信息增益(Information Gain)
信息增益是衡量在特征选择过程中一个特征对数据集分类能力提升的指标。在构建决策树(如ID3和C4.5算法)时,信息增益用于选择最佳的特征来划分数据集。信息增益基于熵的概念,通过减少数据集的不确定性来衡量特征的重要性。
熵(Entropy)
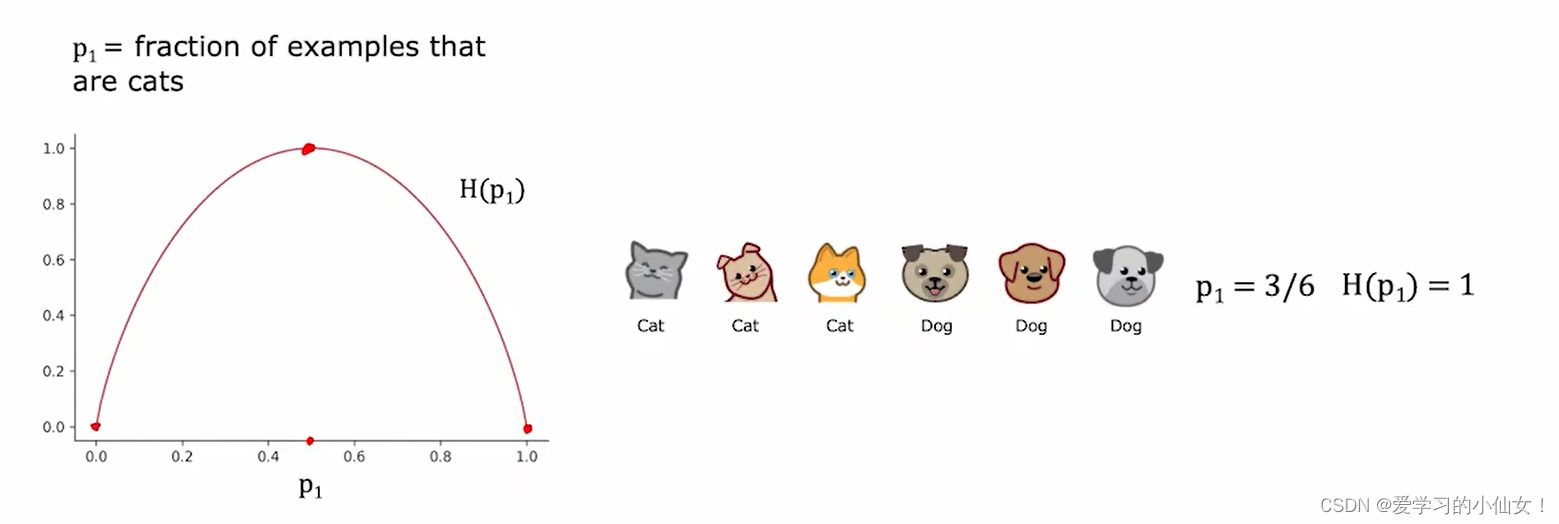
熵是信息理论中的一个概念,用于衡量系统的无序程度或不确定性。在分类问题中,熵可以用来表示数据集的纯度。熵的定义如下:
H ( D ) = − ∑ i = 1 n p i log 2 ( p i ) H(D) = - \sum_{i=1}^{n} p_i \log_2(p_i) H(D)=−i=1∑npilog2(pi)
其中:
- H ( D ) H(D) H(D) 是数据集 D D D 的熵。
- p i p_i pi 是数据集中第 i i i 类样本所占的比例。
- n n n 是类别的总数。
条件熵(Conditional Entropy)
条件熵衡量在给定特征 A A A 的条件下数据集 D D D 的不确定性。条件熵的定义如下:
H ( D ∣ A ) = ∑ v ∈ Values ( A ) ∣ D v ∣ ∣ D ∣ H ( D v ) H(D|A) = \sum_{v \in \text{Values}(A)} \frac{|D_v|}{|D|} H(D_v) H(D∣A)=v∈Values(A)∑∣D∣∣Dv∣H(Dv)
其中:
- Values ( A ) \text{Values}(A) Values(A) 是特征 A A A 的所有可能取值。
- D v D_v Dv 是数据集中特征 A A A 取值为 v v v 的子集。
- ∣ D ∣ |D| ∣D∣ 是数据集 D D D 的样本总数。
- ∣ D v ∣ |D_v| ∣Dv∣ 是子集 D v D_v Dv 的样本总数。
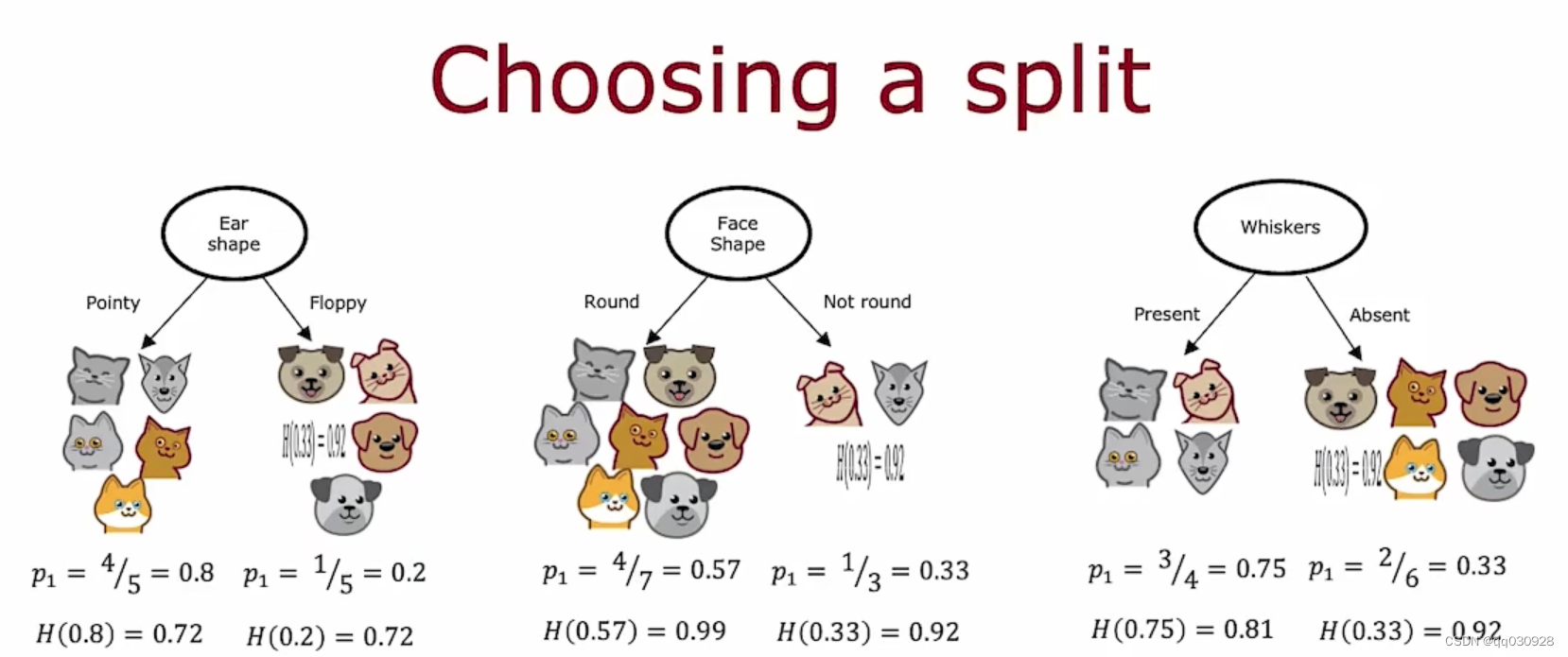
熵值和基尼系数是两种不同的概念,尽管它们都可以用来衡量不确定性或不纯度,但它们的计算方法和应用领域有所不同。下面详细解释两者:
基尼系数(Gini Index)
基尼系数,或者称为基尼不纯度,是另一种衡量分类问题中数据不纯度的方法。它的定义如下:
G ( X ) = 1 − ∑ i = 1 n P ( x i ) 2 G(X) = 1 - \sum_{i=1}^{n} P(x_i)^2 G(X)=1−i=1∑nP(xi)2
