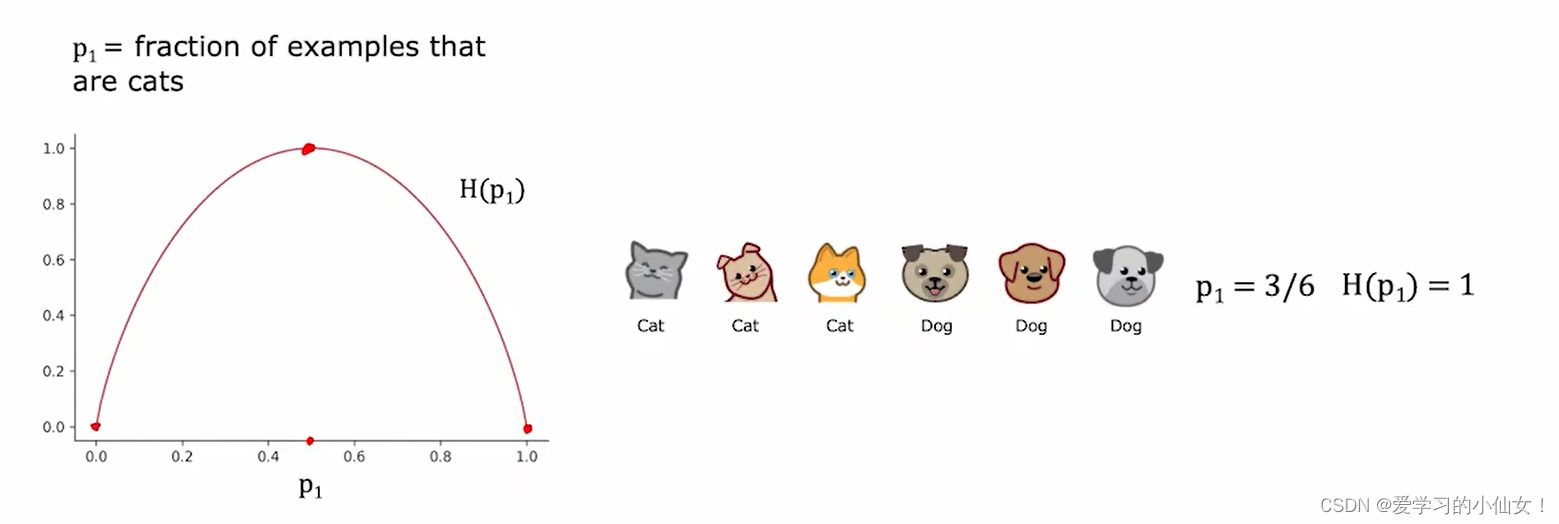
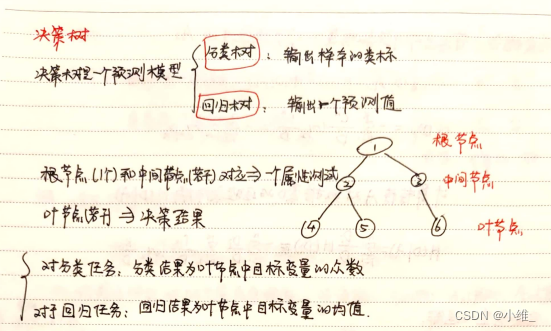
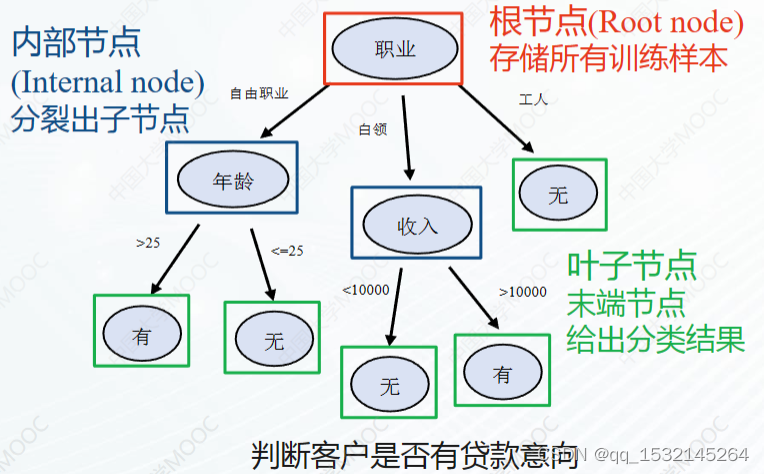
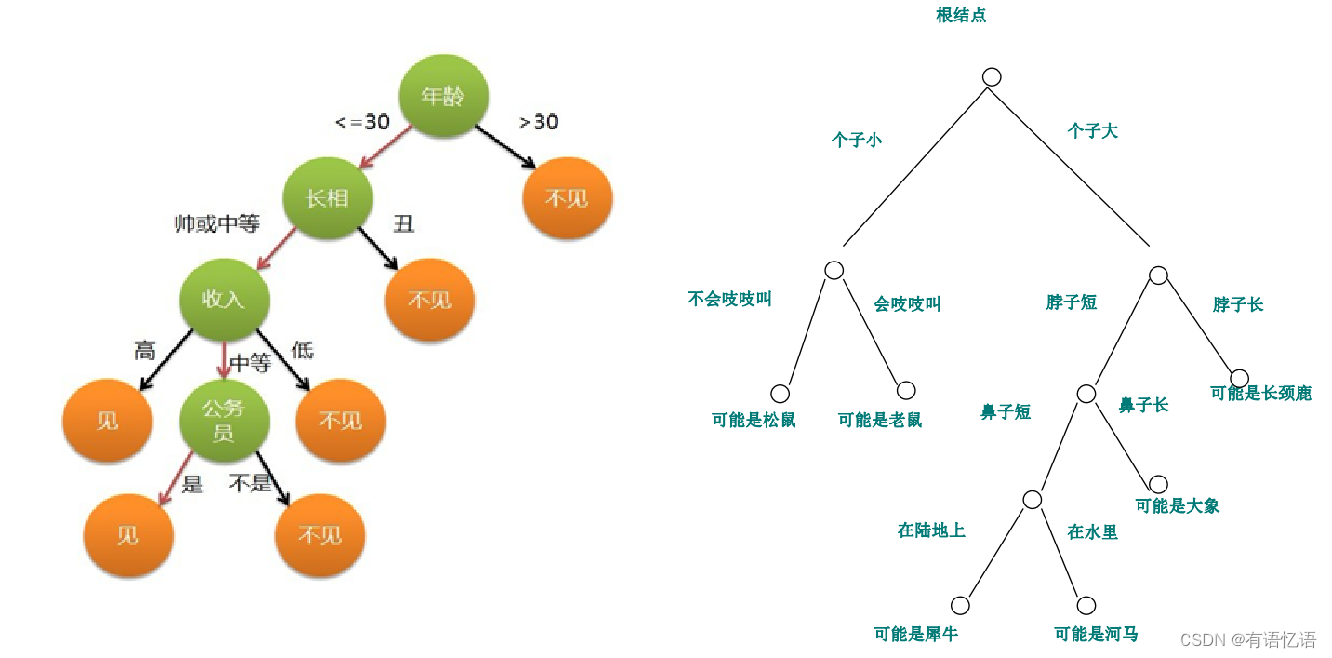
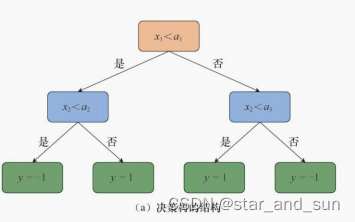
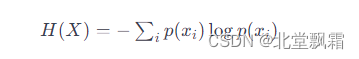如是我闻 :那你说决策树这块还能考点啥呢,也就是算算属性的信息增益(Information Gain)了,
信息增益是一种评估特征(属性)在分类任务中重要性的方法,它基于熵的概念来计算。熵是一个衡量数据集中不确定性或混乱程度的指标。信息增益则是衡量在知道某个属性的信息之后,数据集不确定性减少的程度
下面我们通过一道小练习题来用心感受一下这类题:
问题描述
在这个问题中,数据集包含了三个特征(A、B、C)和一个分类标签,任务是计算属性A对于分类结果的信息增益值,以此评估A在预测结果中的有效性和重要性。
原始数据:
| A | B | C | 标签 (L) |
|---|---|---|---|
| 1 | 1 | 0 | 1 |
| 1 | 1 | 1 | 2 |
| 0 | 0 | 1 | 1 |
| 0 | 1 | 1 | 1 |
解题步骤
信息增益的计算过程分为三个主要步骤:
- 计算整体数据集的熵(Initial Entropy)
- 计算在特定属性条件下的条件熵(Conditional Entropy)
- 计算信息增益(Information Gain)
步骤 1: 计算整体数据集的熵(Initial Entropy)
数据使用:
- 标签有三个1和一个2。
计算方法:
- 概率:
- P ( L = 1 ) = 3 4 P(\text{L}=1) = \frac{3}{4} P(L=1)=43
- P ( L = 2 ) = 1 4 P(\text{L}=2) = \frac{1}{4} P(L=2)=41
- 熵公式:
- H ( L ) = − ( 3 4 log 2 3 4 + 1 4 log 2 1 4 ) = 0.811 H(\text{L}) = -\left(\frac{3}{4}\log_2\frac{3}{4} + \frac{1}{4}\log_2\frac{1}{4}\right)=0.811 H(L)=−(43log243+41log241)=0.811
