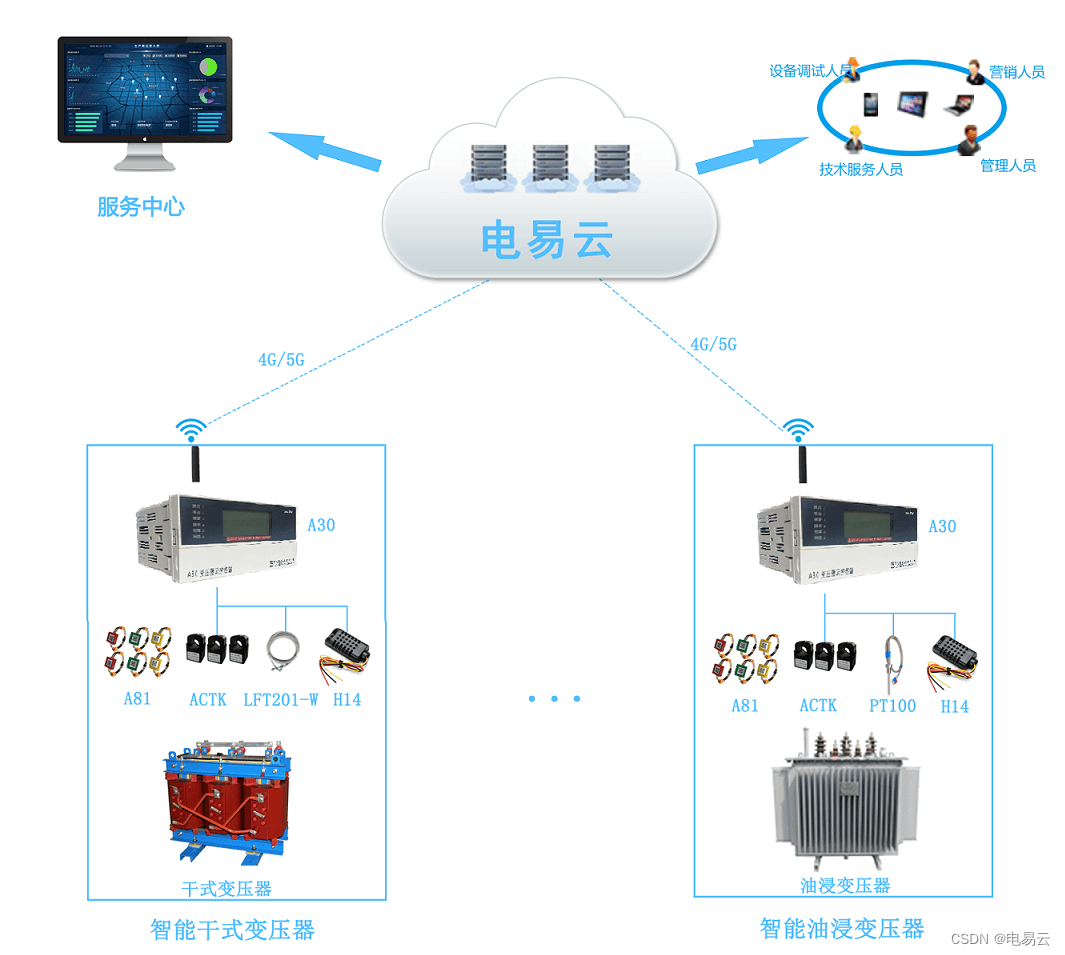
leetcode 1466
使用dfs 遍历图结构

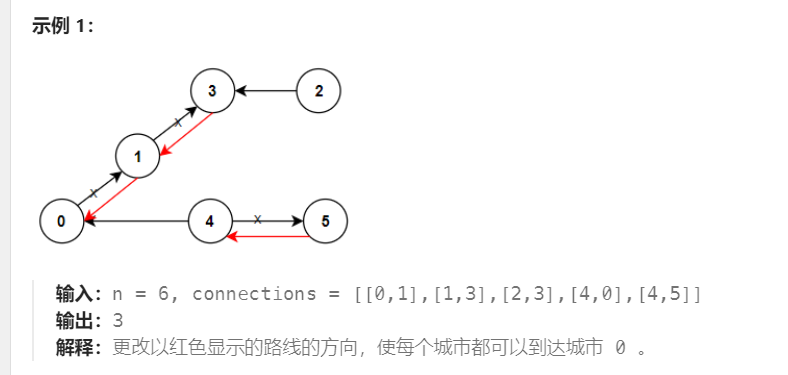
如图 node 4 -> node 0 -> node 1
因为节点数是n, 边长数量是n-1。所以如果是从0出发的路线,都需要修改,反之,如果是通向0的节点,例如节点4,则把节点4当作父节点的节点,之间的路线的方向都需修改。
两个节点间只有一条方向,所以可以确定如何修改,取决和0节点的关系。
如图 node 0 -> node 1 -> node 3 <- node 2
dfs (0, -1, e) -> dfs (1, 0, e) -> dfs(3, 1, e)
e[3][0].first = 1 == parent continue;
e[3][1].first = 2 != parent 但是 e[3][1].second =0, 所以不增加长度。
如图 (0 -> 1), 使用 e[0][1] = 1 和 e[1][0] = 0 的表达方式。
数据结构
vector<vector<pair<int, int>>>
这个数据结构是一个二维的向量(vector),其中每个元素都是一个pair<int, int>类型的元素。可以将其理解为一个邻接表的表示方式。
具体来说,这个数据结构可以表示一个有n个顶点的图,其中每个顶点v都有一个对应的向量e[v],该向量存储了与顶点v相邻的顶点以及它们之间的边的信息。
每个pair<int, int>元素表示一条边,其中第一个int表示与顶点v相邻的顶点,第二个int表示边的权重或其他相关信息。
例如:e[0] = { {1, 2}, {3, 4}},则表示顶点0与顶点1之间有一条权重为2的边,以及顶点0与顶点3之间有一条权重为4的边。
例如: e[0][1] = {1,2}
这种数据结构在表示稀疏图时非常有效,因为它只存储了实际存在的边,而不需要为所有可能的边分配空间。同时,通过使用向量而不是链表,可以提高访问和遍历的效率。
vector<vector > 和 vector<vector<pair<int, int>>>
vector<vector<int>>和vector<vector<pair<int, int>>>在内存上的差别主要体现在存储的数据类型和元素的大小上。
