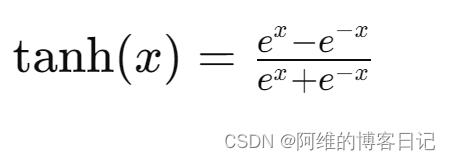⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计3077字,阅读大概需要3分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
个人网站:https://jerry-jy.co/
基于卷积神经网络的Cifar-10图像分类
基于卷积神经网络的Cifar-10图像分类
任务需求
本次实验使用Cifar10数据集,Cifar10是一个由彩色图像组成的分类的数据集,其中包含了飞机、汽车、鸟、猫、鹿、狗、 青蛙、马、船、卡车10个类别。每个类中包含了6000张图片。整个数据集中包含了6万张32×32的彩色图片。该数据集被分成50000和10000两部分,50000作为训练数据,用来做训练;10000是测试数据,用来做验证。
下图列举了10个类,每⼀类随机展示了10张图⽚

任务目标
1、掌握基于TensorFlow的内置数据集加载
2、掌握基于TensorFlow的卷积神经网络模型构建
3、掌握基于TensorFlow的神经网络网络模型编译设置和训练
任务环境
1、jupyter开发环境
2、OpenCv
3、python3.6
任务实施过程
一、导入数据
1.导入所需要的工具包和数据集
import tensorflow as tf # 导入tensorflow
from matplotlib import pyplot as plt # 导入绘图模块
import numpy as np # 导入numpy
from utils import im_show # 导入显示图像函数
# 绘制图像直接展示,不用调用plt.show()
%matplotlib inline
# 导入神经网络各层创建函数
from tensorflow.keras.layers import Conv2D, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras.models import Sequential #导入顺序模型
# cifar10是tf.keras.datasets模块下的内置数据集
# cifar10.load_data()加载数据集,如果首次加载将从互联网上下载
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# x_train, y_train表示训练集数据的尺寸为32*32*3的图像和图像对应的标签
# x_test, y_test表示测试数据的图像和对应标签
# 查看训练集输入图像数据的形状
print("x_train.shape:\n", x_train.shape)
# 查看训练集标签的形状
print("y_train.shape:\n", y_train.shape)
# 查看测试集输入图像数据的形状
print("x_test.shape:\n", x_test.shape)
# 查看测试集标签的形状
print("y_test.shape:\n", y_test.shape)

Cifar10数据集训练集包含5万张尺寸为32×32×3的彩色图片和对应的5万个标签;测试集包含1万张尺寸为32×32×3的彩色图片和对应的1万个标签
2.显示训练集前9个图像
绘制训练集前9个图像并设置图像标题为其对应的标签
# 设置画布大小
plt.figure(figsize=(9,9))
# 使用for循环绘制3行3列9个子图
for i in range(9):
plt.subplot(3,3,i+1)
# 绘制训练集x_train的前9个图像,设置子图标题为对应的标签
im_show(y_train[i][0],x_train[i])

