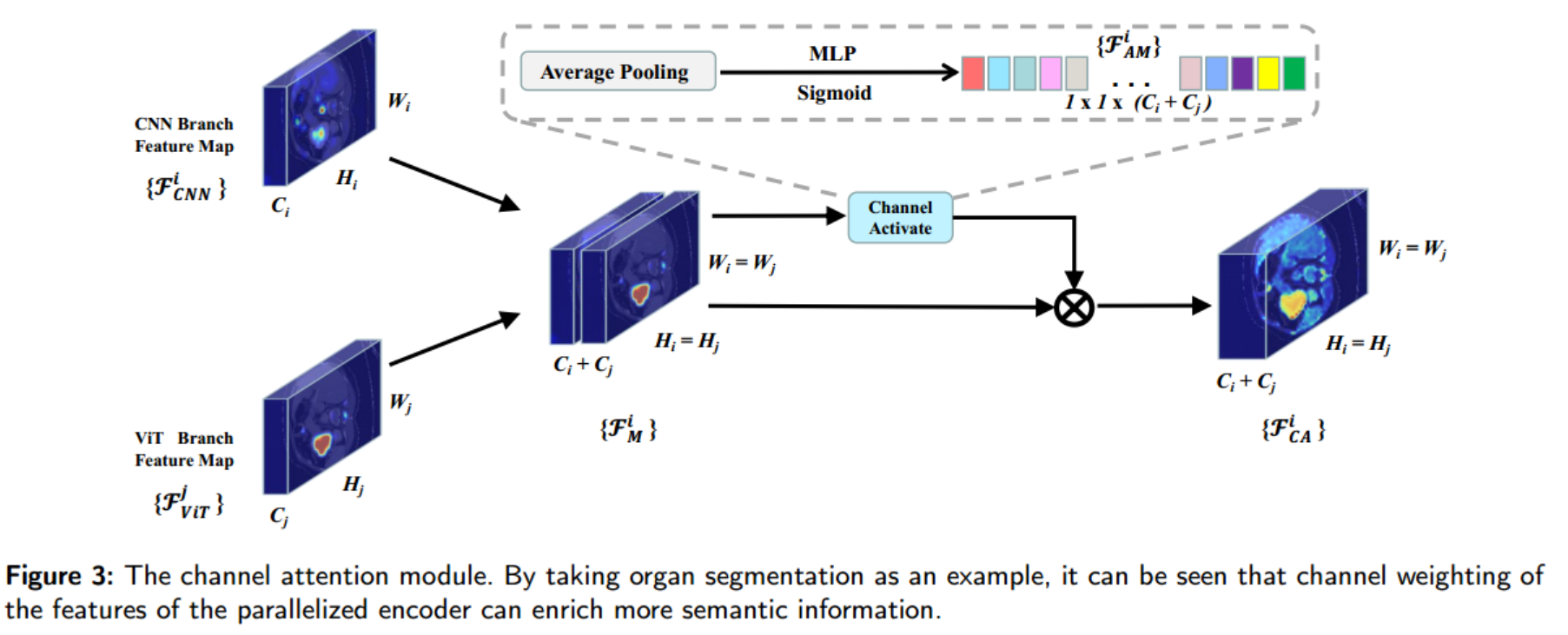
3.2 通道注意力模块
我们引入了一个通道关注模块(见图3),将从CNN和Transformer分支获得的局部和全局信息结合起来,使有价值的信息可以从并行化的编码器传递到解码器,从而得到像素级分割结果。由于简单的卷积运算不足以有效地融合局部和全局特征,我们根据特征通道的信息含量对其进行加权。通过激活有助于分割结果的通道并抑制不相关的通道,我们利用编码器的局部和全局信息实现有效的特征融合。
更具体地说,我们连接这些特征 F C N N i ∈ R H i × W i × C i F_{CNN}^{i}\in \mathbb{R}^{H_i\times W_i\times C_i} FCNNi∈RHi×Wi×Ci从CNN分支和 F V i T j ∈ R H j × W j × C j F_{ViT}^{j}\in\mathbb{R}^{H_{j}\times W_{j}\times C_{j}} FViTj∈RHj×Wj×Cj从变压器分支获得合并后的特性 F M i ∈ R H i × W i × ( C i + C j ) F_{M}^{i}\in\mathbb{R}^{H_{i}\times W_{i}\times(C_{i}+C_{j})} FMi∈RHi×Wi×(Ci+Cj),这是由于:
F M i = C o n c a t [ F C N N i , F V i T j ] F_{M}^{i}=Concat[F_{CNN}^{i},F_{ViT}^{j}] FMi=Concat[FCNNi,FViTj]
接下来,我们利用平均池化来获取信道信息的表示,然后应用多层感知器和sigmoid激活函数对信道表示进行非线性变换,得到一个信道注意图(1×1×(+𝑗))。
随后,我们使用合并的特征变量变量 对频道注意图(channel attention map)进行元素乘法,为不同的频道分配不同的权重,以激活来自并行化编码器的有用信息并抑制无关信息。这导致𝐹𝑖𝐶𝐴∈ℝ𝐻𝑖×𝑊𝑖×(𝐶𝑖+𝐶𝑗),如下:
F C A i = ( F A M i ⊗ F M i ) F_{CA}^{i}=(F_{AM}^{i}\otimes F_{M}^{i}) FCAi=(FAMi⊗FMi)
如图3所示,经过通道注意模块处理的特征比来自任何单个分支的特征拥有更丰富的语义信息。
3.3 解码器
通过实现并行编码器和通道关注模块,实现了语义信息丰富的多尺度特征表示。与TransUNet类似,我们使用跳过连接来链接低分辨率特征到高分辨率特征,然后传递给解码器,以生成最终的分割掩码。解码器采用卷积层提取组合多尺度特征,包括3 × 3卷积、批处理归一化[25]和ReLU层。上采样操作使用转置卷积层执行,依次获得2x, 2x和4x上采样。值得注意的是,我们的解码器不包含任何额外的技术或策略,如残余连接[20]或深度监督[16]。此外,我们观察到合并变压器作为解码器不会产生任何显着的性能改进
3.4 损失函数
我们使用Dice loss和Cross Entropy作为loss function来训练我们的paratransnn网络,如下所示:
L = λ 1 L D i c e + λ 2 L C E {\mathcal L}=\lambda_{1}{\mathcal L}_{Dice}+\lambda_{2}{\mathcal L}_{CE} L=λ1LDice+λ2LCE
其中 L {\mathcal L} L为总损失,𝜆1和𝜆2分别代表不同的权重系数,实验设分别为0.5和0.5。