文章目录
1. 数据增强
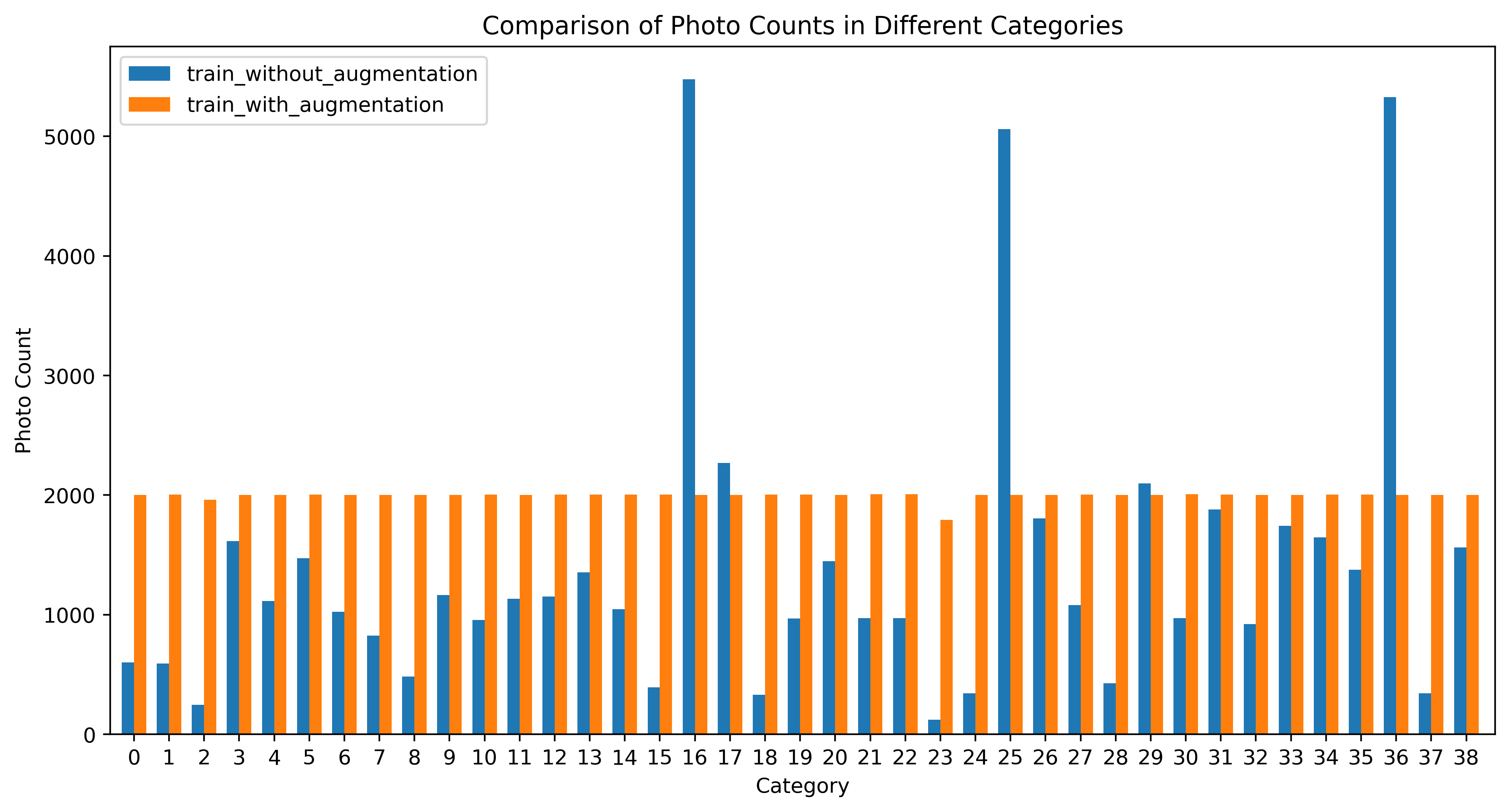
什么是数据增强?数据增强是优化数据吗?这种说法并不尽然。首先,数据增强的做法偏向于生成新样本。它是通过对现有数据进行各种变换和处理来生成新的训练样本,从而增加数据集的多样性和数量。但是不会直接修改原始数据集。这样,有助于防止过拟合情况的发生,提高模型的泛化能力。
这是一个偏人工的过程,需要模拟真实世界中的变化,拿视频来说,我们可能需要去掉滤镜效果,计算拍摄视角、光照或者是遮挡。使得特征表示更加具有鲁棒性。

