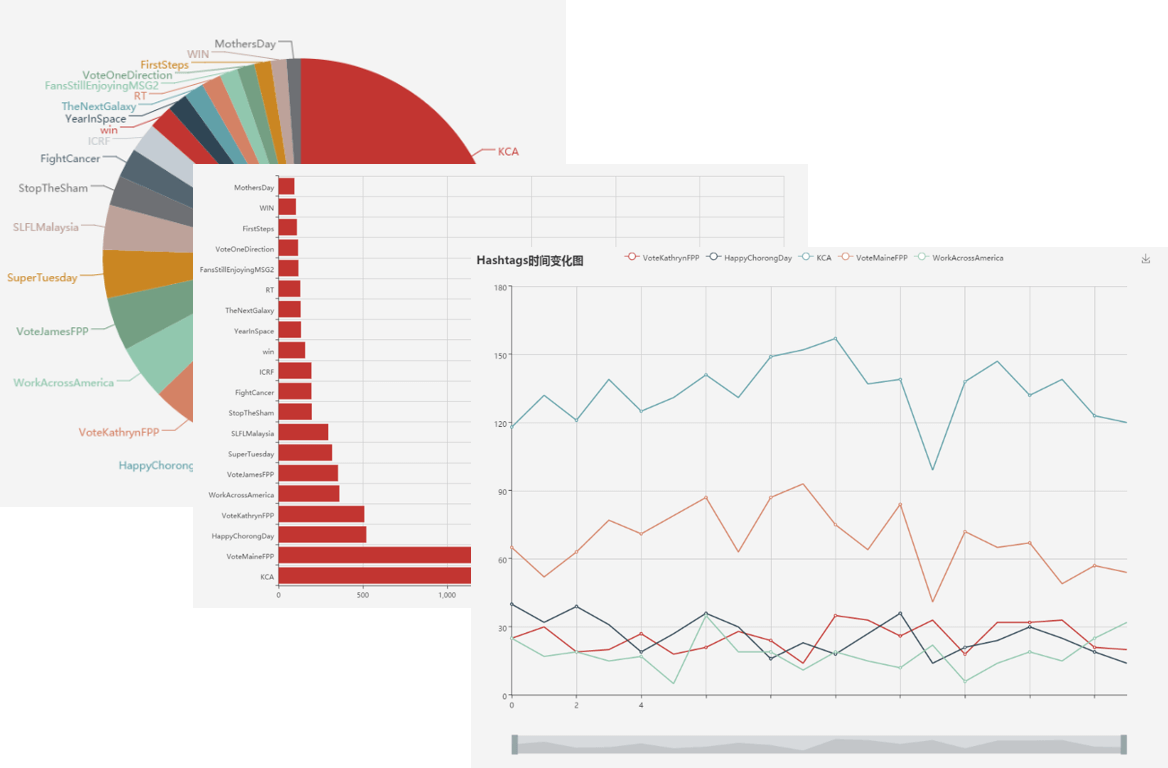
最近在做舆情分析,需要执行比较复杂的任务流程(例如同时执行人名识别、相关机构识别、90分类),传统Bert无法胜任,因此尝试使用大模型进行处理。
下面的一些提示词是我用来准备数据的,这些数据可以按照不同的难度混和并进行训练。另一些是用来做舆情分析的,在能力较强的大模型上可以直接使用。以下所有案例都是与电力系统相关的。
系统提示词:
你是一个电力行业的专家,你的能够依据电力行业特点对给出的中文舆情关键词进行解释。
你能够严格依照提示中的要求进行内容生成
系统参数:
top_p= 0.7,
temperature= 0.95,
场景1:模拟社交媒体
我需要针对特定舆情关键词,生成四个社交媒体风格的负面句子。关键词可以直接出现在句子中,也可以不直接出现在句子中。
经验1: 一次只做一个事情,我把这个任务和“模拟新闻媒体”放在了一起,导致提示词非常长,模型效果也不好,输出结果格式也很混乱。
经验2: 步骤1中,我让模型先思考一下(但是不要输出),起到了立竿见影的效果。一定程度上,这能代替fewshot,因为模型已经知道了一些舆情的真实含义(如果不知道,可以把相关的含义拼到提示词中,或者在场景2中生成舆情解释,并训练模型学会这些解释)。
经验3: 指定风格,可以用“模拟不同年龄段、文化水平的语气”类似的提示词。指定数量和一些具体要求(例如两个带关键词,两个不带关键词),可以参照步骤2和3.