y_train中保存着图像对应的分类标签,取值从0~9,表示10个类别
二、卷积神经网络模型构建
tf.keras搭建卷积神经网络的步骤:
- 1.导入tensorflow、numpy等所需模块。
- 2.读取数据集,tf.keras.datasets模块中有一些内置数据集
- 3.搭建所需的网络结构,当网络结构比较简单时,可以利用keras模块中的tf.keras.Sequential来搭建顺序网络模型;但是当网络不再是简单的顺序结构,而是有其它特殊结构出现时(例如ResNet中的跳连结构),便需要利用class来定义自己的网络结构。前者使用起来更加方便,但实际应用中往往需要利用后者来搭建网络。
- 4.对搭建好的网络进行编译(compile),通常在这一步指定所采用的优化器(如Adam、sgd、RMSdrop等)以及损失函数(如交叉熵函数、均方差函数等),选择哪种优化器和损失函数往往对训练的速度和效果有很大的影响。
- 5.将数据输入编译好的网络来进行训练(model.fit),指定训练轮数epochs以及batch_size等信息,由于神经网络的参数量和计算量一般都比较大,训练所需的时间也会比较长,尤其是在硬件条件受限的情况下,所以在这一步中通常会加入断点续训以及模型参数保存等功能,使训练更加方便,同时防止程序意外停止导致数据丢失的情况发生。
- 6.将神经网络模型的具体信息打印出来(model.summary),包括网络结构、网络各层的参数等,便于对网络进行浏览和检查。
1.Sequential搭建顺序网络模型
创建顺序模型tf.keras.models.Sequential()顺序模型是多个网络层的线性堆叠,也就是“一条路走到黑”
通过Sequential()有两种方法构建网络模型
- 1.通过向Sequential模型传递一个图层列表传递来构造该模型,例如:
model = Sequential([Dense(32, units=784),Activation('relu'),Dense(10),Activation('softmax'),])
- 2.通过.add()方法一个个的将层加入模型中,例如:
model = Sequential()
model.add(Dense(32, input_shape=(784,)))
model.add(Activation('relu'))
创建卷积层:tf.keras.layers.Conv2D (filters, kernel_size,strides=(1, 1), padding=‘valid’,activation=None)
- filters: 卷积核个数,
- kernel_size : 卷积核尺寸, 正方形写核长整数,或(核高h,核宽w)
- strides: 滑动步长, 横纵向相同写步长整数,或(纵向步长h,横向步长w),默认1
- padding :“same” or “valid”, “same”表示全零填充,“valid”(默认)表示不填充
- activation :激活函数“ relu ” or “ sigmoid ” or “ tanh ” or “ softmax”等 , #如有BN此处不写
创建最大池化层:tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=None, padding=‘valid’)
- pool_size:池化核尺寸,正方形写核长整数,或(核高h,核宽w)
- strides:池化步长,步长整数, 或(纵向步长h,横向步长w),默认为pool_size
- padding=‘valid’or‘same’, same”表示全零填充,“valid”(默认)表示不填充
拉直层:tf.keras.layers.Flatten() #拉直层输入特征拉直为一维数组,是不含计算参数的层
全连接层:tf.keras.layers.Dense(神经元个数,activation = "激活函数“,kernel_regularizer = "正则化方式)
批标准化层:tf.keras.layers.BatchNormalization()
Dropout层:tf.keras.layers.Dropout(rate=要降低的比率)
定义网络:
- 第一层为卷积层,有32个尺寸为3*3的卷积核,使用全零填充,激活函数为relu
- 第二层为池化层,池化核尺寸为2*2,步长为2,不填充
- 第三层为Dropout层,为了防止模型过拟合,设置要降低的比率为0.25
- 第四层为拉直层,将输入特征拉直为一维数组
- 第五层为全连接层,有512个节点,激活函数为relu
- 第六层为Dropout层,为了防止模型过拟合,设置要降低的比率为0.5
- 第七层为全连接层,任务为10分类任务,最后使用10节点的全连接层,激活函数为softmax
# 构建模型,通过向Sequential模型传递一个图层列表传递来构造神经网络模型
model = Sequential([
# 卷积层,输入图像尺寸为32*32*3,有32个3*3的卷积核,使用全0填充,激活函数为relu
Conv2D(32,(3,3),padding='same',input_shape=(32,32,3),activation='relu'),
# 池化层,池化核尺寸为2*2时,步长默认为2
MaxPool2D(pool_size=(2,2)),
# Dropout层防止模型过拟合
Dropout(0.25),
# 拉直层,将上面得到的特征拉直为一维数据
Flatten(),
# 全连接层,有512个节点,激活函数为relu
Dense(512,activation='relu'),
# Dropout层防止模型过拟合
Dropout(0.5),
# 全连接层,因为是10分类任务,有10个节点,激活函数为softmax
Dense(10,activation='softmax')
])
# 打印网络模型参数信息
model.summary()