2. 数据增强技巧
官方笔记推荐我们使用PyTorch来做数据增强,列举了一些数据增强技巧。我个人认为这些技巧本身已经比较好了,于是再补充一下我认识到的另一些技巧。
torchvision
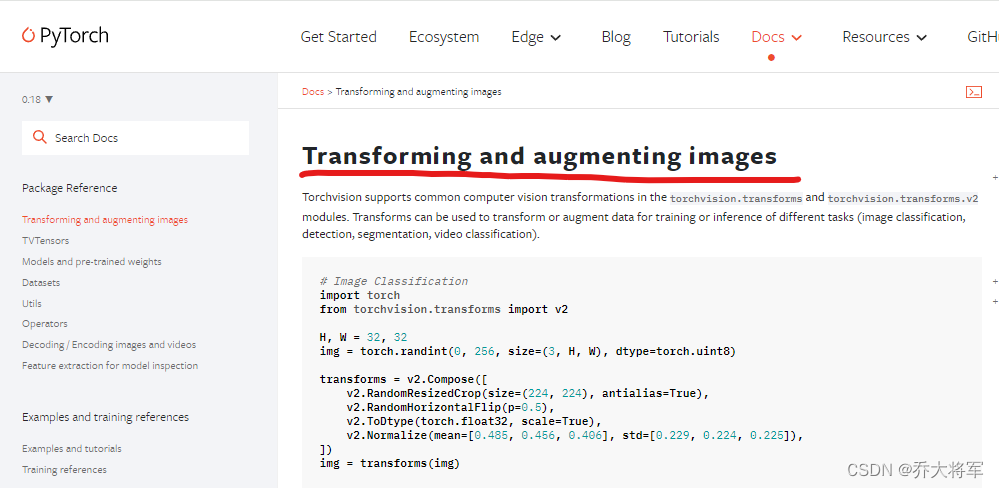
文档库地址:https://pytorch.org/vision/stable/index.html
PyTorch其实更希望我们使用v2,所以如果把resize函数重写成V2格式就是这样:
2.1 图像大小调整
transforms.Resize((256, 256))
默认参数:
torchvision.transforms.Resize(size, interpolation=InterpolationMode.BILINEAR, max_size=None, antialias=True)
2.2 图像旋转
transforms.RandomHorizontalFlip()
# 写成V2版本
torchvision.transforms.v2.RandomHorizontalFlip(p: float = 0.5)
# 垂直反转
torchvision.transforms.v2.RandomVerticalFlip(p: float = 0.5)
2.3 图像转换为张量
transforms.ToTensor()
# 将图像数据转换为PyTorch的Tensor格式,这是在深度学习中处理图像数据的常用格式。
torchvision.transforms.v2.ToTensor
2.4 归一化
# 归一化
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
# 对图像进行归一化处理,这里的均值和标准差是根据ImageNet数据集计算得出的,用于将图像像素值标准化,这有助于模型的训练稳定性和收敛速度。
# 写成V2版本
torchvision.transforms.v2.Normalize(mean: Sequence[float], std: Sequence[float], inplace: bool = False)
2.5 图像裁剪
# 随机裁剪
torchvision.transforms.v2.RandomCrop(size: Union[int, Sequence[int]], padding: Optional[Union[int, Sequence[int]]] = None, pad_if_needed: bool = False, fill: Union[int, float, Sequence[int], Sequence[float], None, Dict[Union[Type, str], Optional[Union[int, float, Sequence[int], Sequence[float]]]]] = 0, padding_mode: Literal['constant', 'edge', 'reflect', 'symmetric'] = 'constant')
# 中心裁剪
torchvision.transforms.v2.CenterCrop(size: Union[int, Sequence[int]])
# 五裁剪和十裁剪
torchvision.transforms.v2.FiveCrop(size: Union[int, Sequence[int]])
torchvision.transforms.v2.TenCrop(size: Union[int, Sequence[int]], vertical_flip: bool = False)
2.6 仿射变换
图像仿射变换是一种在计算机视觉和图像处理领域中常用的变换技术,它用于对图像进行线性变换和仿射变换。通过仿射变换,可以对图像进行旋转、平移、缩放、剪切等操作,同时保持直线的直线性和原点的共线性。
相当于以上几个方法的集成版。
torchvision.transforms.v2.RandomAffine(degrees: Union[Number, Sequence], translate: Optional[Sequence[float]] = None, scale: Optional[Sequence[float]] = None, shear: Optional[Union[int, float, Sequence[float]]] = None, interpolation: Union[InterpolationMode, int] = InterpolationMode.NEAREST, fill: Union[int, float, Sequence[int], Sequence[float], None, Dict[Union[Type, str], Optional[Union[int, float, Sequence[int], Sequence[float]]]]] = 0, center: Optional[List[float]] = None)
2.7 透视变换
torchvision.transforms.v2.RandomAffine(degrees: Union[Number, Sequence], translate: Optional[Sequence[float]] = None, scale: Optional[Sequence[float]] = None, shear: Optional[Union[int, float, Sequence[float]]] = None, interpolation: Union[InterpolationMode, int] = InterpolationMode.NEAREST, fill: Union[int, float, Sequence[int], Sequence[float], None, Dict[Union[Type, str], Optional[Union[int, float, Sequence[int], Sequence[float]]]]] = 0, center: Optional[List[float]] = None)
3. 自动增强
# 自动增强
torchvision.transforms.v2.AutoAugment(policy: AutoAugmentPolicy = AutoAugmentPolicy.IMAGENET, interpolation: Union[InterpolationMode, int] = InterpolationMode.NEAREST, fill: Union[int, float, Sequence[int], Sequence[float], None, Dict[Union[Type, str], Optional[Union[int, float, Sequence[int], Sequence[float]]]]] = None)
# 随机增强
torchvision.transforms.v2.RandAugment(num_ops: int = 2, magnitude: int = 9, num_magnitude_bins: int = 31, interpolation: Union[InterpolationMode, int] = InterpolationMode.NEAREST, fill: Union[int, float, Sequence[int], Sequence[float], None, Dict[Union[Type, str], Optional[Union[int, float, Sequence[int], Sequence[float]]]]] = None)
4. Mixup增强
将两个图像按一定比例混合(类似于叠片),alpha就是这个比例。这样相当于通过图像的“加法”去丰富这个数据集。模型的泛化能力则能更强。

# alpha (float, optional) – hyperparameter of the Beta distribution used for mixup. Default is 1.
# alpha默认为1,它表示了两张图片混合的比例
torchvision.transforms.v2.MixUp(*, alpha: float = 1.0, num_classes: int, labels_getter='default')


















![[紧急!!!]20240719全球Windows10/11蓝屏问题,CrowdStrike导致的错误解决方案](https://i-blog.csdnimg.cn/direct/b6a4fd63ca0840f6a00d0fd15feb7654.png)