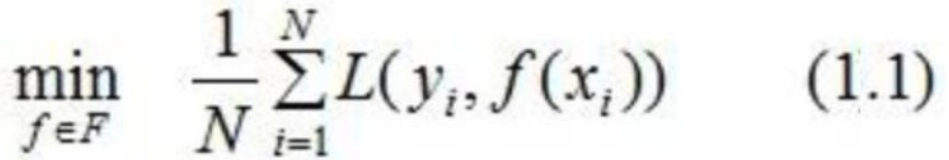XGBoost(eXtreme Gradient Boosting)和LightGBM(Light Gradient Boosting Machine)都是一类基于梯度提升树(Gradient Boosting Decision Trees)的机器学习算法。
XGBoost是由陈天奇开发的一种优化的梯度提升框架,它可以用于分类和回归问题。XGBoost通过将多个弱学习器(通常是决策树)组合成一个强学习器来提高预测性能。它在训练过程中使用了梯度下降法来优化模型的参数,可以处理高维稀疏特征、缺失值和非线性关系,并具有较好的鲁棒性和泛化能力。
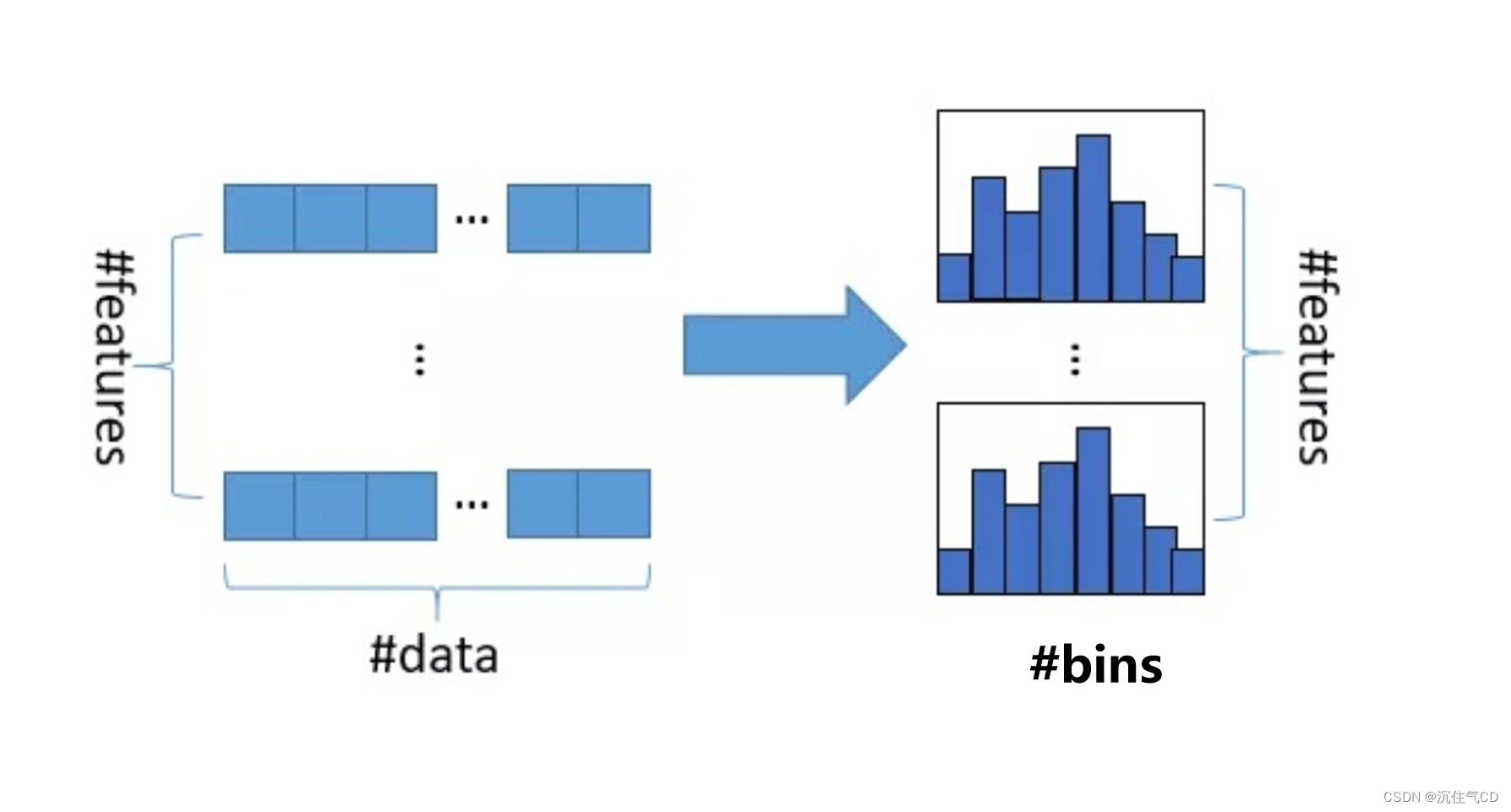
LightGBM是微软开发的一种基于梯度提升框架的高性能机器学习算法。它使用了基于直方图的决策树学习算法,通过将连续特征离散化成离散的直方图桶来提高训练速度和内存效率。LightGBM还使用了基于梯度的单边采样和互斥特征捆绑等技术来进一步提高训练速度和模型性能。
总的来说,XGBoost和LightGBM都是基于梯度提升树的机器学习算法,它们在性能上都有一定的优势,可以用于处理各种类型的机器学习问题。其中,XGBoost更加成熟和稳定,并且具有较好的泛化能力;而LightGBM则在速度和效率方面有一定的优势,适用于处理大规模数据集和高维特征的情况。选择使用哪种算法取决于具体的应用场景和需求。
XGBoost和LightGBM算法各自具有以下特点:
XGBoost的特点:
1. 高性能:XGBoost在处理大规模数据集和高维特征时具有较高的训练和预测速度。
2. 鲁棒性:XGBoost对于缺失值和离散特征有很好的处理能力,并且对噪声和异常值有较强的鲁棒性。
3. 泛化能力:XGBoost通过使用正则化技术(如L1和L2正则化项)来控制模型的复杂度,从而提高模型的泛化能力。
4. 可解释性:XGBoost可以输出特征重要性和决策路径等信息,方便对模型进行解释和理解。
5. 并行化处理:XGBoost能够有效地进行并行化处理,利用多线程和分布式计算来加快训练速度。
LightGBM的特点:
1. 高效性:LightGBM使用了基于直方图的决策树算法和互斥特征捆绑等技术,使得训练和预测速度更快,并且能够处理大规模数据集和高维特征。
2. 内存效率:LightGBM使用了压缩技术来减少内存消耗,使得可以处理大规模数据集。
3. 高准确性:LightGBM采用了单边梯度采样和互斥特征捆绑等技术来提高训练速度,同时还能够保持较高的准确性。
4. 分类和回归:LightGBM既适用于分类问题,也适用于回归问题,具有较强的通用性。
5. 自定义损失函数:LightGBM支持自定义损失函数,可以根据具体问题的特点来定义适合的损失函数。
总的来说,XGBoost和LightGBM都是强大的机器学习算法,它们各自具有高性能、鲁棒性、泛化能力和高效性等不同的特点,可以根据具体的应用场景和需求来选择使用。
XGBoost和LightGBM算法在使用场景上有一些差异。以下是它们常见的使用场景:
XGBoost的使用场景:
1. 结构化数据:XGBoost在处理结构化数据(如表格数据)时表现出色,特别适用于金融、零售、电信等行业的数据分析和预测任务。
