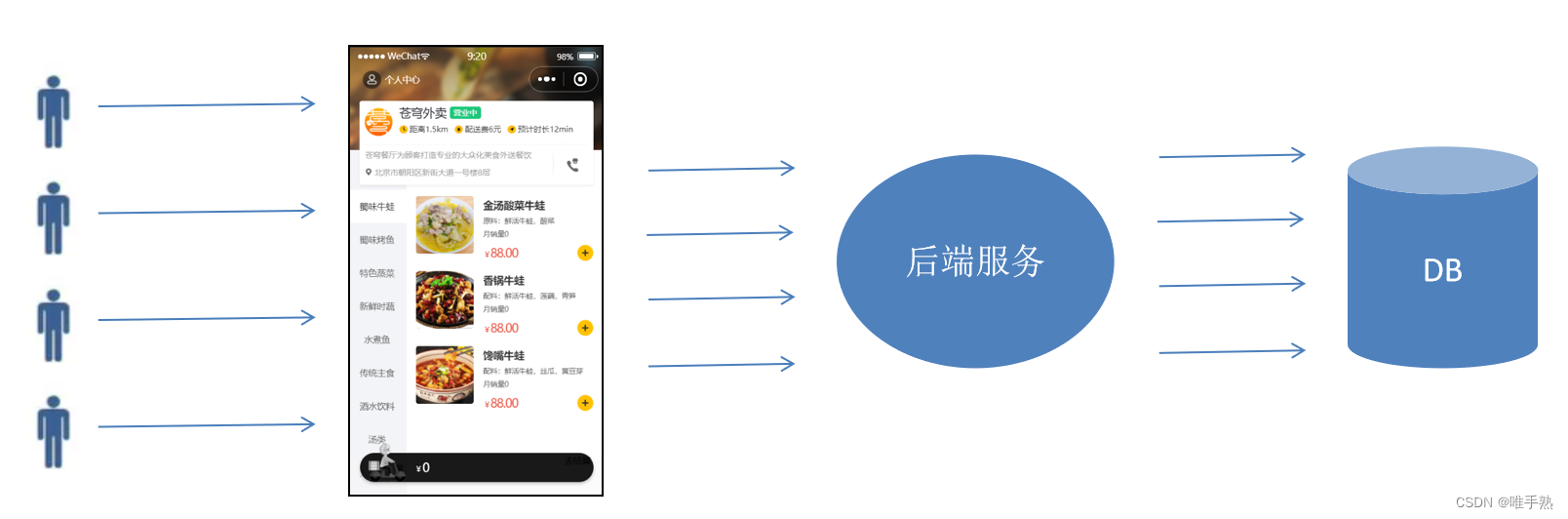
文章目录
机器学习中的过采样和欠采样
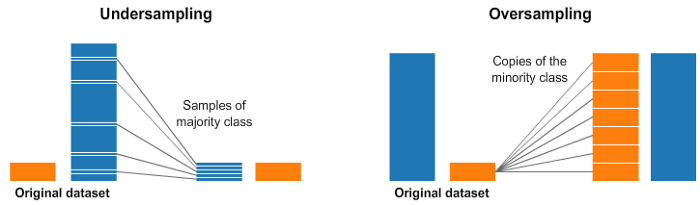
过采样
机器学习中的过采样和欠采样是两种常见的数据处理技术,用于解决不平衡数据集的问题。
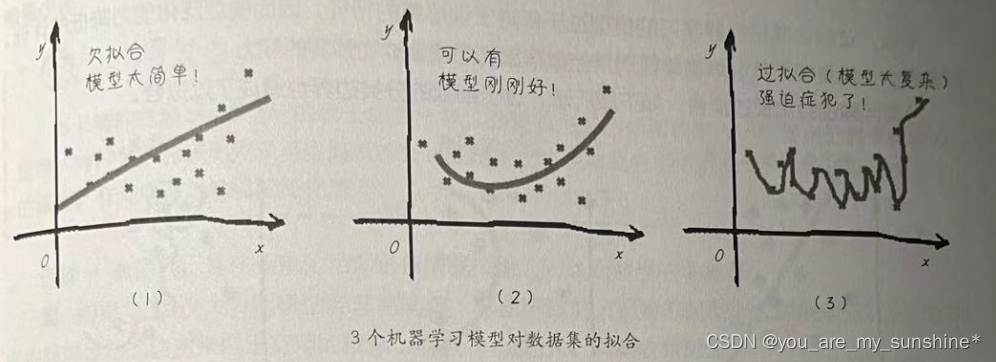
过采样(Oversampling)是指增加少数类样本的数量,以使其与多数类样本数量相当。这样可以帮助模型更好地学习少数类的特征,提高分类器对少数类的预测性能。过采样的方法包括复制样本、生成合成样本等。
- 复制样本:简单地复制少数类样本,使其数量增加到与多数类相当。这种方法简单但可能导致过拟合,因为复制的样本没有提供新的信息。
- 合成样本:使用一些生成算法,如
SMOTE(Synthetic Minority Oversampling Technique),通过对少数类样本进行插值来生成新的合成样本。
举个例子:
假设我们有一个二分类问题,原始数据集如下:
正例(少数类):100个样本
负例(多数类):200个样本
我们可使用SMOTE方法来生成合成样本,SMOTE的基本思想是通过对少数类样本之间的插值来生成新的合成样本。
| 步骤如下: |
|---|
| 1. 确定少数类样本。我们选择正例(少数类)样本作为少数类样本集合。 |
| 2. 选择合成样本。对于每个正例样本,我们选择其最近的K个邻居样本作为合成样本的生成候选。假设我们选择K=5。 |
| 3. 合成新样本。对于每个正例样本,我们从其5个最近邻居中随机选择一个样本,并使用线性插值生成新的合成样本。例如,假设我们从5个邻居中选择了一个邻居样本,并假设该邻居样本的特征向量为[1, 2, 3],而当前正例样本的特征向量为[4, 5, 6],则我们可以使用线性插值生成一个新的合成样本,例如**[2.5, 3.5, 4.5]**。 |
| 4. 添加合成样本。将生成的合成样本添加到原始数据集的正例样本中。 |
重复步骤2到步骤4,直到我们生成足够数量的合成样本。在这个例子中,我们可能选择生成100个合成样本,使得正例(少数类)的样本数量与负例(多数类)相当。
最终,我们得到平衡的数据集如下:
正例(少数类):200个样本(包括原始样本和合成样本)。
负例(多数类):200个样本。
使用平衡的数据集来训练机器学习模型可以更好地处理正例(少数类)的分类问题。
可以使用第三方库imbalanced-learn来实现过采样,可以使用以下函数:
RandomOverSampler:这个函数实现了随机过采样方法,通过复制少数类样本来增加其数量,以平衡类别分布。SMOTE:这个函数实现了SMOTE方法,通过合成新的少数类样本来增加其数量。
下面是一个使用imbalanced-learn库中的过采样函数的示例:
from imblearn.over_sampling import RandomOverSampler, SMOTE
import torch
from torch.utils.data import DataLoader
# 假设我们有一个不平衡的数据集
train_dataset = '数据集'
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 创建 RandomOverSampler 对象
over_sampler = RandomOverSampler()
# 使用 RandomOverSampler 进行过采样
oversampled_data, oversampled_labels = over_sampler.fit_resample(train_dataset.data, train_dataset.targets)
# 使用过采样后的数据训练模型
oversampled_dataset = torch.utils.data.TensorDataset(torch.tensor(oversampled_data), torch.tensor(oversampled_labels))
oversampled_loader = DataLoader(oversampled_dataset, batch_size=32, shuffle=True)
