导读
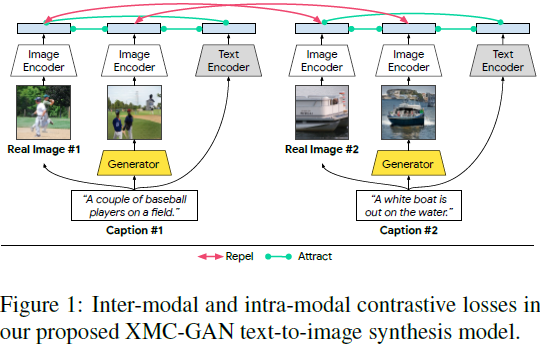
当人类从不同角度评估不同类型的图像时,偏好结果会有所不同。因此,为了学习多维的人类偏好,我们提出人类多元偏好模型(MPS),这是第一个评估文本生成图像的多维评分模型。MPS在3个公开数据集上表现出色,同时也在4个偏好维度上优于现有的评分方法,使其成为评估和改进文生图模型的核心指标。该模型和数据集已经公开,希望能促进文生图领域未来的发展研究。
一、论文解读
1.1 内容摘要
当前文本生成图像模型的评估通常依赖于统计指标,但这些指标不足以准确反映真实场景下的人类偏好。尽管最近有工作尝试通过人类标注的图像来学习这些偏好,但它们将多样化的人类偏好简化为单一的总体评分。然而,当人类从不同维度评估图像时,偏好结果会有所不同。因此,为了学习多维的人类偏好,我们提出了多维偏好模型(MPS),这是第一个用于评估文生图模型的多维偏好评分模型。

MPS通过在CLIP模型上引入了偏好条件模块,以学习这些多样化的偏好。它基于收集的的多维人类偏好(MHP)数据集进行训练,该数据集包括918,315个人类偏好打分,包含了美学、语义对齐、细节质量和整体评估四个维度。MPS在4个维度上优于现有的评分方法,在3个公开数据集上表现出色,使其成为评估和改进文生图模型的核心指标。
该模型和数据集已公开(见下方链接),我们衷心希望MPS能促进文生图社区未来的发展研究。
Project-page:
https://wangbohan97.github.io/MPS/
code:
https://github.com/Kwai-Kolors/MPS
1.2 研究背景
文生图模型近年来取得了显著的进步,用户可以输入文本描述(Prompt)来生成高相关性、高清晰度和高美感的图像。为了评估生成图像的质量,有工作提出了一些评估指标,包括IS、FID和CLIP得分。然而,这些统计指标与人类的感知偏好并不一致。例如,像IS或FID这样的指标,尽管在某种程度上指示了图像质量,但不一定能反映出人类将如何根据保真度、连贯性或美学吸引力来评价图像。