2. 特征工程:XGBoost能够自动处理缺失值、离散特征和异常值等,因此在需要进行大量特征工程的任务中较为常用。
3. 高性能要求:XGBoost在处理大规模数据集和高维特征时具有较高的训练和预测速度,适合需要快速训练和预测的场景。
LightGBM的使用场景:
1. 大规模数据集:LightGBM使用了基于直方图的决策树算法和压缩技术,能够处理大规模数据集,尤其适用于需要高效处理大数据的场景。
2. 特征工程:LightGBM在处理高维特征时表现出色,能够自动处理稀疏特征和高基数特征等,因此在需要处理高维稀疏数据的任务中较为常用。
3. 高效性要求:LightGBM的训练和预测速度较快,能够在较短的时间内获得较好的模型性能,适用于需要高效训练和预测的场景。
总的来说,XGBoost和LightGBM在使用场景上有一些重叠,但也有一些差异。XGBoost更适合处理结构化数据、进行特征工程和有高性能要求的任务,而LightGBM更适用于处理大规模数据集、高维特征和有高效性要求的任务。具体选择哪种算法还需根据具体的问题和数据特点来决定。
XGBoost(eXtreme Gradient Boosting)和LightGBM是两种基于梯度提升决策树(Gradient Boosting Decision Tree, GBDT)的机器学习算法。它们的原理和实现方法有一些不同之处:
1. 数据划分方式:XGBoost采用的是预排序(pre-sorted)的策略,即对特征按照某种排序方式先进行排序,然后在每个特征上寻找最佳的切分点进行划分。而LightGBM采用的是一种基于直方图(histogram)的方式,将数据划分为多个直方块,并对每个直方块进行划分,从而减少了划分时需要遍历的数据量,提高了效率。
2. 特征并行化处理:XGBoost在每一轮迭代中,会对所有特征进行划分属性值的遍历,然后选择最佳的切分点。这种方式在处理大规模高维数据时可能会存在效率问题。而LightGBM引入了一种基于直方图的并行化策略,每个线程只需对一个特征的直方图进行划分,从而提高了训练速度。
3. 采样策略:XGBoost采用的是基于梯度的采样策略,对样本进行采样来构建每个基学习器(弱分类器)。而LightGBM引入了一种基于梯度和随机的采样策略,先根据样本梯度的绝对值进行采样,然后再在采样的样本中随机选择一部分样本来训练每个基学习器。
总的来说,XGBoost和LightGBM在数据划分、特征并行化处理和采样策略上有一些不同之处。这些差异导致了它们在训练速度、内存占用和准确率上的差异。具体选择哪种算法还需根据数据的规模、特征的属性和任务的要求来决定。
XGBoost和LightGBM都是基于梯度提升决策树(GBDT)的算法,它们在很多方面有相似之处,但也有一些不同点。以下是XGBoost和LightGBM算法的一些比较:
1. 训练速度:LightGBM相比XGBoost在训练速度上更快。LightGBM使用了基于直方图的方式对数据进行划分,减少了遍历数据的时间。而XGBoost使用预排序的方式进行划分,需要在每个特征上遍历所有可能的切分点。因此,在大规模高维数据集上,LightGBM的训练速度通常比XGBoost更快。
2. 内存占用:LightGBM在内存占用上通常比XGBoost更低。LightGBM使用了压缩的直方图数据结构来存储特征的直方图,减少了内存的占用。而XGBoost在每个节点上都需要存储所有样本的索引和特征值,占用的内存较高。
