981. 基于时间的键值存储
题目链接
标签
数组 二分查找 排序
思路
时间戳根据时间生成,时间越早,则时间戳越小;时间越迟,则时间戳越大。例如 由2000-01-01 00:00:00.000生成的时间戳 小于 由2001-01-01 00:00:00.000生成的时间戳。所以 按照时间先后顺序加入本数据结构的值是 按照时间戳 升序排列 的,所以可以考虑在查找时使用二分查找。
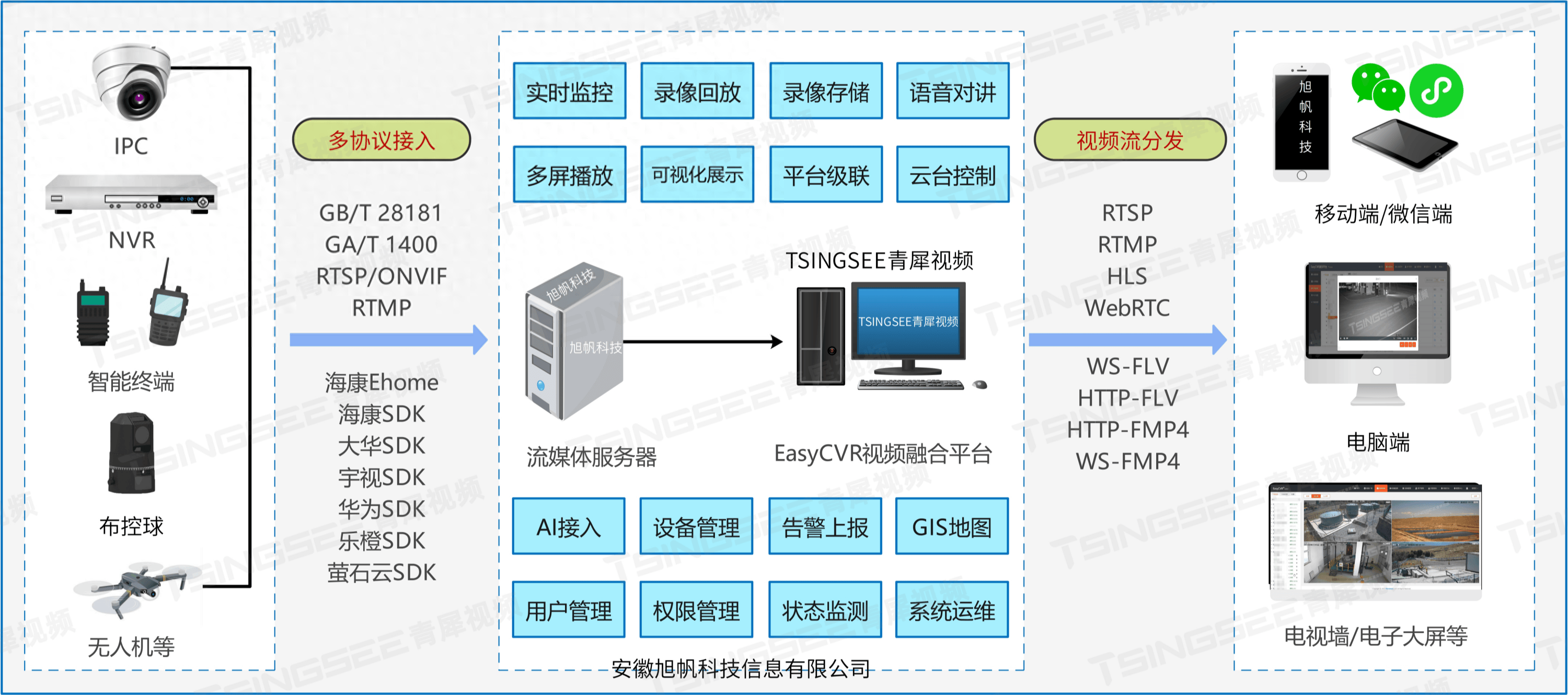
题目对本数据结构的实现作了提示:设计一个基于时间的键值数据结构,该结构可以在不同时间戳存储对应同一个键的多个值,并针对特定时间戳检索键对应的值。这就意味着要使用 Map 作为本数据结构的底层实现,key 为一个字符串,value 为这个字符串对应的 所有字符串及其时间戳组成的 集合。看似 value 也是 Map 类型,其实不然。由于这个集合是有序的,所以可以设计一个类 Pair 当作集合的元素类型,使用 List 来存储,Pair 类包含字符串 String value 及 其时间戳 int timestamp。所以最终存储数据的集合为 Map<String, List<Pair>>。
对于 void set(String key, String value, int timestamp),直接获取 key 对应的链表 list,如果没有,则创建一个,然后将新的 pair 放入链表 list。
对于 String get(String key, int timestamp),先获取 key 对应的链表 list,如果没有,则返回空字符串 ""。接下来就在链表 list 中使用二分查找查找指定的 timestamp。
由于要找到 指定timestamp 或其之前的 最大timestamp 对应的 value,所以使用二分法的 前驱实现,如果对二分法的后继和前驱不熟悉,则可以看这篇文章:算法——二分法。
代码
public class TimeMap {
// 对组,存放值的value和timestamp属性
private static class Pair {
String value;
int timestamp;
public Pair(String value, int timestamp) {
this.value = value;
this.timestamp = timestamp;
}
}
private final Map<String, List<Pair>> map = new HashMap<>();
public TimeMap() {}
public void set(String key, String value, int timestamp) {
// 获取key对应的list,如果没有,则新建一个ArrayList
List<Pair> list = map.computeIfAbsent(key, k -> new ArrayList<>());
list.add(new Pair(value, timestamp)); // 将新值放入key对应的list中
}
public String get(String key, int timestamp) {
List<Pair> list = map.get(key); // 获取key对应的list
if (list == null) { // 如果没有
return ""; // 则返回空字符串
}
// 由于要找到 指定timestamp 或其之前的 最大timestamp 对应的value,所以使用二分法的前驱实现
int left = 0, right = list.size() - 1;
while (left < right) {
int mid = left + (right - left + 1 >> 1);
if (timestamp < list.get(mid).timestamp) {
right = mid - 1;
} else {
left = mid;
}
}
// 如果能找到比 指定timestamp 小的value,则返回它;否则返回空字符串
return list.get(left).timestamp <= timestamp ? list.get(left).value : "";
}
}
219. 存在重复元素 II
题目链接
标签
数组 哈希表 滑动窗口
思路
本题就是判断 长度为 k 的区间内是否有重复元素。