经验4: 输出格式,json不是很好控制,以后要输出json的时候,也许可以参照“输出格式”的做法,按照固定的顺序输出。例如,身份证识别任务中,可以写“请换行输出姓名、籍贯、生日、家庭住址,用#分割“”。
提示词:
`请帮我编写4个关于“{0}”的负面舆情例子,每个例子之间用####隔开。
请仿照社交媒体的写法,语气、形式更加多样。可以是陈述、反问、感叹等语气。
每次输出时,请模拟不同年龄段、文化水平的语气。
步骤1:在撰写例子之前,你应该先理解“{0}”在电力中的含义(但是不要输出)。
步骤2:在撰写前两个例子的时候,请你在行文中隐含的表达与“{0}”有关的内容,不要直接提及“{0}”这个词汇。
步骤3:在撰写最两个例子的时候,可以在行文中的过程中提及“{0}”。
输出格式:每个例子用"####"隔开。请直接输出例子的原始内容,每个例子之间不要过于相似。不要输出“例子1”之类的字眼。`
效果:
假设关键词是停电,模拟舆情如下:
#### 这大热天的,真是要命啊!空调电扇全歇菜,连个凉快地儿都找不着,这日子没法过了!
#### 又是突如其来的黑灯瞎火,看来今晚的电影是泡汤了,这频繁的“意外”什么时候是个头啊?
#### 天啊,怎么又停电了?冰箱里的食物都要化了,这可是我刚买的啊!真是让人头大。
#### 停电停得我游戏进度都丢失了,这电力供应能不能稳定一点?还让不让人好好玩耍了!
场景2:舆情解释
我需要对一些舆情进行解释。我认为在训练中,这可以增强一些小模型的对于舆情的理解。针对一些困难的舆情词汇(行业黑化)进行训练,也可以一定程度上注入相关知识(我做过认知实验,例如人员a开发了计算机系统b,反过头来问系统b是由谁开发的,模型能够答对,但是如果问模型a的职业,模型可能无法推断出a是一名开发人员)。
经验5: pua大法。背景说明2,能一定程度提升输出质量,类似于“如果你做的好,我会给你500元钱”。
提示词:
请对舆情词汇【{}】进行解释分析,要求语言流畅、符合电力行业特点。
背景说明1:你需要对这些词汇进行解释,以保证其他大模型和非电力行业人员能够理解舆情词汇的核心内涵有透彻理解。
背景说明2:你的这些解释还会被用于大规模的舆情分析,因此请你务必给出最优质的答案。
效果:
假设关键词是违纪通报,舆情解释如下:
在电力行业,"违纪通报"通常指的是对行业内工作人员违反工作纪律、职业道德或相关法规的行为进行的正式通知和公开批评。
这种通报是对个体或集体不当行为的认定和警示,其目的在于加强电力行业内部的纪律性,维护行业秩序,确保电力供应的安全稳定,以及提升整个行业的服务质量和社会形象。
在强调严格的安全管理和高效的服务标准下,违纪通报有助于形成一种遵纪守法、廉洁自律的行业文化。
通过这种方式,电力行业能够对外展示其透明度和自我监督的能力,同时对内部员工起到教育和震慑的作用。
场景3:舆情分析-方式1
现在正式进入舆情分析。需要将【原文】与【关键词列表】中的词汇进行匹配。关键词列表有90个,即便是glm4网页版这样的先进模型,也可能出错,因此需要对提示词进行修改。
第一种方式,我们尝试把原文摘要成abstract,然后再分析。这种方式对于超长文献中的一两句负面舆情几乎没有识别能力。具体使用还要看需求方的要求。
经验6: 在提示词中,可以起一些变量名,这会加强模型的理解、遵循能力。例如提示词中,我使用了abstract和keyword两个特殊标识,起到了正向作用。
提示词:
请阅读【原文】中的内容,理解其核心主旨,然后判断是否包含关键词列表中的负面舆情。
步骤:理解文章主旨,然后生成摘要abstract,然后判断absctrct与候选列表中的哪个keyword有关。
要求1:请识别列表中每个负面舆情是否出现在abstract中。只匹配一个keyword。
要求2:请不要判断其他类型的舆情。
要求3:只输出与关键词相对应的强烈的负面舆情。
要求4:不要输出其他总结性的语句。
输出格式:针对每个识别到的舆情,单独输出为json,json的key值为:abstract、keyword
原文:【....】
关键词列表
【安全事故
邻避运动....】
