[KamaCoder] 最短路问题总结篇
自己看到题目的第一想法
最短路径问题刚开始看的时候, 可能是 N 阳了, 高烧不停的在 38.2 到 39.2 之间波动, 烧的很厉害的时候会疯狂的出汗, 然后体温就下降了. 到现在三周了, 还是咳嗽喉咙有点疼, 但是已经恢复的不少了.
最短路径里一开始就被概念给吓晕了, 有向图、无向图、连通图、强连通图、连通分量. 确实吓了我一大跳. 我感觉和我没有这部分的基础是有关系的.
看完代码随想录之后的想法
到总结篇了, 我对最短路径大部分已经不再恐惧了, 似乎也总是可以靠自己写出最后的算法, 但确实总是有种摇摇欲坠之感.
特别是 Kruskal 算法, 为什么每次选择最短的边, 只要不构成回路, 遍历完所有的边将没有形成环路的边都添加到最小生成树中, 就可以呢? Kruskal 算法比起 Prim 算法, 似乎没那么直观. Prim 算法非常的直观, 从点出发遍历所有的边, 从每个节点出发的边中, 每次只选最短的那一条, 选中这条边后就删除该边, 删除该边的方式为将该节点的 visited[index] 置为 true. 同时更新与该节点相连的边, 距离该节点的距离, 这样做的目的是为了将与该节点相连的边添加到带选路径中. 通过不断的将相连的边中最短的那条边添加进来, 最终完成最小生成树的添加. 这里我自己有个认知是, Prim 一定是要双向图, 如果是单向图的话, 会有问题吧?
Kruskal 也是一样, 每个节点出发的边中, 只要把最短的选出来, 假设 A -》B -〉C -》A 这样的一个环形路中, 挑出最短的两条边, 是不是就减去了最长的边, 同时构成了最小生成树. Kruskal 是如何减边的呢, 和 Prim 是一样的, 通过对边进行排序, 同一个节点出发的边, 每次只取最小边, 如果一条边添加进来产生了环路, 说明 A B C ... X 的 N 点中, 已经被权值更小的 N - 1 条边相连了, 这条产生环路的边是权值更大的, 需要被舍弃.
Dijkstra 就是 Prim 的基础上, 需要计算节点距离出发点的距离, Dijkstra 堆优化版就是将 minDist 数组的结果再保存到按节点到出发点的距离排序的堆中, 辅助完成节点的筛选.
Bellman_ford 会简单一些, N 个节点则松弛 n - 1 次, 就可以得到从出发节点到每个节点的最近距离.
Bellman_ford 判断是否产生负权回路, 就是在第 n 次松弛的时候, 发现 minDist 发生改变, 就说明长生了负权回路.
Bellman_ford 单源有限制节点路径寻址的话, 每次获取 minDist 值的时候, 不能用更新过的 minDist[index] 值, 需要从 minDistCopy[index] 里获取. 否则限制为 k 个节点的条件可能就不生效.
SPFA (Shortest Path Fast Algorithm) 有点像 Prim, 每次把松弛过的边相连的节点添加到队列中, 下次对这些节点相连的边再松弛一次. 因为被松弛的边相连的节点可能发生了改变, 因此一旦发生改变就需要松弛所有相连的其他边.
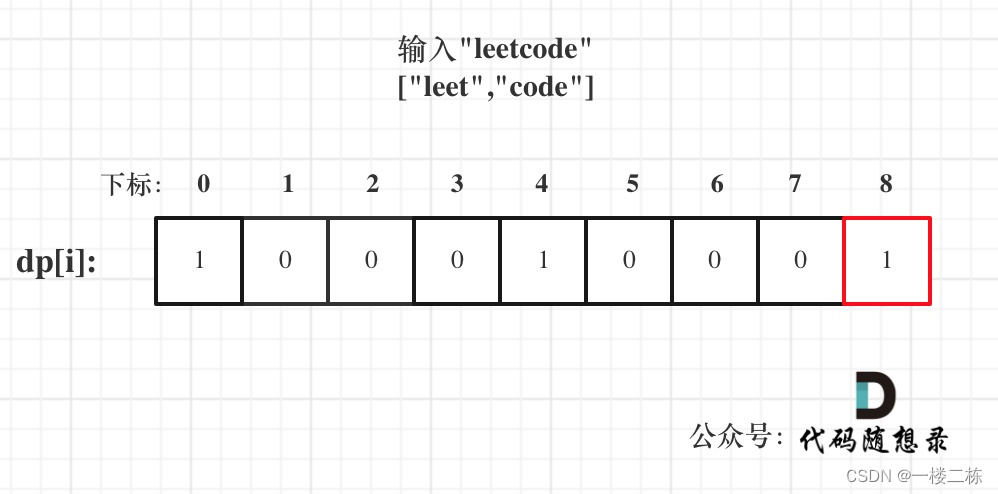
Floyd 算法一开始我很不理解, 好像突然来到了三维世界. 但是那个三维坐标图你不要露怯的话, 会发现其实只是用看似复杂的图说明了一个很简单的道理, 因为只初始化了 k = 0 时候的所有点的数据, 因此如果将 k 放在中间或者最里层, 就会造成 [i][j][k] 依赖了未计算过的 [i][k][k - 1]. dp[i][j][k] = Math.min(dp[i][j][k - 1], dp[i][k][k - 1] + dp[k][j][k - 1]). 如果 k 在最里层, 那么 [1][2][3] = Math.min(dp[1][2][2], dp[1][3][2] + dp[3][2][2]), 这时候 dp[1][3][2] 和 dp[3][2][2] 还没有计算出来, 导致最终结果出现异常.
Astar 主要是启发函数, 因为所有节点都会被遍历到, 只是每次挑选哪个节点的不同, 因此还是比较简单的.
自己实现过程中遇到哪些困难
就是那种迷迷糊糊的感觉吧. 好像一次写不出来, 看答案又懂了, 再过几天又忘了... 那种不能言说的痛.
[KamaCoder] 图论总结篇
自己看到题目的第一想法
让我想一想, dfs 和 bfs 的区别?
看完代码随想录之后的想法
深度搜索(dfs) 不需要借助队列来实现遍历, 靠的是递归. dfs 是遇到一个节点就直接访问它自己以及它四个方向上的节点, 因此会往一个方向一直走, 直到无路可走才换方向. 而广度搜索(bfs) 则是一圈一圈的向外访问, 因此很适合查找最近的节点.
并查集用来将两个元素添加到一个集合中, 同时可以判断两个集合是否在同一个集合中. (但是对于要分类的话, 还是有几个分类就要创建几个数组吧?)
拓扑排序就是先搜索入度为0的节点, 这些都是可以先处理的. 处理完之后就讲这些节点对应连接的节点的入度减一, 减一后如果入度为0, 则添加到带处理队列中, 在下一个循环处理. 如果处理完的节点和原始节点数量一致的话, 就完成了所有节点的处理. 否则存在环.
最后感谢卡哥, 你是真的想把我们教懂... 但是比起你看了那么多的资料, 那么多的书, AC 过那么多的题目, 确实短短的时间内没办法掌握的太深. 还需要继续二刷三刷.
自己实现过程中遇到哪些困难
最短路径部分内容确实挺多的, 容易混在一起, 容易忘. 对于算法本身也有吃不透的情况. 这部分怎么说呢, 也许需要更多的应用, 更多的实操, 才能在思考中慢慢成长. 目前是一知半解的状态的.