2.神经网络网络模型编译
配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
配置训练方法model.compile(optimizer = 优化器,loss = 损失函数,metrics = ["准确率”])
- optimizer优化器可选:“sgd” , “adagrad" ,”adadelta" , “adam"
- loss损失函数可选:”mse",“sparse_categorical_crossentropy”
- metrics准确率可选:“accuracy” ,“sparse_accuracy", “sparse_categorical_accuracy”
设置模型的优化器为adam,损失函数为交叉熵,评价指标为多分类的准确率。
# 网络模型编译
# 设置优化器为'adam',损失函数为"sparse_categorical_crossentropy"
# 准确率为'sparse_categorical_accuracy'
model.compile(optimizer='adam',
loss="sparse_categorical_crossentropy",
metrics=['sparse_categorical_accuracy'])
# 归一化处理,运用归一化处理能够加快神经网络收敛速度
x_train, x_test = x_train / 255.0, x_test / 255.0
# 模型训练,设置训练结果为fit
epochs=5 # 一个epoch可以认为是一次训练循环
batch_size=32 # batch_siz表示批量大小
# validation_data:测试集;validation_freq:多少次epoch使用测试集验证一次结果。
fit = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs,
validation_data=(x_test, y_test), validation_freq=1)

本段代码在当前实验环境下预计运行15-20分钟。
3.训练结果可视化
# fit.history在每个epoch结束时记录了模型损失函数、准确率等信息
# 设置acc,val_acc分别为训练集,验证集的准确率
# 设置loss,val_loss分别为训练集,验证集的损失函数值
acc = fit.history['sparse_categorical_accuracy']
val_acc = fit.history['val_sparse_categorical_accuracy']
loss = fit.history['loss']
val_loss = fit.history['val_loss']
plt.figure(figsize=(12,9))
# 绘制1行2列两个子图
plt.subplot(1, 2, 1)
# 绘制训练集和测试集的准确率
plt.plot(acc,'r-', label='Training Accuracy')
plt.plot(val_acc, 'b--',label='Testing Accuracy')
plt.title('Training and Testing Accuracy')
plt.legend() # 显示图例
plt.subplot(1, 2, 2)
# 绘制训练集和测试集的损失函数值
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Testing Loss')
plt.title('Training and Testing Loss')
plt.legend() # 显示图例
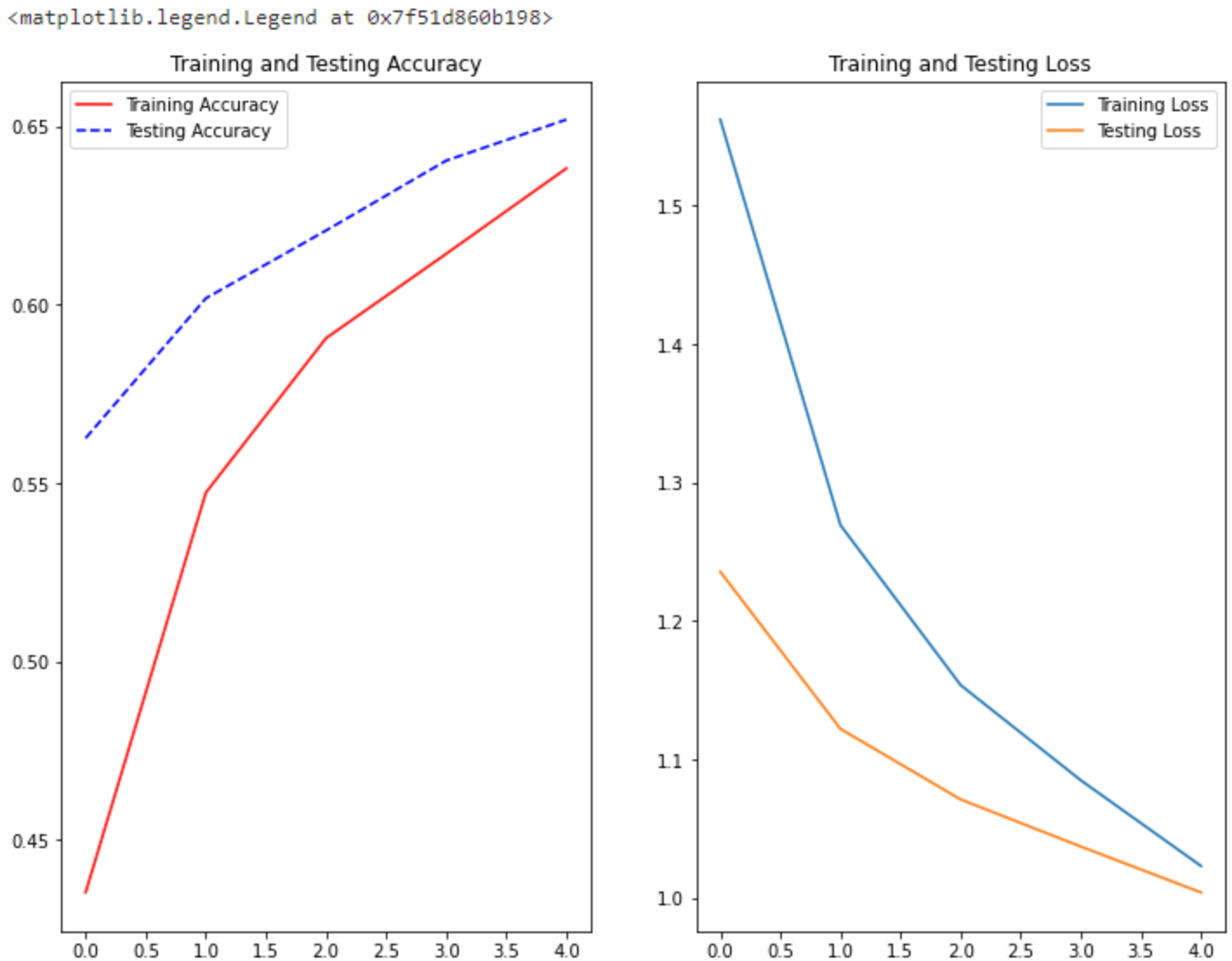
由上图可知,对于5个epoch的训练结果:
- 1.训练集和测试集数据的准确率随着训练轮数的增加在不断增加
- 2.训练集和测试集数据的损失函数值随着训练轮数的增加在降低,模型训练效果较好。
- 3.我们可以通过调整网络的参数和轮数来不断的验证网络模型的效果,从而提高准确率,降低损失,提高网络模型的泛化能力。
4.检验模型
# model.predict()根据模型预测,放入训练集数据
pridict_y=model.predict(x_test)
# pridict_y得到的是每个图像对应10个种类的概率
# 所以pridict_y的形状为(10000, 10)表示一个图像对应10个概率值,哪个类别概率值最高,就归为哪列
print(pridict_y.shape)
# 在pridict_y中横向寻找最大值的索引
pridict_y = tf.argmax(pridict_y, axis=1)
# 设置画布大小
plt.figure(figsize=(12,12))
# 使用for循环绘制3行3列9个子图
for i in range(9):
plt.subplot(3,3,i+1)
# 绘制测试集x_test的前9个图像
im_show('1',x_test[i])
# 设置子图标题为对应的测试集真实标签和预测标签
plt.title('Actual label:{} Predict label:{}'.format(np.array(pridict_y)[i],y_test[i][0]))