除了上述统计指标,HPS、PickScore、ImageReward、HPS_v2和AGIQ-1K等方法也提出了以人为中心的评估。这些方法首先对生成的图像标注人类偏好,随后使用这些偏好数据对模型进行训练以预测偏好得分。然而,这些方法通常使用单个分数来总结所有人类偏好,忽略了人类偏好的多维性。当人类从不同的角度评估图像时,他们对图像的偏好结果也会有所不同。因此,使用单一维度的评估方法不足以捕捉用户群体中广泛的个性化需求和偏好。为了确保对文本到图像合成输出进行全面评估,学习和利用多维人类偏好至关重要。
为了学习这种多维人类偏好,我们提出了多维人类偏好(MHP)数据集。与之前的工作相比,MHP数据集在Prompt收集、图像生成和偏好标注方面进行了更精心的设计。对于Prompt收集,以前的工作直接利用现有的开源数据集(例如DiffusionDB等),但是这些数据集通常忽略了长尾分布带来的潜在数据偏差。为此,基于Parti的类别模式,我们将收集到的Prompt标注为7个大类(例如:人物、动物、场景等)。对于代表性不足的尾部类别,我们使用大型语言模型(LLM)来生成额外的Prompt进行扩充,用于后续的图像生成。
对于图像生成,我们不仅利用现有的开源扩散模型,还使用生成对抗模型和自回归模型来生成图像。最终,我们生成了包含607541张图像的数据集,这些图像进一步用于创建918315张图像的成对比较,用于人类偏好标注。对于人类偏好的标注,与现有工作的单一标注不同,我们考虑了更广泛的人类偏好维度,并使用人类标注在四个维度上标记每个图像对,包括美学、细节质量、语义对齐和总体得分。
