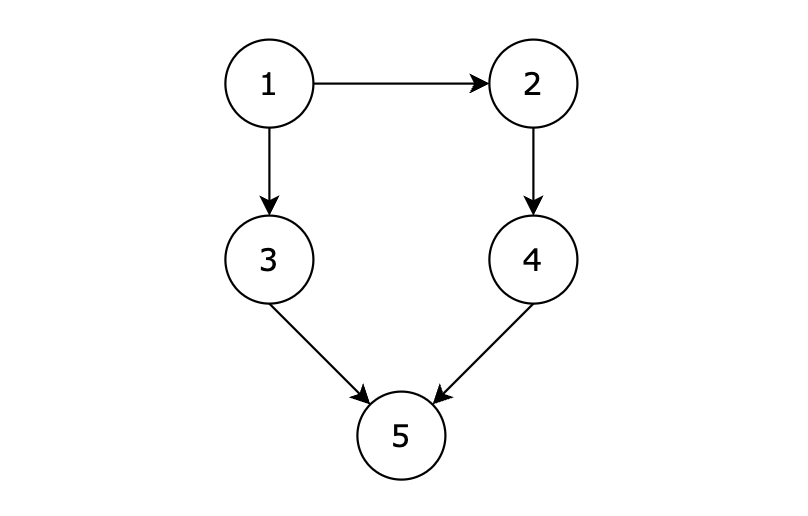
邻接矩阵
邻接矩阵是一种使用二维数组来表示图的方法。矩阵中的元素表示节点之间是否存在边。如果存在边,则对应的矩阵元素为1(或边的权重);否则为0。
特点:
- 空间复杂度高:无论图是否稀疏,邻接矩阵都需要O(V^2)的空间,因为每个节点都需要为所有其他节点预留位置。
- 查找效率高:查找任意两节点之间是否存在边非常高效,只需要访问一次数组,时间复杂度为O(1)。
- 不适合稀疏图:对于边远少于顶点平方的稀疏图,邻接矩阵会浪费大量空间。
int[][] adjMatrix = new int[n + 1][n + 1];
for (int i = 0; i < m; i++) {
int u = scanner.nextInt();
int v = scanner.nextInt();
adjMatrix[u][v] = 1; // 对于有向图,如果是无向图,还需要设置 adjMatrix[v][u] = 1;
}
邻接表
邻接表是一种通过链表或数组来表示图的方法。对于图中的每个节点,邻接表存储一个链表,链表中的元素是该节点的所有邻居节点。
特点:
- 空间复杂度低:对于稀疏图(边的数量远小于顶点的平方),邻接表比邻接矩阵节省空间。它的空间复杂度是O(V + E),其中V是顶点数,E是边数。
- 查找效率高:查找某个节点的所有邻居节点非常高效,只需要遍历链表即可。
- 添加边高效:向图中添加一条边只需要在对应的链表中添加一个节点,时间复杂度为O(1)。
// 初始化邻接表
List<List<Integer>> adjList = new ArrayList<>();
for (int i = 0; i <= n; i++) {
adjList.add(new ArrayList<>());
}
for (int i = 0; i < m; i++) {
int u = scanner.nextInt();
int v = scanner.nextInt();
adjList.get(u).add(v); // 对于有向图,如果是无向图,还需要 adjList.get(v).add(u);
}
98. 所有可达路径

题解:
public class AllReachablePaths {
/**
* 方法一:使用邻接表表示图,深度优先搜索遍历图,寻找所有从节点1到节点n的路径
*
* @param graph 图的邻接表表示
* @param n 节点总数
* @return 所有从节点1到节点n的路径列表
*/
public static List<List<Integer>> allPathsSourceTarget1(List<LinkedList<Integer>> graph, int n) {
List<List<Integer>> result = new ArrayList<>();
LinkedList<Integer> path = new LinkedList<>();
path.add(1); // 从节点1开始
dfs1(graph, 1, n, path, result); // 深度优先搜索
return result;
}
/**
* 深度优先搜索遍历图的递归函数
*
* @param graph 图的邻接表表示
* @param x 当前遍历到的节点
* @param n 终点节点
* @param path 当前路径
* @param result 存储所有路径的结果集合
*/
private static void dfs1(List<LinkedList<Integer>> graph, int x, int n, LinkedList<Integer> path, List<List<Integer>> result) {
if (x == n) { // 找到一条从1到n的路径
result.add(new ArrayList<>(path)); // 将当前路径加入结果集合
return;
}
for (int i : graph.get(x)) { // 遍历节点x的邻居节点
path.add(i); // 将邻居节点i加入路径中
dfs1(graph, i, n, path, result); // 递归遍历从节点i出发的路径
path.removeLast(); // 回溯,移除最后一个节点,尝试其他路径
}
}
/**
* 方法二:使用邻接矩阵表示图,深度优先搜索遍历图,寻找所有从节点1到节点n的路径
*
* @param graph 图的邻接矩阵表示
* @param n 节点总数
* @return 所有从节点1到节点n的路径列表
*/
public static List<List<Integer>> allPathsSourceTarget2(int[][] graph, int n) {
List<List<Integer>> result = new ArrayList<>();
LinkedList<Integer> path = new LinkedList<>();
path.add(1); // 从节点1开始
dfs2(graph, 1, n, path, result); // 深度优先搜索
return result;
}
/**
* 深度优先搜索遍历图的递归函数
*
* @param graph 图的邻接矩阵表示
* @param x 当前遍历到的节点
* @param n 终点节点
* @param path 当前路径
* @param result 存储所有路径的结果集合
*/
private static void dfs2(int[][] graph, int x, int n, LinkedList<Integer> path, List<List<Integer>> result) {
if (x == n) { // 找到一条从1到n的路径
result.add(new ArrayList<>(path)); // 将当前路径加入结果集合
return;
}
for (int i = 1; i <= n; i++) {
if (graph[x][i] == 1) { // 如果节点x与节点i相连
path.add(i); // 将节点i加入路径
dfs2(graph, i, n, path, result); // 递归遍历从节点i出发的路径
path.removeLast(); // 回溯,移除最后一个节点,尝试其他路径