判重 最常用的就是 哈希表HashSet,每次添加新值前先判断是否存在这个值,如果存在,则满足题目要求,返回true;否则才添加这个值。在 Java 中,可以在 add() 之前先使用 contains() 判断是否存在新值。不过,add() 是有返回值的,即返回是否添加成功,如果添加失败,则是因为有重复值。为了减少API的调用次数,从而减少耗费的时间,不使用 if (contains()) + add() 的组合,而是使用 if (!add()) 的组合。
比较复杂的是 控制区间长度为 k:从头到尾顺序遍历数组,每遍历一个元素都将元素加入 HashSet,则当遍历到索引为 k + 1 的元素时,HashSet 中的元素个数为 k 个,此时就得先去除索引为 i - k - 1 的元素,然后才能将索引为 i 的元素加入 HashSet。
代码
class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
Set<Integer> set = new HashSet<>(); // 存储数字的集合
for (int i = 0; i < nums.length; i++) {
if (i > k) { // 当遍历到索引为k + 1的元素后,集合的元素个数就等于k了
set.remove(nums[i - k - 1]); // 每次都需要去除一个元素
}
if (!set.add(nums[i])) { // 如果nums[i]添加失败,则说明在集合中存在nums[i]
return true; // 返回true
}
}
return false;
}
}
78. 子集
题目链接
标签
位运算 数组 回溯
思路
在高中数学中学到过这样的知识:对于一个 n n n 个元素的集合,它的子集共有 2 n 2^n 2n 个。可以用 排列组合 的思想理解它:子集中的元素是从原集合中选取的,对于这 n n n 个元素中的每一个元素,都有 选取 或 不选取 这 2 2 2 种行为,共需要选择 n n n 次,所以子集(含空集 ∅ \emptyset ∅,即不选择任何一个值;也含全集,即选择全部值)共有 2 n 2^n 2n 种情况。
本题就是对选取 n n n 个元素的模拟:
- 判断是否对所有元素都做了选择,如果是,则将选取的元素作为一个集合放到结果链表中;否则进行下列操作。
- 先 选取 这个元素,然后对下一个元素做选择。
- 然后 不选取 这个元素,然后对下一个元素做选择。
对于使用什么数据结构存储选取的元素,由于需要选取和不选取,即先将某个元素加入集合,然后再把这个元素从集合中删除,这是典型的 先进后出 操作,所以使用 栈 来存储选取的元素。
代码
class Solution {
public List<List<Integer>> subsets(int[] nums) {
res = new ArrayList<>((int) Math.pow(2, nums.length));
dfs(nums, 0);
return res;
}
private List<List<Integer>> res; // 存储结果的集合
private final LinkedList<Integer> sub = new LinkedList<>(); // 存储子集元素的栈
/**
* 对nums进行深度优先搜索
* @param nums 待遍历数组
* @param curr 当前元素索引
*/
private void dfs(int[] nums, int curr) {
if (curr == nums.length) { // 如果将nums遍历完毕
res.add(new ArrayList<>(sub)); // 将栈中的元素全部加入结果集合中
return; // 然后返回
}
// 先选取这个元素,并遍历下一个元素
sub.push(nums[curr]);
dfs(nums, curr + 1);
// 然后不选取这个元素,并遍历下一个元素
sub.pop();
dfs(nums, curr + 1);
}
}































![[ICS] Inferno(地狱) ETH/IP未授权访问,远程控制工控设备利用工具](https://img-blog.csdnimg.cn/img_convert/92c2e92a91b4f29ca1fb22112176dd24.jpeg)