其中:
- G ( X ) G(X) G(X) 是随机变量 X X X 的基尼系数。
- P ( x i ) P(x_i) P(xi) 是事件 x i x_i xi发生的概率。
在机器学习中,基尼系数通常用于决策树算法中的CART(分类与回归树)模型,用来选择最佳的特征进行数据划分。基尼系数越小,数据集的纯度越高。
熵与基尼系数的区别
定义和计算方法:
- 熵是通过概率的对数计算得出的。
- 基尼系数是通过概率的平方和计算得出的。
应用领域:
- 熵主要用于信息增益的计算,常见于ID3和C4.5决策树算法。
- 基尼系数常用于CART决策树算法。
特性:
- 熵能够更细腻地刻画不确定性,考虑了事件发生的概率及其对数。
- 基尼系数计算更简单,直接反映数据的纯度。
示例
假设有一个数据集,其中包含两类数据,类别分别为A和B。
- 类别A的概率 (P(A) = 0.6)
- 类别B的概率 (P(B) = 0.4)
则熵和基尼系数的计算如下:
熵的计算
H ( X ) = − ( 0.6 log 2 0.6 + 0.4 log 2 0.4 ) ≈ 0.97095 H(X) = - (0.6 \log_2 0.6 + 0.4 \log_2 0.4) \approx 0.97095 H(X)=−(0.6log20.6+0.4log20.4)≈0.97095
基尼系数的计算
G ( X ) = 1 − ( 0. 6 2 + 0. 4 2 ) = 1 − ( 0.36 + 0.16 ) = 1 − 0.52 = 0.48 G(X) = 1 - (0.6^2 + 0.4^2) = 1 - (0.36 + 0.16) = 1 - 0.52 = 0.48 G(X)=1−(0.62+0.42)=1−(0.36+0.16)=1−0.52=0.48
从上述计算可以看出,虽然熵和基尼系数都在一定程度上反映了数据的不纯度,但它们的值和含义有所不同。
熵和基尼系数都是衡量数据不纯度的重要指标,但它们的计算方法和应用场景有所不同。熵强调信息的不确定性,适用于信息增益的计算,而基尼系数则更加直接地反映了数据的纯度,常用于CART算法中。
信息增益(Information Gain)
信息增益表示通过特征 A A A 划分数据集 D D D 后,数据集 D D D 的熵减少的程度。信息增益的定义如下:
I G ( D , A ) = H ( D ) − H ( D ∣ A ) IG(D, A) = H(D) - H(D|A) IG(D,A)=H(D)−H(D∣A)