效果:
根据原文内容,文章主要讲述了国家电网公司的福利待遇情况,并未提及关键词列表中的负面舆情。
以下是针对要求的输出:
{
"abstract": """文章主要介绍了国家电网公司的福利待遇,
包括工资收入、津贴补贴、六险二金等,并强调了其稳定性及吸引力。""",
"keyword": "薪酬待遇"
}
由于原文中并未提及任何负面舆情的关键词,故在摘要中并未识别到相关负面舆情。
场景4:舆情分析-方式2
与方式1相比,方式2更加详细。这里使用了思考过程,类似于step-by-step,如果不使用思考过程的话,能明显看到判断不准确(我刻意要求模型识别“具有强烈负面情绪”的舆情,去掉思考过程后,会出现一些错误答案)、更全面(针对一段话,加思维过程能识别出3个潜在舆情,不加的话只能识别一个)。
【!!!风险!!!】 此提示词在一些情况下的输出不够稳定,需要进一步完善提示词的约束条件,或者加一些后处理。此提示词可坑出现胡乱猜测,因此可以在提示词中加上“请找出直接相关的舆情”等字眼。在场景7中进行了改进。
经验6: 在提示词中,可以想变成意向,起一些变量名,这会加强模型的理解、遵循能力。例如提示词中,我使用了abstract和keyword两个特殊标识,起到了正向作用。
经验7: 让模型显式的思考,可以看提示词中关于thought的内容。
经验8: 模型很难达到性能平衡,场景3能得到更宏观的视角,如果把场景3和带thought的场景4的两种提示词的结果合并,效果会更好,即把宏观视角和微观视角结合。
带thought的提示词:
请阅读【原文】中的内容,理解其核心主旨,然后判断是否包含关键词列表中的负面舆情。
步骤:针对每个识别到的舆情,用引号表明原文引用ref,给出简要的思考过程thought,最后给出对应的关键词keyword。
要求1:请识别列表中每个负面舆情是否出现在原文中。每个舆情只匹配一个keyword。
要求2:请不要判断其他类型的舆情。
要求3:只输出与关键词相对应的强烈的负面舆情。
要求4:不要输出其他总结性的语句。
输出格式:针对每个识别到的舆情,单独输出为json,json的key值为:ref、thought、keyword
原文:【{}】
负面舆情列表
【安全事故
邻避运动.....】
我还尝试不让模型进行thought。下面的例子1包含了4个答案,可以看到带thought的回答更合理、更深入,能发掘字面之下的含义(例如蒙西地区那个案例,看似在说有序用电,实际上是电力缺口)。
带thought例子1:
{
"ref": "6月5日,有网友爆料邵阳市云山国家森林公园景区救援电话和紧急求助设备全都无法使用一事引发关注。",
"thought": "原文中提到了救援电话和紧急求助设备无法使用,这直接关联到了安全问题。",
"keyword": "安全隐患"
}
{
"ref": """施工人员要将电线杆架到老太太的耕地里,老太太以占地为由要求施工队给予赔偿,
施工队同意赔偿,但是认为刘老太太提出的赔偿标准过高,双方因此引起矛盾纠纷,刘老太太就阻拦施工。""",
"thought": "这里描述了一起因电线杆建设而引起的占地赔偿纠纷,涉及到了‘矛盾纠纷’这一负面舆情。",
"keyword": "矛盾纠纷"
}
{
"ref": "由于蒙西地区电煤价格上涨,新能源出力不足,导致出现有序用电的情况",
"thought": "原文提到了新能源出力不足导致有序用电,这表明存在电力缺口的问题。",
"keyword": "电力缺口"
}
{
"ref": "",
"thought": """原文中并未直接提及负面舆情关键词列表中的内容,所描述的场景和成绩都是积极正面的,
没有涉及到负面事件或问题。""",
"keyword": null
}
对应不带thought的例子1:
{
"ref": "【6月5日,有网友爆料邵阳市云山国家森林公园景区救援电话和紧急求助设备全都无法使用一事引发关注。】",
"keyword": "设备故障"
}
{
"ref": """发现施工现场被一位60多岁的老太太拦着,导致施工无法进行。
