Spark概述
Spark是什么
- Apache Spark是一个快速的,多用途的集群计算系统,相对于Hadoop MapReduce将中间结果保存在磁盘中,Spark使用了内存保存中间结果,能在数据尚未写入硬盘时在内存中进行运算
- Spark只是一个计算框架,不像Hadoop一样包含了分布式文件系统和完备的调度系统,如果要使用Spark,需要搭载其它的文件系统和更成熟的调度系统
Spark特点
速度快
- Spark的在内存时的运行速度是Hadoop MapReduce的100倍
- 基于硬盘的运算速度大概是Hadoop MapReduce的10倍
- Spark实现了一种叫做RDDs的DAG执行引擎,其数据缓存在内存中可以进行迭代处理
易用
Spark支持Java,Scala,Python,R,SQL等多种语言的API
Spark支持超过80个高级运算符使得用户非常轻易的构建并行计算程序
Spark可以使用基于Scala,Python,R,SQL的Shell交互式查询.
df = spark.read.json("logs.json") df.where("age > 21") \ .select("name.first") \ .show()
通用
- Spark提供一个完整的技术栈,包括SQL执行,Dataset命令式API,机器学习库MLlib,图计算框架GraphX,流计算SparkStreaming
- 用户可以在同一个应用中同时使用这些工具,这一点是划时代的
兼容
- Spark可以运行在Hadoop Yarn,Apache Mesos,.Kubernets,Spark Standalone等集群中
- Spark可以访问HBase,HDFS,Hive,Cassandra在内的多种数据库
总结
- 支持Java,Scala,Python和R的API
- 可扩展至超过8K个节点
- 能够在内存中缓存数据集,以实现交互式数据分析
- 提供命令行窗口,减少探索式的数据分析的反应时间
Spark组成
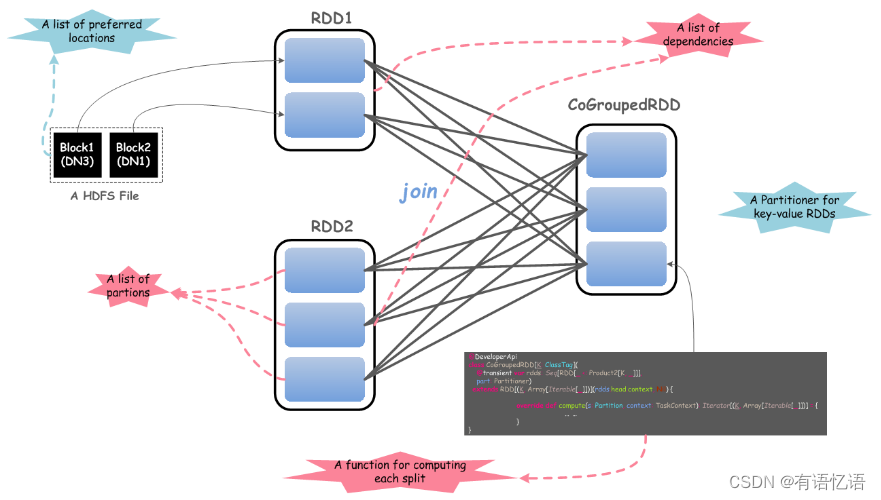
- Spark-Core和弹性分布式数据集(RDDs)
- Spark-Core是整个Spark的基础,提供了分布式任务调度和基本的 I/O 功能
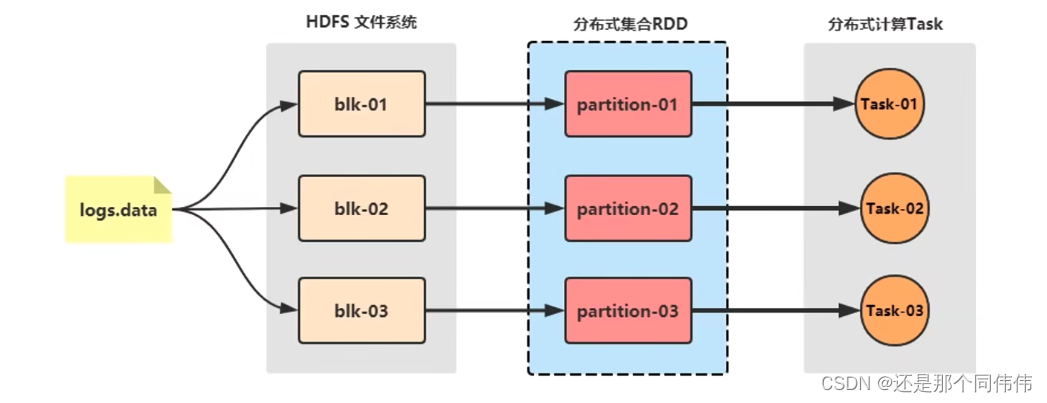
- Spark的基础的程序抽象是弹性分布式数据集(RDDs),是一个可以并行操作,有容错的数据集合
- RDDs 可以通过引用外部存储系统的数据集创建(如HDFS, HBase),或者通过现有的 RDDs 转换得到
- RDDs 抽象提供了Java, Scala, Python等语言的API