为什么要这么做:
熵是衡量数据集混乱程度的指标。这一步提供了一个基准,让我们可以比较是否属性的选择能降低这种混乱程度。
步骤 2: 计算属性 A 的条件熵(Conditional Entropy)
数据使用:
- 当 A = 1 A=1 A=1 时:有两个结果,一个是1,另一个是2。
- 当 A = 0 A=0 A=0 时:有两个结果,都是1。
计算方法:
- 当 A = 1 A=1 A=1 时:
- P ( L = 1 ∣ A = 1 ) = 1 2 P(\text{L}=1 | A=1) = \frac{1}{2} P(L=1∣A=1)=21
- P ( L = 2 ∣ A = 1 ) = 1 2 P(\text{L}=2 | A=1) = \frac{1}{2} P(L=2∣A=1)=21
- H ( L ∣ A = 1 ) = − ( 1 2 log 2 1 2 + 1 2 log 2 1 2 ) = 1.0 H(\text{L}|A=1) = -\left(\frac{1}{2}\log_2\frac{1}{2} + \frac{1}{2}\log_2\frac{1}{2}\right)=1.0 H(L∣A=1)=−(21log221+21log221)=1.0
- 当 A = 0 A=0 A=0 时:
- P ( L = 1 ∣ A = 0 ) = 1 P(\text{L}=1 | A=0) = 1 P(L=1∣A=0)=1
- H ( L ∣ A = 0 ) = − ( 1 log 2 1 ) = 0 H(\text{L}|A=0) = -(1\log_21) = 0 H(L∣A=0)=−(1log21)=0 (所有结果都是1,所以熵为0)
为什么要这么做:
条件熵 H ( L ∣ A ) H(\text{L}|A) H(L∣A) 表示已知属性 A 的值后,结果的不确定性。计算这个值是为了评估知道 A 后不确定性减少了多少。
步骤 3: 计算信息增益(Information Gain)
计算方法:
- 信息增益公式:
- I G ( A ) = H ( L ) − H ( L ∣ A ) = 0.311 IG(A) = H(\text{L}) - H(\text{L}|A)=0.311 IG(A)=H(L)−H(L∣A)=0.311
- H ( L ∣ A ) = 1 2 H ( L ∣ A = 1 ) + 1 2 H ( L ∣ A = 0 ) = 0.5 H(\text{L}|A) = \frac{1}{2}H(\text{L}|A=1) + \frac{1}{2}H(\text{L}|A=0) =0.5 H(L∣A)=21H(L∣A=1)+21H(L∣A=0)=0.5