其中:
- I G ( D , A ) IG(D, A) IG(D,A) 是特征 A A A 对数据集 D D D 的信息增益。
- H ( D ) H(D) H(D) 是数据集 D D D 的熵。
- H ( D ∣ A ) H(D|A) H(D∣A) 是在特征 A A A 的条件下数据集 D D D 的条件熵。
信息增益的计算步骤
计算数据集的熵 H ( D ) H(D) H(D):
首先计算整个数据集的熵,表示当前数据集的不确定性。计算特征 A A A 的条件熵 H ( D ∣ A ) H(D|A) H(D∣A):
根据特征 A A A 的取值,将数据集划分为若干子集,然后计算每个子集的熵,并加权求和得到条件熵。计算信息增益 I G ( D , A ) IG(D, A) IG(D,A):
用数据集的熵减去条件熵,得到信息增益。
示例
假设有一个简单的数据集如下:
| 天气 | 玩耍 |
|---|---|
| 晴天 | 是 |
| 阴天 | 是 |
| 雨天 | 否 |
| 晴天 | 是 |
| 晴天 | 否 |
| 阴天 | 否 |
| 阴天 | 是 |
| 雨天 | 否 |
我们需要计算“天气”特征的信息增益。
- 计算数据集的熵 H ( D ) H(D) H(D):
H ( D ) = − ( 4 8 log 2 4 8 + 4 8 log 2 4 8 ) = 1 H(D) = -\left(\frac{4}{8} \log_2 \frac{4}{8} + \frac{4}{8} \log_2 \frac{4}{8}\right) = 1 H(D)=−(84log284+84log284)=1
2. 计算特征“天气”的条件熵 H ( D ∣ 天气 ) H(D|\text{天气}) H(D∣天气):
H ( D ∣ 天气 ) = ∑ v ∈ { 晴天, 阴天, 雨天 } ∣ D v ∣ ∣ D ∣ H ( D v ) H(D|\text{天气}) = \sum_{v \in \{\text{晴天, 阴天, 雨天}\}} \frac{|D_v|}{|D|} H(D_v) H(D∣天气)=v∈{晴天, 阴天, 雨天}∑∣D∣∣Dv∣H(Dv)
其中:
