基本概念
我们知道,所谓的神经网络其实就是一个复杂的非线性函数,网络越深,这个函数就越复杂,相应的表达能力也就越强,神经网络的训练则是一个拟合的过程。
当模型的复杂度小于真实数据的复杂度,模型表达能力不够,不足以表达真实数据,这种情况就叫欠拟合,其典型表现是即使是在训练集上依然达不到一个很好的水平,准确度和loss都比较差。欠拟合可以通过增加模型复杂度来改善。
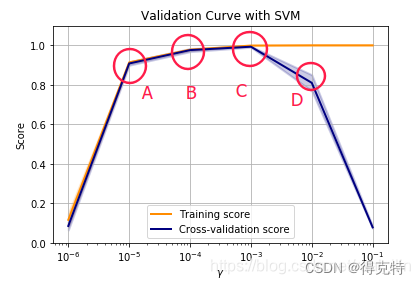
但是,当模型过于复杂时,拟合能力过强,这就会导致模型拟合了训练集中的一些噪声点,在测试集上的性能反而不强,这就造成了过拟合现象,其典型表现是在训练集上的性能逐渐变强(损失还在下降),但是在测试集上的损失开始稳定上升。下图中的三种曲线分别代表了欠拟合、好的拟合和过拟合三种情况:

如何应对?
应对过拟合
解决过拟合最好的方法就是获取更多的训练数据。只要给足够多的数据,让模型学习尽可能多的情况,它就会不断修正自己,从而获得更强的性能。但是在实验的过程中,获取有效的数据往往是非常困难的,或者说我们需要使用固定的数据集。那么除了就需要在代码上下点功夫。
可以通过正则化的方法约束模型权重,在机器学习中最常使用的是 L2正则化,L2正则损失对于大数值的权值向量进行严厉惩罚,鼓励更加分散的权重向量,使模型倾向于使用所有输入特征做决策,此时的模型泛化性能好。
添加Dropout随机失活层,训练过程中,对某一层使用Dropout,就是随机将该层的一些输出舍弃(输出值设置为0),这些被舍弃的神经元就好像被网络删除了一样。随机失活使得每次更新梯度时参与计算的网络参数减少了,降低了模型容量,所以能防止过拟合。并且随机失活鼓励权重分散,从这个角度来看随机失活也能起到正则化的作用,进而防止过拟合。
应对欠拟合
上述操作的反向操作,如果不行,那就说明模型的学习能力不够强。