为什么要这么做:
信息增益测量了在知道属性 A 的值之后,结果的不确定性减少了多少。如果信息增益高,意味着该属性在分类时非常有用,因为它能显著降低不确定性。
通过这种方式,我们计算得出属性 A 的信息增益为 0.311,显示它是一个对于降低结果预测不确定性有效的属性。下面开始技术总结
解题步骤总结
步骤 1: 理解数据和定义目标
- 数据理解:首先,明确每个属性和结果类别的数据结构和分布。
- 目标定义:明确你需要计算的是哪个属性的信息增益,以及最终目的是什么(例如,选择最好的属性进行数据分割)。
步骤 2: 计算整体数据集的熵
- 计算概率:为数据集中每个结果类别计算概率。
- 应用熵公式:
H ( X ) = − ∑ i = 1 n p i log 2 ( p i ) H(X) = -\sum_{i=1}^{n} p_i \log_2(p_i) H(X)=−i=1∑npilog2(pi)
其中 p i p_i pi是第 i i i类结果的概率。
步骤 3: 计算条件熵
- 分组数据:根据要计算信息增益的属性,将数据分成几组。
- 计算每组的熵:对每个分组,再次计算结果的概率和熵。
- 计算加权平均的条件熵:
H ( X ∣ A ) = ∑ j P ( A = a j ) H ( X ∣ A = a j ) H(X|A) = \sum_{j} P(A=a_j) H(X|A=a_j) H(X∣A)=j∑P(A=aj)H(X∣A=aj)
其中 a j a_j aj 是属性 A A A 的第 j j j个值, P ( A = a j ) P(A=a_j) P(A=aj) 是该值在数据集中的概率。
步骤 4: 计算信息增益
- 应用信息增益公式:
I G ( A ) = H ( X ) − H ( X ∣ A ) IG(A) = H(X) - H(X|A) IG(A)=H(X)−H(X∣A)
这里, I G ( A ) IG(A) IG(A) 是属性 A A A 的信息增益, H ( X ) H(X) H(X) 是数据集的熵, H ( X ∣ A ) H(X|A) H(X∣A) 是条件熵。
步骤 5: 解析和决策
- 比较和选择:如果比较多个属性的信息增益,选择信息增益最高的属性,因为它最能减少不确定性,最适合用来分割数据。
相信有了这个总结之后,小朋友们就再也不用怕决策树算信息增益的问题啦
非常的有品
以上