- RDDs 简化了编程复杂性,操作 RDDs 类似通过 Scala 或者 Java8 的 Streaming 操作本地数据集合
- Spark SQL
- Spark SQL 在 spark-core 基础之上带出了一个名为 DataSet 和 DataFrame 的数据抽象化的概念
- Spark SQL 提供了在 Dataset 和 DataFrame 之上执行 SQL 的能力
- Spark SQL 提供了 DSL, 可以通过 Scala,Java,Python 等语言操作 DataSet 和 DataFrame
- 它还支持使用 JDBC/ODBC 服务器操作 SQL 语言
- Spark Streaming
- Spark Streaming 充分利用 spark-core 的快速调度能力来运行流分析
- 它截取小批量的数据并可以对之运行 RDD Transformation
- 它提供了在同一个程序中同时使用流分析和批量分析的能力
- MLlib
- MLlib 是 Spark 上分布式机器学习的框架. Spark 分布式内存的架构 比 Hadoop 磁盘式的 Apache Mahout 快上10倍,扩展性也非常优良
- MLlib 可以使用许多常见的机器学习和统计算法,简化大规模机器学习
- 汇总统计,相关性,分层抽样,假设检定,随即数据生成
- 支持向量机,回归,线性回归,逻辑回归,决策树,朴素贝叶斯
- 协同过滤,ALS
- K-means
- SVD 奇异值分解,PCA 主成分分析
- TF-IDF , Word2Vec , StandardScaler
- SGD随机梯度下降,L-BFGS
- Graphx
- GraphX 是分布式图计算框架,提供了一组可以表达图计算的APL,GraphX还对这种抽象化提供了优化运行
- 总结
Spark 提供了批处理 (RDDs), 结构化查询 (DataFrame),流计算 (SparkStreaming),机器学习 (MLlib), 图计算(GraphX)等组件
这些组件均是依托于通用的计算引擎 RDDs 而构建出的,所以 spark-core 的 RDDs 是整个 Spark 的基础
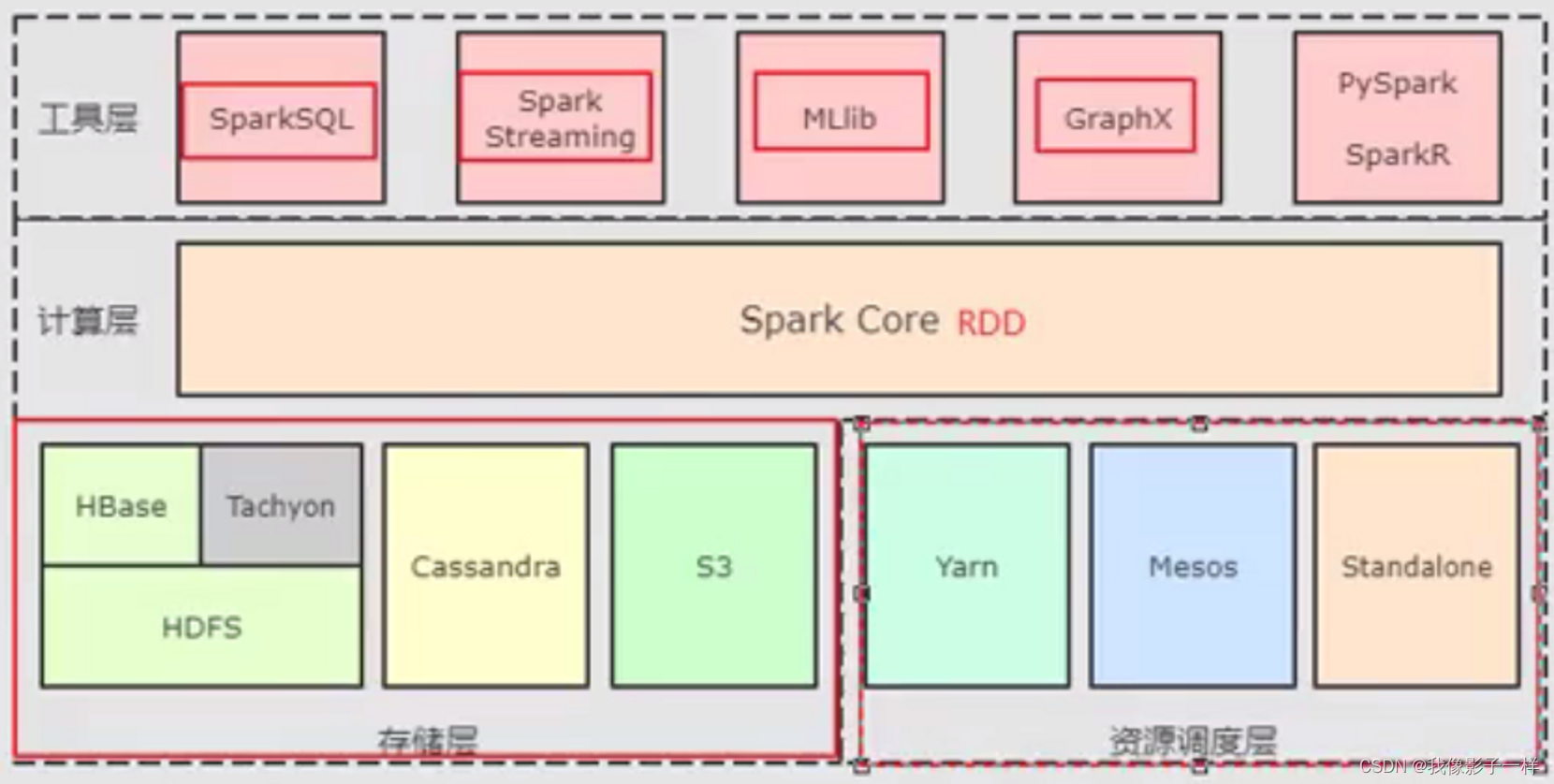
- Spark-Core和弹性分布式数据集(RDDs)
Spark和Hadoop之间的关系
Hadoop Spark 类型 基础平台,包含计算,存储,调度 分布式计算工具 场景 大规模数据集上的批处理 迭代计算,交互式计算,流计算 延迟 大 小 易用性 API较为底层,算法适应性差 API较为顶层,方便使用 价格 对机器要求低,便宜 对内存有要求,相对较贵