教学(1):链接
1.1 预备知识
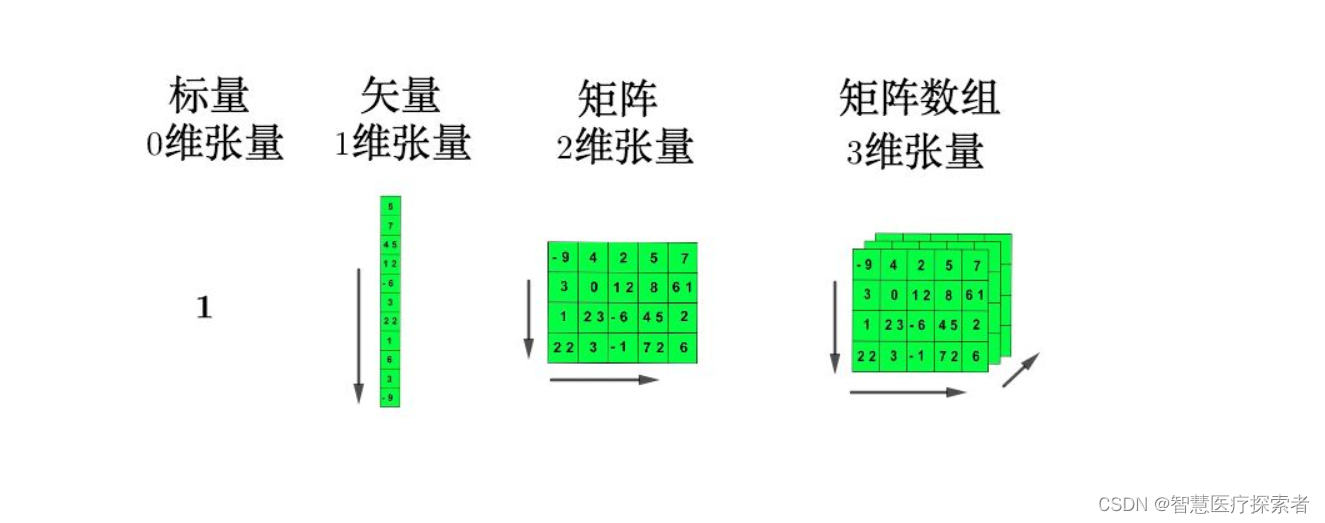
问题:假如说我们使用的模型张量是三维的,但是我们要缝合的模块是四维的,应该怎么办?
方法:pytorch中常用的函数:(1)view函数(2)reshape函数(3)permute函数(4)flatten函数
使用view函数:
import torch
import torch.nn as nn
x = torch.randn(10,3,32,32) #记为b,c,h,w
b,c,h,w = x.shape #访问x的shape属性
b,c,h,w = x.size() #size()用于提取x的维度
print(b,c,h,w)
#转换成三维b,n,c
y = x.view(b,h*w,c) #view()用于变换张量的形状
print(y.shape)使用permute和flatten函数:
import torch
import torch.nn as nn
x = torch.randn(10,3,32,32) #记为b,c,h,w
b,c,h,w = x.shape #访问x的shape属性
b,c,h,w = x.size() #size()用于提取x的维度
print(b,c,h,w)
#使用permute和flatten函数转换成三维b,n,c
a = x.permute(0,2,3,1) #1维在1维,原来的2维在现在的4维,原来的3维在2维,原来的4维在3维
a = a.flatten(start_dim=1,end_dim=2) # ctrl+p查看参数信息.在下标为1的维度(其实就是第二维)开始,在下标为2的维度结束,这之间展平
print(a.shape)结果均为:

1.2 模块和模块之间的维度转换
高维缝合低维
以CoordAtt和AFT为例,前者为4维,后者为3维。我们假如说想在CoordAtt这个四维模块中缝进三维的模块AFT。
缝:还是两个主要位置:类初始化__init__和前向传播forward。
(1)首先我们找到四维模块的前向传播,将用x.size()将四个维度都提取出来。
n, c, h, w = x.size() # 获取输入的尺寸
![]()
(2)用view将x的维度调整成3维,用另一个变量保存起来。
x_01 = x.view(n,h*w,c) #调整为3维张量
![]()
(3)在__init__中将三维模块加进来:
注意通道数保持一致,以及那个h*w对应在三维模块上的那个变量大小保持一致

(4) 在forward中添加进三维模块:
添加进之后,不要忘了三维模块输出还是三维,需要再次转换为4维。

打个断点看一下张量形状:
![]()
可以看到又恢复成了四维。
低维缝合高维
以CoordAtt和AFT为例,前者为4维,后者为3维。我们假如说想在AFT这个三维模块中缝进四维的模块CoordAtt。
原理大同小异,需要注意的就是在升维的时候要保持总数据量不变(各个维度的大小相乘)。
一开始的input的形状:
![]()
经过维度转换后input的形状:
![]()
缝合模块后input的形状:
![]()
再次经过维度转换后input的形状:
![]()

1.3 模型和模块之间的维度转换
举个例子,模型选择VIT(四维),要缝的模块还是AFT(三维)
(1)首先我们在模型前向传播最开始写入“print(x.shape)”,然后运行训练文件,看一下模型的输入张量:
![]()
(2)用x.size()将四个维度都提取出来。
b,c,h,w =x.size()
(3)用view将x的维度调整成3维,用另一个变量保存起来。
x_01 = x.view(b,h*w,c)
x_01的形状为[64,50176,3] (50176很大,会报显存错误,道理理解即可)
(4)在__init__中将三维模块加进来:
注意通道数保持一致,以及那个h*w对应在三维模块上的那个变量大小保持一致
(5) 在forward中添加进三维模块:

附录
view和reshape函数的区别
连续性要求:
view()函数要求张量是连续存储的。如果张量不是连续存储的(比如,经过转置、切片等操作后),直接使用view()会抛出错误。在这种情况下,你需要先调用contiguous()方法使张量连续,然后再使用view()。reshape()函数则更为灵活,无论张量是否连续,它都能工作。如果新的形状与原形状不兼容于视图变换(即不满足连续性条件),reshape()会创建一个新的、形状改变的张量副本,这会占用额外的内存。
内存共享:
- 当满足条件时,
view()返回的张量与原张量共享相同的内存,也就是说,它们是原张量的视图。修改其中一个会影响另一个。 reshape()可能会返回一个与原张量共享内存的视图(如果满足连续性条件),或者如果必须复制数据以满足新的形状,则返回一个副本。这意味着修改重塑后的张量可能不会影响原张量,具体取决于操作是否导致了数据的复制。
- 当满足条件时,
适用范围:
view()仅限于 PyTorch 的张量对象。reshape()在PyTorch中既适用于张量,也适用于NumPy数组,因此在需要跨库操作时提供了更多灵活性。
如果你确定张量满足连续性条件并且希望避免不必要的内存复制,view() 是一个高效的选择。但如果你不关心或不确定这些条件,或者需要保证操作总是安全的(即使是以牺牲一些性能为代价),则应使用 reshape()。在实际应用中,如果不确定是否可以直接使用 view(),使用 reshape() 是一个更保险的做法,因为它能自动处理所有情况。























![[Linux]Linux编译器gcc/g++](https://i-blog.csdnimg.cn/direct/6039c464a0054394bf8c9bbc1e20c438.png)