- ∣ D 晴天 ∣ = 3 |D_{\text{晴天}}| = 3 ∣D晴天∣=3,且 H ( D 晴天 ) = − ( 2 3 log 2 2 3 + 1 3 log 2 1 3 ) ≈ 0.918 H(D_{\text{晴天}}) = -\left(\frac{2}{3} \log_2 \frac{2}{3} + \frac{1}{3} \log_2 \frac{1}{3}\right) \approx 0.918 H(D晴天)=−(32log232+31log231)≈0.918
- ∣ D 阴天 ∣ = 3 |D_{\text{阴天}}| = 3 ∣D阴天∣=3,且 H ( D 阴天 ) = − ( 2 3 log 2 2 3 + 1 3 log 2 1 3 ) ≈ 0.918 H(D_{\text{阴天}}) = -\left(\frac{2}{3} \log_2 \frac{2}{3} + \frac{1}{3} \log_2 \frac{1}{3}\right) \approx 0.918 H(D阴天)=−(32log232+31log231)≈0.918
- ∣ D 雨天 ∣ = 2 |D_{\text{雨天}}| = 2 ∣D雨天∣=2,且 H ( D 雨天 ) = − ( 0 log 2 0 + 1 log 2 1 ) = 0 H(D_{\text{雨天}}) = -\left(0 \log_2 0 + 1 \log_2 1\right) = 0 H(D雨天)=−(0log20+1log21)=0
H ( D ∣ 天气 ) = ( 3 8 × 0.918 + 3 8 × 0.918 + 2 8 × 0 ) ≈ 0.688 H(D|\text{天气}) = \left(\frac{3}{8} \times 0.918 + \frac{3}{8} \times 0.918 + \frac{2}{8} \times 0\right) \approx 0.688 H(D∣天气)=(83×0.918+83×0.918+82×0)≈0.688
- 计算信息增益 I G ( D , 天气 ) IG(D, \text{天气}) IG(D,天气):
I G ( D , 天气 ) = H ( D ) − H ( D ∣ 天气 ) = 1 − 0.688 = 0.312 IG(D, \text{天气}) = H(D) - H(D|\text{天气}) = 1 - 0.688 = 0.312 IG(D,天气)=H(D)−H(D∣天气)=1−0.688=0.312
总结
信息增益通过减少数据集的不确定性来选择特征,选择信息增益最大的特征作为划分标准。它在构建决策树的过程中起到了重要作用,有助于选择最能区分数据的特征。