由上图可知:测试集前9个图像预测准确6个,准确率为66.6%
三、任务小结
本次实验主要完成基于卷积神经网络的CIFAR-10数据集的10分类任务。首先导入CIFAR-10数据集,然后查看训练集、测试集维度。接下来构建卷积神经网络,本实验使用顺序模型Sequential()构建神经网络,然后对网络模型编译和训练。最后绘制训练集和测试集的准确率和损失值以便查看模型效果,绘制测试集前9个图像的通过模型预测的标签和真实标签对比以便直观体会神经网络模型的预测效果。
通过本次实验需要掌握以下内容:
- 掌握基于TensorFlow的内置数据集加载
- 掌握基于TensorFlow的卷积神经网络模型构建
- 掌握基于TensorFlow的神经网络网络模型编译设置和训练
- 掌握神经网络网络模型的验证
–end–

![NNDL<span style='color:red;'>卷</span><span style='color:red;'>积</span><span style='color:red;'>神经</span><span style='color:red;'>网络</span>-使用预训练resnet<span style='color:red;'>18</span>实现<span style='color:red;'>CIFAR</span>-<span style='color:red;'>10</span><span style='color:red;'>分类</span> [HBU]](https://img-blog.csdnimg.cn/direct/b4feba68d11a4015b235b66046fb288b.png)