为了学习人类的偏好,现有的方法使用预训练的视觉语言模型来独立地从图像和Prompt中提取特征,然后计算它们之间的相似性,进而用所收集的偏好数据来微调网络。当需要学习多维偏好时,一个最简单的策略是为不同的偏好训练单独的模型。然而,这样一个简单的策略需要为新的偏好重新收集数据和重新训练模型。此外,由于单一偏好数据中的潜在偏差,在一种偏好条件下训练的模型在与其他偏好进行评估时往往表现出较差的性能。
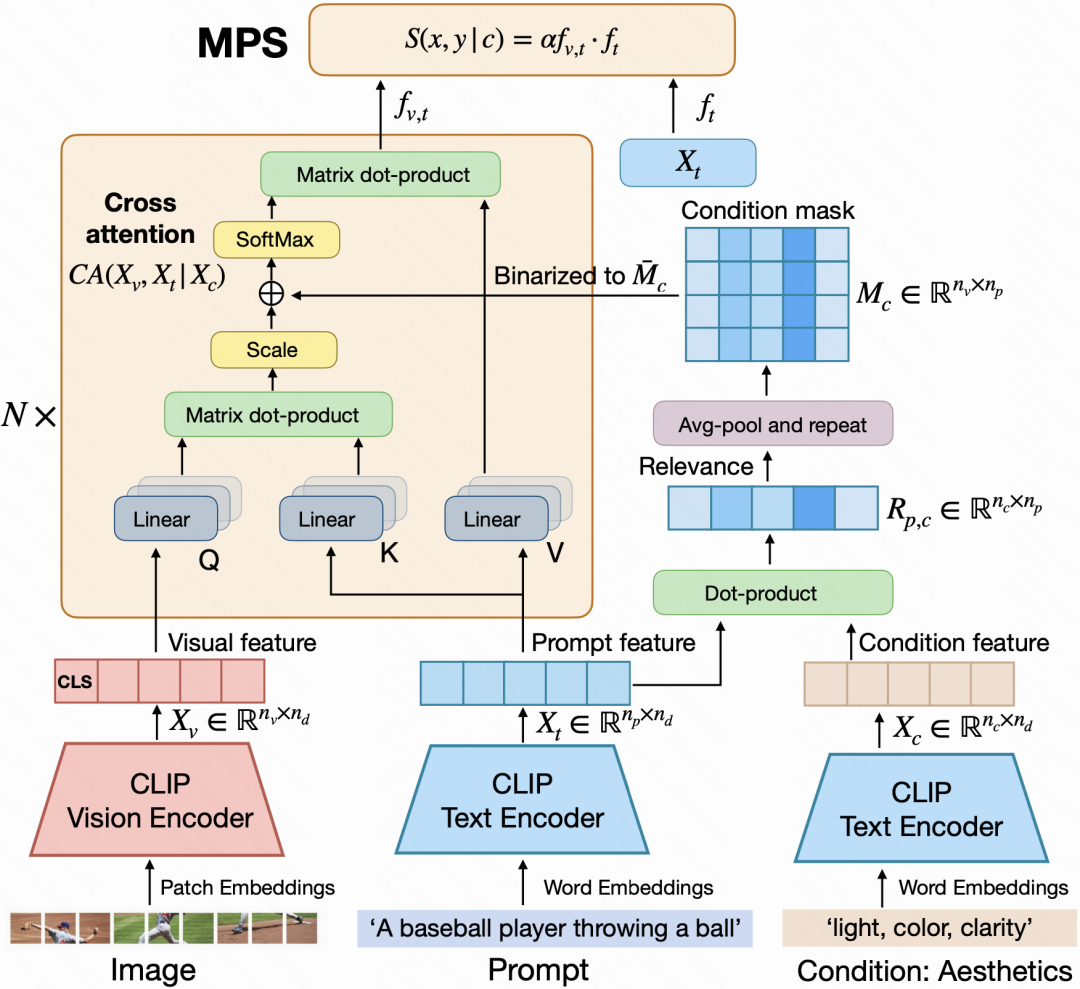
因此,我们提出了多维偏好模型(MPS),这是一个能够在各种偏好条件下预测分数的统一模型。具体来说,某一偏好是由一系列描述性词语表示的。例如,“美学”的偏好被分解为“光线”、“颜色”和“清晰度”等词语,用以描述这种条件的属性。这些属性词被用于计算与Prompt的相似性,从而生成反映Prompt中的词与指定条件之间的对应关系的相似性矩阵。
另一方面,使用预训练的视觉语言模型从图像和文本中提取特征。随后,通过多模态交叉注意力层融合两种模式。相似性矩阵充当了合并到交叉注意力层中的掩码,确保了视觉模态只关注与条件相关的文本。然后使用融合的特征来预测偏好得分。
我们的主要贡献如下:
提出了用于评估文本到图像生成模型的多维人类偏好(MHP)数据集。MHP包含类别平衡的Prompt和多维人类偏好标注的图像集合。基于MHP,提出了一个标准测试Benchmark用于评估现有的文本到图像生成模型。
提出了MPS模型,该模型学习了多维的人类偏好,并评估生成图片在不同偏好条件下的得分。
在预测总体偏好和多维偏好中,与三个数据集下的现有方法相比,MPS表现出更优的性能。
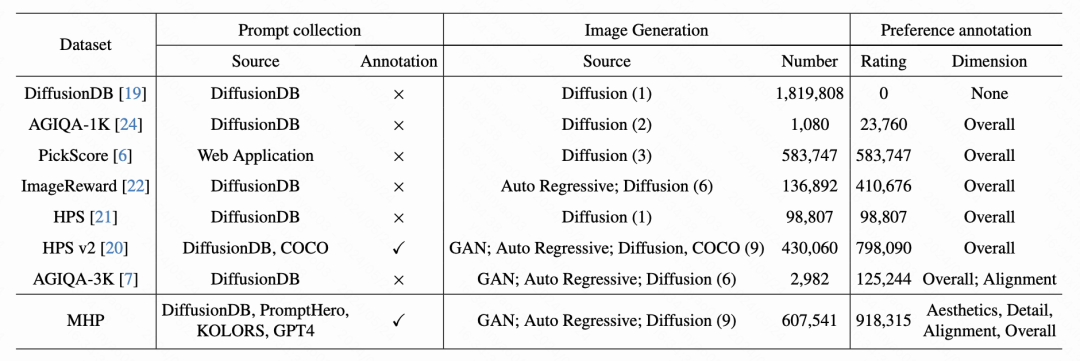
1.3 MHP数据集
我们的Prompt来自多个数据集,包括PromptHero、DiffusionDB等。参考Parti的类别模式,我们进一步对类别进行合并,最终确定了7个类别。基于这些定义的类别,我们对最初收集的59396条Prompt进行人工分类。此外,标注过程中还过滤掉异常Prompt(例如语义不连贯、不可理解和标点错误)。经过上一步处理,我们得到了52057条Prompt。如下图所示,最初收集的Prompt显示类别的长尾分布,而这种类别不平衡会导致生成图像的类别不平衡,从而使得学习到的人类偏好也可能存在偏差。