民警迅速上前了解情况,原来,施工人员要将电线杆架到老太太的耕地里,老太太以占地为由要求施工队给予赔偿,
施工队同意赔偿,但是认为刘老太太提出的赔偿标准过高,双方因此引起矛盾纠纷,刘老太太就阻拦施工。""",
"keyword": "法律纠纷"
}
{
"ref": "由于蒙西地区电煤价格上涨,新能源出力不足,导致出现有序用电的情况",
"keyword": "有序用电"
}
{
"ref": "没有出现强烈的负面舆情。",
"keyword": "无"
}
下面的例子2,针对同一段话,带thought的回复更详细,识别了两个相关舆情,而不带thought的只识别了一个:
带thought的例子2:
{
"ref": "若只把国家电网进行物理上的拆分并不能解决根本问题",
"thought": "原文中提到拆分国家电网并不能解决根本问题,暗示了拆分可能带来的问题或困难,与拆分矛盾相关。",
"keyword": "拆分矛盾"
}
{
"ref": "拆分国家电网的可能性不大,输配分开倒是可能。",
"thought": "这里提到输配分开的可能性,而输配分开常常伴随着一定的争议和问题,与输配分开相关的负面舆情可能包括输配分开后的管理、服务等问题。",
"keyword": "输配分开"
}
不带thought的例子2:
{
"ref": "若只把国家电网进行物理上的拆分并不能解决根本问题",
"keyword": "电网拆分"
}
场景5:信息抽取与简单判断
该场景下,同样是带思考过程的更合理。我需要针对一段话,完成下面提示词中的6个任务。
经验9: 模给出输出示例,能让模型的输出更稳定。
带思考过程提示词:
请阅读【原文】中的内容,理解其核心主旨,并完成以下任务。
任务1:请判断原文是否有电力相关。只要原文出现了电力相关词汇,即视为相关。
任务2:请判断是否与电力行业相关。此处的行业相关指电力设备、发电、电力政策等广泛含义。
任务3:请判断是否与国家电网相关。只要出现涉及到国家电网相关的机构,即视为相关。供电公司也属于国网。
任务4:请提取所有人名。
任务5:请提取所有与国家电网有关的机构名称。此处的机构包括但不限于国网子公司、供电所、内部部门等。
任务6:请判断,文章中是否有负面舆情内容。此处的负面舆情包括但不限于表达批评、阐述负面信息、重大安全事故和不良社会影响等。
输出格式:每个任务单独输出一行,每行先给出简要的思考过程,然后给出正确答案。思考过程与答案用####分割。不要复述任务内容。
输出示例:由于原文未提到国网公司相关机构,因此与国网无关####否
要求:前三个任务回答是或否,任务4、5以*分割,任务6回答是或否。
原文:【{}】
效果:
在机构识别、是否与国网相关等任务上,带thought效果更好。
带thought:
任务1:原文中提到了“南方电网”,这是明显的电力相关词汇,因此视为电力相关。####是
任务2:原文提到的是“南方电网专家委员会副主任委员”的违纪违法问题,并没有直接涉及到电力设备、发电或电力政策等内容,因此不能判定为电力行业相关。否
任务3:原文提到的是南方电网而非国家电网,因此不能判定为国家电网相关。####否
任务4:原文中提到的人名有“余建国”。####余建国
任务5:原文中提到的与国家电网有关的机构名称没有出现,只提到了“南方电网专家委员会”。####(无相关机构名称)
任务6:原文提到了“涉嫌严重违纪违法”,这属于负面舆情内容。####是
不带thought:
【任务1】是
【任务2】是
【任务3】否
【任务4】余建国
【任务5】南方电网*南方电网专家委员会
【任务6】是
在舆情判断上,也可以在个别案例中看到效果对比(正确答案应该为“是”):
带thought:
任务6:原文中提到了涉企乱收费的负面情况,并指出了市场监管总局对此问题的治理行动,
包含了对乱收费行为的批评和负面信息的阐述,因此存在负面舆情内容 ####是
不带thought:
【任务6】否
场景6:加强
场景4仍然会有错误,更精准的识别方式可以参照下面的例子。我曾经把十几个正面/负面的例子混在一起,发现下面的提示词能比较灵敏的识别出这十几个例子中的负面舆情。