3. 准确率:在准确率上,XGBoost和LightGBM表现相当,没有明显的优劣之分。两者都能通过优化目标函数和引入正则化方法来提高模型的准确性。
4. 参数调优:XGBoost在参数调优上相对较为复杂,有较多的参数需要调整。通过网格搜索或随机搜索来调整参数可能会相对费时。而LightGBM对一些重要参数有预设的默认值,参数较少,调优相对较简单。
综上所述,XGBoost和LightGBM在训练速度、内存占用和参数调优等方面存在一些差异。选择哪种算法取决于数据集的规模、特征属性、计算资源和任务要求等因素。同时,实践中也可以尝试使用两种算法进行对比实验,选择最适合的算法进行模型构建。
以下是XGBoost和LightGBM在R语言中的简单示例代码:
XGBoost R代码示例:
```R
# 安装和加载xgboost包
install.packages("xgboost")
library(xgboost)
# 加载数据
data(iris)
train <- iris[1:100, ]
test <- iris[101:150, ]
# 将数据转换为DMatrix格式
dtrain <- xgb.DMatrix(data = as.matrix(train[, -5]), label = train[, 5])
dtest <- xgb.DMatrix(data = as.matrix(test[, -5]), label = test[, 5])
# 设置参数
params <- list(
objective = "multi:softmax",
num_class = 3,
eval_metric = "merror"
)
# 训练模型
model <- xgboost(params = params, data = dtrain, nrounds = 100)
# 预测
pred <- predict(model, dtest)
```
LightGBM R代码示例:
```R
# 安装和加载lightgbm包
install.packages("lightgbm")
library(lightgbm)
# 加载数据
data(iris)
train <- iris[1:100, ]
test <- iris[101:150, ]
# 将数据转换为Dataset格式
dtrain <- lgb.Dataset(data = as.matrix(train[, -5]), label = train[, 5])
dtest <- lgb.Dataset(data = as.matrix(test[, -5]), label = test[, 5])
# 设置参数
params <- list(
objective = "multiclass",
num_class = 3,
metric = "multi_logloss"
)
# 训练模型
model <- lgb.train(
params = params,
data = dtrain,
num_boost_round = 100
)
# 预测
pred <- predict(model, as.matrix(test[, -5]))
```请注意,以上代码仅作为示例,实际使用时需要根据自己的数据和任务进行相应的参数设置和调整。