model.train()
for inputs, labels in oversampled_loader:
# 模型训练步骤
pass
# 或者使用SMOTE进行过采样
smote = SMOTE()
oversampled_data, oversampled_labels = smote.fit_resample(train_dataset.data, train_dataset.targets)
过采样可能会导致过拟合问题。
欠采样
欠采样(Undersampling)是指减少多数类样本的数量,以使其与少数类样本数量相当。这样可以减少多数类样本对模型的影响,提高对少数类的分类性能。欠采样的方法包括随机删除样本、聚类方法等。
- 随机删除样本:从多数类中随机选择一部分样本进行删除,以降低多数类的数量。这种方法简单快速,但可能会丢失一些重要信息。
- 聚类方法:使用聚类算法(如
K-means)将多数类样本聚类为较小的子集,然后从每个聚类中选择一个样本作为代表性样本。这样可以减少多数类样本数量,同时保留一些代表性样本。
可以使用imbalanced-learn第三方库来实现欠采样,可以使用以下函数:
RandomUnderSampler:这个函数实现了随机欠采样方法,通过随机选择多数类样本来减少其数量,以平衡类别分布。NearMiss:这个函数实现了基于距离的欠采样方法,根据少数类样本与多数类样本之间的距离进行样本选择。
使用imbalanced-learn库中的欠采样函数的示例:
from imblearn.under_sampling import RandomUnderSampler, NearMiss
import torch
from torch.utils.data import DataLoader
# 假设我们有一个不平衡的数据集
train_dataset = '数据集'
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 创建 RandomUnderSampler 对象
under_sampler = RandomUnderSampler()
# 使用 RandomUnderSampler 进行欠采样
undersampled_data, undersampled_labels = under_sampler.fit_resample(train_dataset.data, train_dataset.targets)
# 使用欠采样后的数据训练模型
undersampled_dataset = torch.utils.data.TensorDataset(torch.tensor(undersampled_data), torch.tensor(undersampled_labels))
undersampled_loader = DataLoader(undersampled_dataset, batch_size=32, shuffle=True)
model.train()
for inputs, labels in undersampled_loader:
# 模型训练步骤
pass
# 或者使用NearMiss进行欠采样
nearmiss = NearMiss()
undersampled_data, undersampled_labels = nearmiss.fit_resample(train_dataset.data, train_dataset.targets)
欠采样可能会导致丢失多数类样本的信息。




![[python数据处理系列] 深入理解与实践基于聚类<span style='color:red;'>的</span><span style='color:red;'>过</span><span style='color:red;'>采样</span>与<span style='color:red;'>欠</span><span style='color:red;'>采样</span>技术:以K-Means为例](https://img-blog.csdnimg.cn/direct/4b9793bac5b74515b354a4662040b7a2.png)