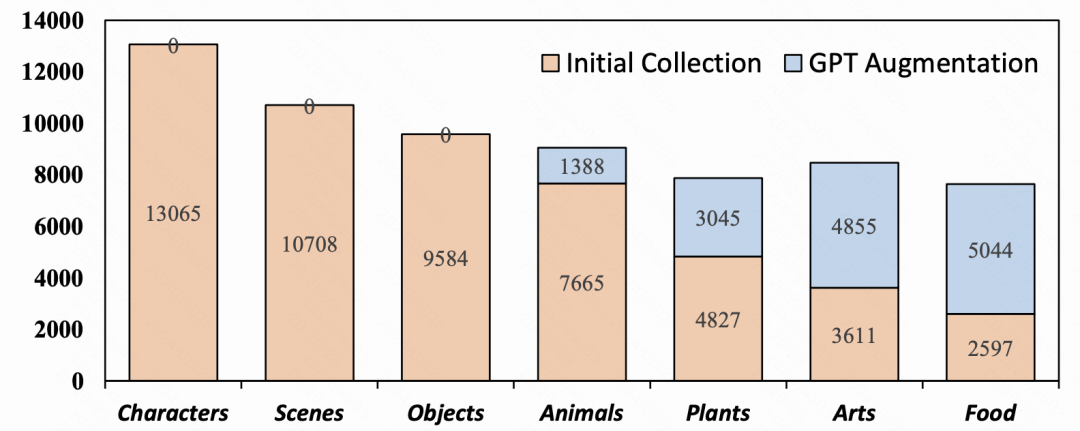
为了解决上面的问题,我们通过使用GPT-4获得了额外的Prompt并进一步细化打标,最终共获得66389条类别分布均衡的Prompt,有助于学习更具代表性的人类偏好。接下来,我们利用扩散模型、生成对抗模型和自回归模型,基于收集到的Prompt生成图像。每个模型为每个Prompt生成2-4个图像,生成的图像来自各种模型架构,具有多样化的图像分辨率和宽高比。这种多样性确保了文本到图像模型的泛化能力的全面表示。为了增强这些图像对的代表性,在构建图像对的过程中,我们不仅引入了不同模型生成的图像,还包括由相同模型使用不同随机种子生成的图像。基于这些对比图像对,我们使用人类标注来评估生成的图像质量,包括三个子维度(即美学、细节质量和语义对齐)和一个总体维度(即总体得分)。
1.4 MPS模型架构
我们采用CLIP从图像和Prompt中初步提取图像文本对的特征,为了计算不同偏好条件下的偏好得分,我们创新性的提出了一个条件掩码来突出显示相关的token,同时抑制不相关的token。最后,我们采用融合特征进行进一步预测人类偏好,最终MPS可表示为如下公式:
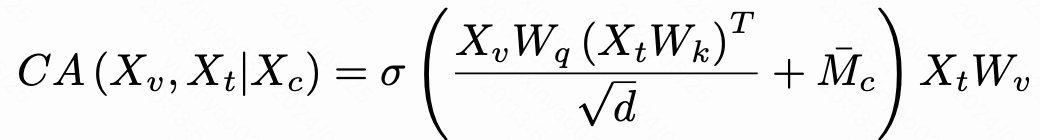
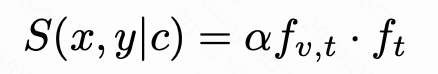
二、实验分析
2.1 模型评估
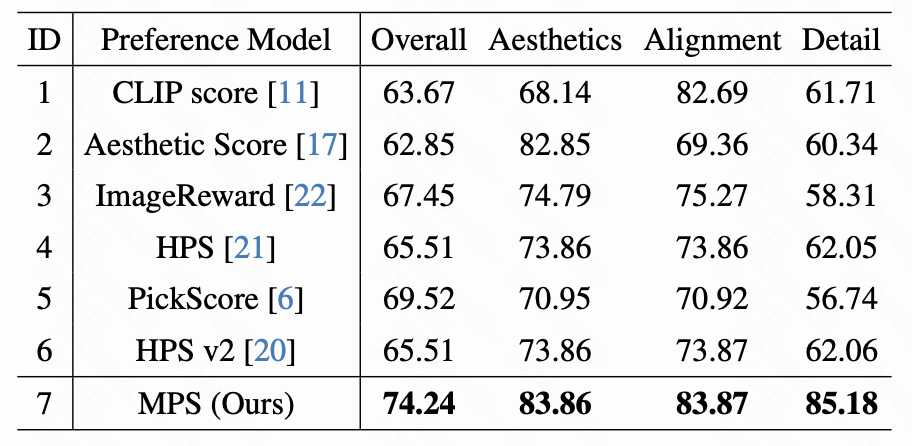