对于vector<std::vector<int>>,它是一个二维向量,其中每个元素都是一个一维向量,而每个一维向量存储了一系列int类型的元素。因此,内存中会按照一维向量的方式存储每个元素,每个元素之间是连续存储的。这意味着在内存中,整个二维向量是一段连续的内存空间。
而对于vector<vector<pair<int, int>>>,它也是一个二维向量,但每个元素是一个一维向量,而每个一维向量存储了一系列pair<int, int>类型的元素。因为pair<int, int>占用的内存空间更大,所以每个元素之间的存储空间可能不是连续的,而是分散存储的。
具体来说,对于vector<std::vector<int>>,内存中的存储布局可能类似于以下示意图:
[元素1][元素2][元素3]...
而对于vector<vector<pair<int, int>>>,内存中的存储布局可能类似于以下示意图:
[元素1-1][元素1-2][元素2-1][元素2-2][元素3-1][元素3-2]...
其中,每个元素1-1、1-2、2-1、2-2等表示pair<int, int>类型的元素。
因此,vector<std::vector<int>>在内存上是连续存储的,而vector<vector<pair<int, int>>>可能是分散存储的,每个元素之间的存储空间可能不是连续的。这也是它们在内存上的主要差别。
向量和链表
向量和链表在存储效率上有一些差异,这取决于具体的操作和使用场景。
向量(vector)是一个动态数组,它使用连续的内存块来存储元素。这意味着向量可以通过索引来快速访问元素,并且在尾部进行插入和删除操作的效率也很高。然而,在向量中间进行插入和删除操作可能涉及到移动元素的操作,这会导致效率降低。此外,当向量的大小超过当前分配的内存容量时,可能需要重新分配更大的内存块,并将现有元素复制到新的内存块中,这也会带来一定的开销。
链表(linked list)是由一系列节点组成的数据结构,每个节点包含数据和指向下一个节点的指针。链表的插入和删除操作在任意位置都很高效,因为它只需要调整节点的指针,而不需要移动其他元素。然而,链表的随机访问效率较低,因为需要从头节点开始遍历链表直到找到目标位置。此外,链表的存储空间相对于向量来说更加分散,因为每个节点需要额外的指针来指向下一个节点。
综上所述,向量适用于需要频繁进行随机访问、尾部插入和删除操作的场景,而链表适用于需要频繁进行插入和删除操作、对随机访问性能要求较低的场景。选择使用哪种数据结构取决于具体的操作和使用需求。