经验10: 步骤4起到了循环操作的作用,类似于for循环。
有了for循环的支持,可以认为场景6中真正做到了逐字逐句判断。实际上,这个过程也可以借助python实现(用python把原始段落分开,多调用几次大模型),但是在这里我把包含了多个换行符的段落放了进去,能减少调用开销。
加强后的提示词:
背景:你现在需要对互联网上的文本进行舆论检测。
任务:请判断原文的主题与候选词列表的词汇是否相关。
步骤1:你需要认真阅读原文,理解每一个段落的主旨。段落以“\n”分割。
步骤2:详细阅读每一个段落,结合步骤1的段落主旨,判断是否存在强烈的负面舆情。
步骤3:如果存在负面舆情X,则在候选词列表中筛选出与X最相关的词汇W,输出W和原文中与舆情直接相关的句子。
步骤4:对每一个段落执行完步骤1-3后,汇总结论,直接输出所有的词汇W。
要求1:步骤3中,请在候选词列表范围内进行筛选,不允许出现候选词列表之外的词汇。
要求2:步骤3中,如果无法找到相关词汇W,则输出“发现新类型舆情”。
要求3:步骤4中,如果没有负面舆情,则输出“无负面舆情”;如果有,则直接输出与负面舆情相关的词汇,以空格分隔。
原文:【
近日,全国各地2024年2月电网企业代理购电价格陆续公布。\n
以下为目前各地电网企业公布的代理购电价格表,顺序依次为:\n
江苏、安徽、广东、深圳、山东、山西、河南、浙江、上海、四川、江西、湖南、天津、新疆、广西、福建。\n
北京、河北、冀北、重庆、黑龙江、辽宁、吉林、内蒙古东部、内蒙古电力集团、湖北、青海、宁夏、陕西、甘肃、海南、贵州、云南等地电价尚未公布(截至2024年1月29日13:00)。\n
】
###候选词列表:
【安全事故
邻避运动.....
】
加强方案输出效果:
步骤1:理解每个段落的主旨
第一段提到2024年2月全国各地的电网企业代理购电价格陆续公布。
第二段说明接下来将列出已公布的代理购电价格表。
第三段列举了部分已经公布电价的地区。
第四段指出还有部分地区截至2024年1月29日尚未公布电价。
步骤2:判断负面舆情
根据原文,目前没有明显的负面舆情。
步骤3:筛选相关词汇
由于没有负面舆情,不需要进行此步骤。
步骤4:汇总结论
根据以上分析,输出结论:无负面舆情。
场景4输出:
场景四的thought中存在一定幻觉和过度推理,做出了错误的解答(原文中没有负面舆情)。
{
"ref": "以下为目前各地电网企业公布的代理购电价格表,顺序依次为:...北京、河北、冀北、重庆、黑龙江、辽宁、吉林、内蒙古东部、内蒙古电力集团、湖北、青海、宁夏、陕西、甘肃、海南、贵州、云南等地电价尚未公布(截至2024年1月29日13:00)。",
"thought": """原文中提到了部分地区的电价尚未公布,这可能引发人们对于电价改革的关注和担忧,
从而与电价相关的负面舆情可能出现。""",
"keyword": "电价改革"
}
场景7:改进
针对场景4进行改进。能减少过度推理。主要改进就是让prompt描述更加精准,增加了“直接、明显、负面”等修饰语(有点像画图)。
经验11: 下面提示词的要求2中,对thought进行判断,起到了反思的作用。反思很重要,类似于吴恩达最近的翻译代理。下面提示词中thought可以不输出,简单测试发现不输出thought对结果没有影响,
改进后的提示词:
请阅读【原文】中的内容,理解其核心主旨,然后判断是否包含关键词列表中的负面舆情。
步骤:针对每个识别到的明显的、负面的舆情,用引号表明原文引用ref,给出简要的思考过程thought,最后给出对应的关键词keyword。
要求1:请判断关键词列表中每个keyword,是否与ref中的舆情直接相关,只识别直接相关的、明显的、负面的舆情。
要求2:如果在thought过程中,发现ref中不包含明显的、负面的舆情,则keyword输出为xxx。
要求3:keyword只能从关键词列表中选择。
输出格式:针对每个识别到的舆情,单独输出为单一的json,json的key值为:ref、thought、keyword。
输出要求:只输出json。不要输出其他任何内容