}
}
}
/**
* 主函数,用于测试两种方法
*/
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt(); // 节点总数
int m = scanner.nextInt(); // 边数
// 使用邻接表表示图,节点编号从1到n,因此需要n+1大小的数组
List<LinkedList<Integer>> graph1 = new ArrayList<>(n + 1);
for (int i = 0; i <= n; i++) {
graph1.add(new LinkedList<>()); // 初始化邻接表
}
// 使用邻接矩阵表示图,节点编号从1到n,因此需要n+1大小的数组
int[][] graph2 = new int[n + 1][n + 1];
// 读取每条边的起点和终点,构建邻接表和邻接矩阵
for (int i = 0; i < m; i++) {
int s = scanner.nextInt(); // 边的起点
int t = scanner.nextInt(); // 边的终点
graph1.get(s).add(t); // 邻接表:s -> t,无向图
graph2[s][t] = 1; // 邻接矩阵:s -> t,无向图
}
// 使用方法一寻找所有路径
List<List<Integer>> paths1 = allPathsSourceTarget1(graph1, n);
System.out.println("Method 1 - Using Adjacency List:");
printPaths(paths1);
// 使用方法二寻找所有路径
List<List<Integer>> paths2 = allPathsSourceTarget2(graph2, n);
System.out.println("Method 2 - Using Adjacency Matrix:");
printPaths(paths2);
}
/**
* 输出所有路径的辅助函数
*
* @param paths 路径列表
*/
private static void printPaths(List<List<Integer>> paths) {
if (paths.isEmpty()) {
System.out.println(-1); // 如果没有找到路径,输出-1
} else {
for (List<Integer> path : paths) {
for (int i = 0; i < path.size() - 1; i++) {
System.out.print(path.get(i) + " "); // 输出路径中的节点
}
System.out.println(path.get(path.size() - 1)); // 输出路径的最后一个节点
}
}
}
}
深度优先搜索理论基础
深度优先搜索(DFS, Depth-First Search)可以形象地理解为“碰到南墙再回头”。具体来说,DFS 的操作方式如下:
从起始节点开始,沿着一条路径一直往前走,尽可能深地进入到图的最深处。
当走到无法继续前进(即碰到“南墙”)的时候,回溯到上一个节点,寻找其他未访问的路径。
重复上述步骤,直到所有节点都被访问过。
这种搜索方式类似于在迷宫中行走,尽量往前走,直到无法前进时再回头,寻找其他可能的路径。
dfs模板:
void dfs(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本节点所连接的其他节点) {
处理节点;
dfs(图,选择的节点); // 递归
回溯,撤销处理结果
}
}
广度优先搜索理论基础
广度优先搜索(BFS, Breadth-First Search)的基本原理是逐层地搜索图或树的节点,从起始节点开始,首先访问所有与起始节点直接相连的节点(即第一层节点),然后逐层向外扩展,直到找到目标节点或所有可达节点都被访问过为止。
bfs需要一个容器,能保存我们要遍历过的元素就可以,那么用队列,还是用栈,甚至用数组,都是可以的。
用队列的话,就是保证每一圈都是一个方向去转,例如统一顺时针或者逆时针。
因为队列是先进先出,加入元素和弹出元素的顺序是没有改变的。
如果用栈的话,就是第一圈顺时针遍历,第二圈逆时针遍历,第三圈有顺时针遍历。
因为栈是先进后出,加入元素和弹出元素的顺序改变了。
bf’s模版:
// BFS 函数模板
void bfs(int start, List<List<Integer>> graph) {
// 图的顶点数
int V = graph.size();
// 记录节点是否已访问
boolean[] visited = new boolean[V];
// 创建队列用于 BFS
Queue<Integer> queue = new LinkedList<>();
// 初始化,将起始节点加入队列并标记为已访问
queue.offer(start);
visited[start] = true;
// BFS 主循环
while (!queue.isEmpty()) {
// 出队列
int v = queue.poll();
// 处理当前节点 v,可以是打印节点值或其他操作
System.out.print(v + " ");
// 遍历当前节点 v 的所有相邻节点
for (int next : graph.get(v)) {
// 如果相邻节点未被访问过,则加入队列并标记为已访问
if (!visited[next]) {
queue.offer(next);
visited[next] = true;
}
}
}
}
使用场景对比
| 特点 | 深度优先搜索 (DFS) | 广度优先搜索 (BFS) |
|---|---|---|
| 主要应用 | 路径查找、连通分量、拓扑排序、回溯算法等 | 最短路径查找、层次遍历、二分图检测等 |
| 内存占用 | 较少,因为只需要存储当前路径和少量节点 | 较多,因为需要存储当前层的所有节点 |
| 实现复杂度 | 相对简单,可以使用递归或显式栈实现 | 较复杂,需要使用队列实现 |
| 路径长度 | 不一定是最短路径 | 总是最短路径 |
| 遍历顺序 | 深入到尽可能深的节点,然后回溯 | 按层次遍历,从起点开始逐层扩展 |
| 适用场景 | 迷宫问题、连通分量检测、回溯问题、拓扑排序等 | 无权图的最短路径查找、层次遍历、二分图检测等 |