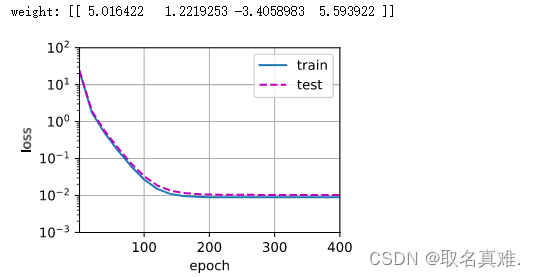
在监督学习中,想要在训练数据上构建模型,然后对没见过的新数据做出准确预测,如果一个模型能够对没见过的数据做出准确预测,我们就说它可以从训练集泛化到测试集。
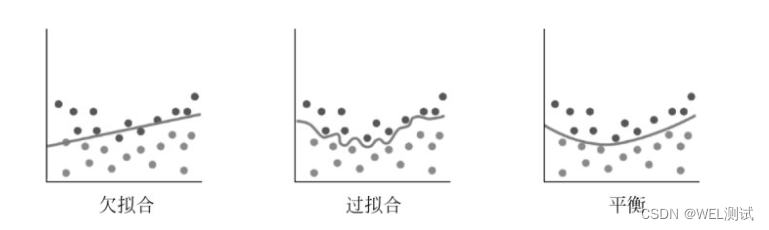
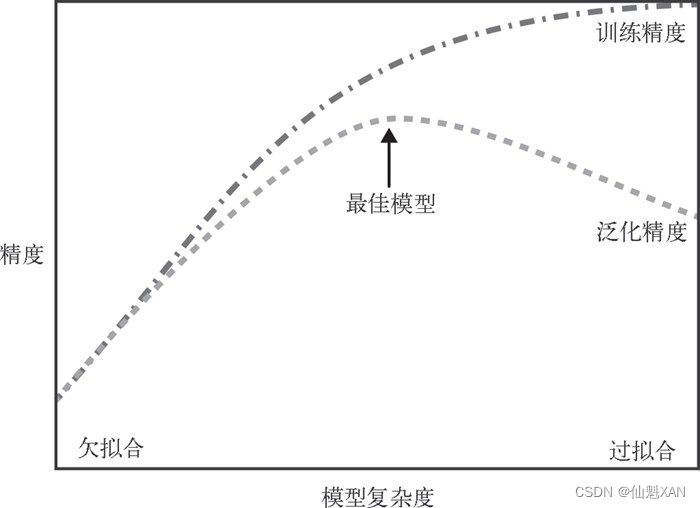
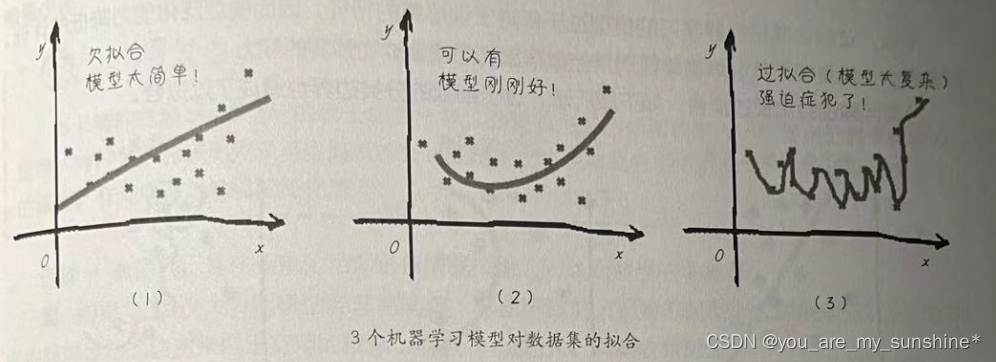
判断一个算法在新数据上表现好坏的唯一度量,就是在测试集上的评估。如果构建了一个对于现有数据量来说过于复杂的模型,这被称为过拟合。
如果模型过于简单,不能抓住数据的全部内容以及数据中的变化,甚至在训练集上的表现就很差,就被称为欠拟合。
模型越复杂,在训练数据上的预测结果就越好,但是模型过于复杂,过多关注训练集中的每个单独数据点,模型就不能很好的泛化到新数据上。