深度学习调优:选对正确的loss函数,再超参数调优真的很重要!!!
- 开发
- 18
-
本人亲测:模型不变,用别人代码中自定义的loss函数和test_smooth_l1函数真的天差地别!
选择适合的损失函数
- MSE:适用于需要显著惩罚大偏差的情况。
- MAE:适用于数据中存在异常值,并且你希望对异常值不那么敏感的情况。
- Smooth L1 Loss:适用于既有一定抗噪声能力又能对大偏差适当惩罚的情况。
最终选择Smooth L1 Loss这个损失函数
然后反向传播和optuna时,都以这个测试集中的Smooth L1 Loss作为参数,经过optuna调优,即可得到好的结果。
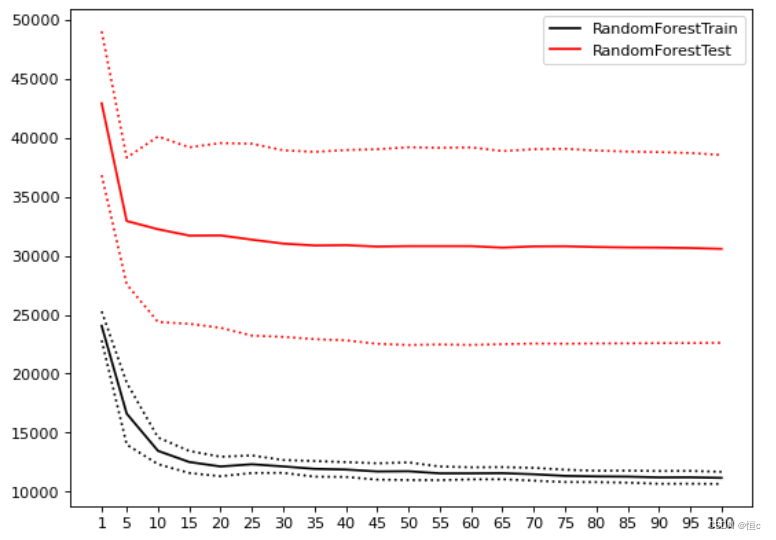
不合适的loss函数(自定义的myloss)预测结果:

合适的loss函数预测结果(通过下面的information开可以看出不是一个数据):


原文地址:https://blog.csdn.net/weixin_44162814/article/details/140528847
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。
本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:https://www.suanlizi.com/kf/1814007742092939264.html
如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!























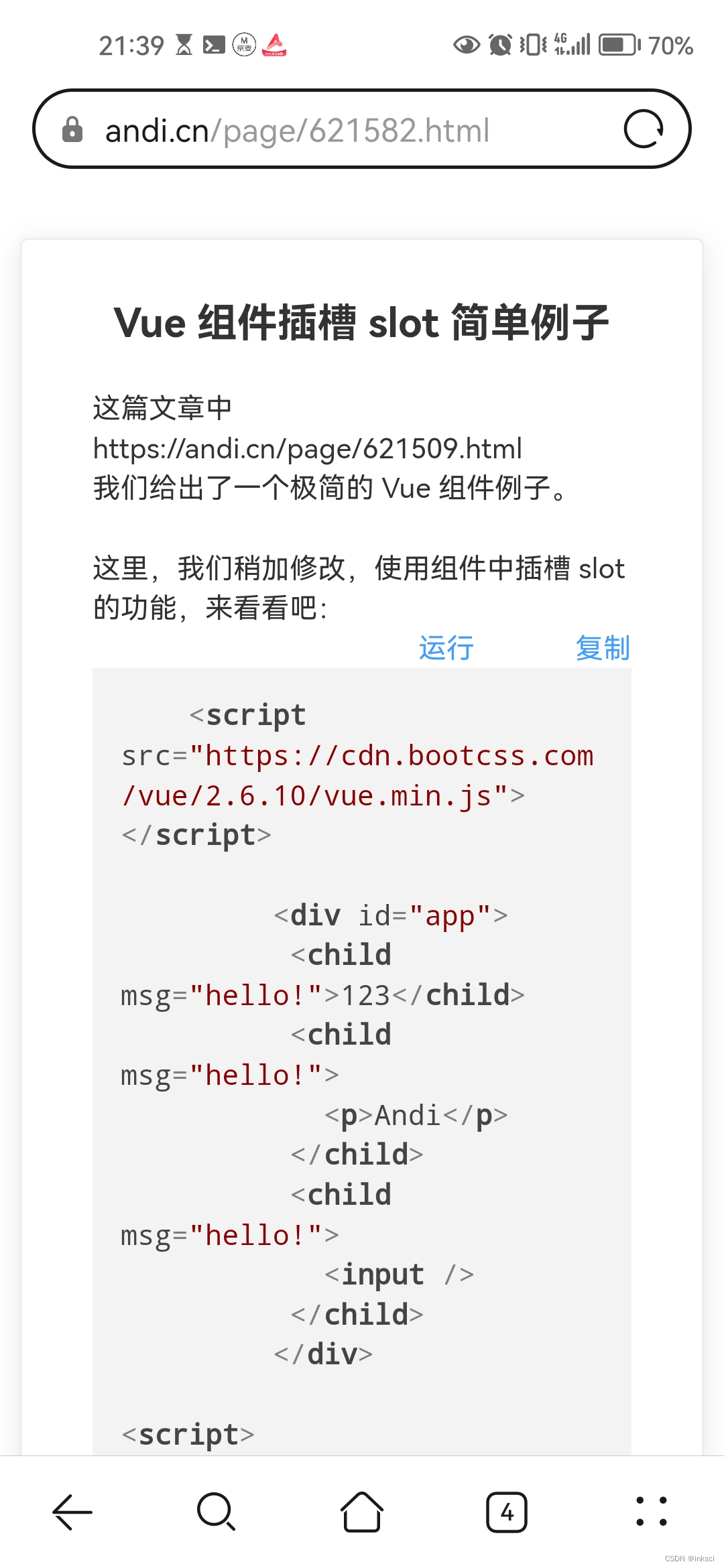





![[Linux]Linux编译器gcc/g++](https://i-blog.csdnimg.cn/direct/6039c464a0054394bf8c9bbc1e20c438.png)