我们选择了广泛使用的统计指标来评估文本到图像模型,即CLIP评分和美感评分进行比较。此外,我们还选择了与人类偏好一致的方法来评估文本到图像模型,包括image Reward、HPS和PickScore。我们使用了公开的预训练模型,而无需进行微调以进行评估。为了进行公平的比较,我们选择了现有的公开可用的人类偏好数据集:ImageReward测试集和HPD v2测试集,以及我们的MHP数据集,以将我们的方法与相关基线进行比较。如下表所示,我们的MPS在这三个数据集上表现出更好的准确性,表明我们的方法具有强大的泛化能力。
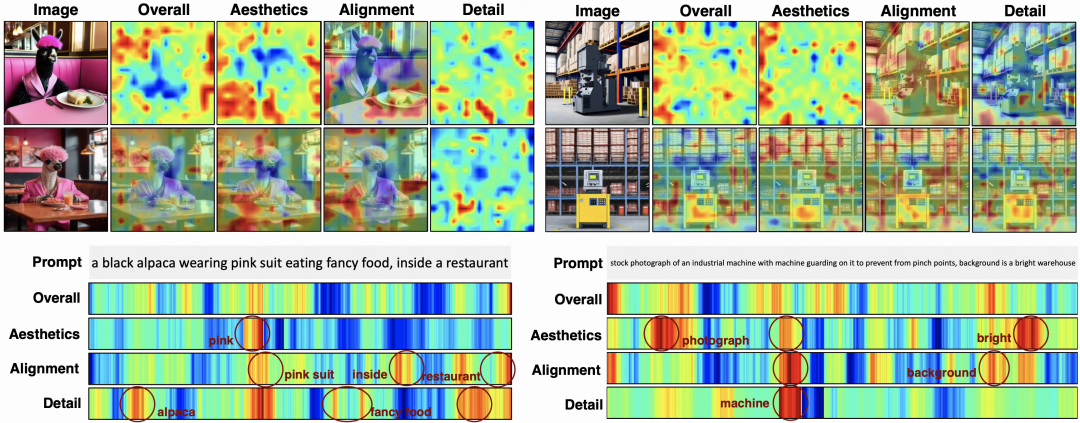
我们使用Grad-CAM来生成图像的注意力热图和Prompt的注意热图。可视化结果表明,MPS可以根据特定的偏好条件处理不同的Prompt和图像区域。这归因于条件掩码,它只允许图像观察Prompt中与偏好条件相关的单词。条件掩码确保模型预测具有不同输入的偏好,并且模型只需要计算图像中的补丁和保留的部分Prompt之间的相似性来确定最终得分。
2.2 RLHF
基于本文提出的MPS模型,我们也通过采用强化学习方法(如PPO、DPO等)将其作为奖励模型整合到可图文生图大模型的训练过程中,使得模型在训练中既能够准确建模匹配训练集的数据分布,又能够最大化奖励模型的输出。最终,通过引入强化学习和奖励模型技术(RLHF),使得可图模型输出更加接近人类审美标准,从而提升了整体美感和逼真度。
可图大模型是由快手 AI 团队自研打造的文生图大模型,具备强大的图像生成能力,能够基于开放式文本生成风格多样、画质精美、创意十足的绘画作品,让用户可以轻松高效地完成艺术创作,激漾灵感,智绘万物。
可图大模型全面开源,回馈开源社区。目前,Kolors已在Huggingface平台和GitHub上线,包括模型权重和完整代码,供企业与个人开发者免费使用。
官网地址:
https://kwai-kolors.github.io/
Github 项目地址:
https://github.com/Kwai-Kolors/Kolors