LLM大语言模型(GPT)的分布式预训练与微调及部署
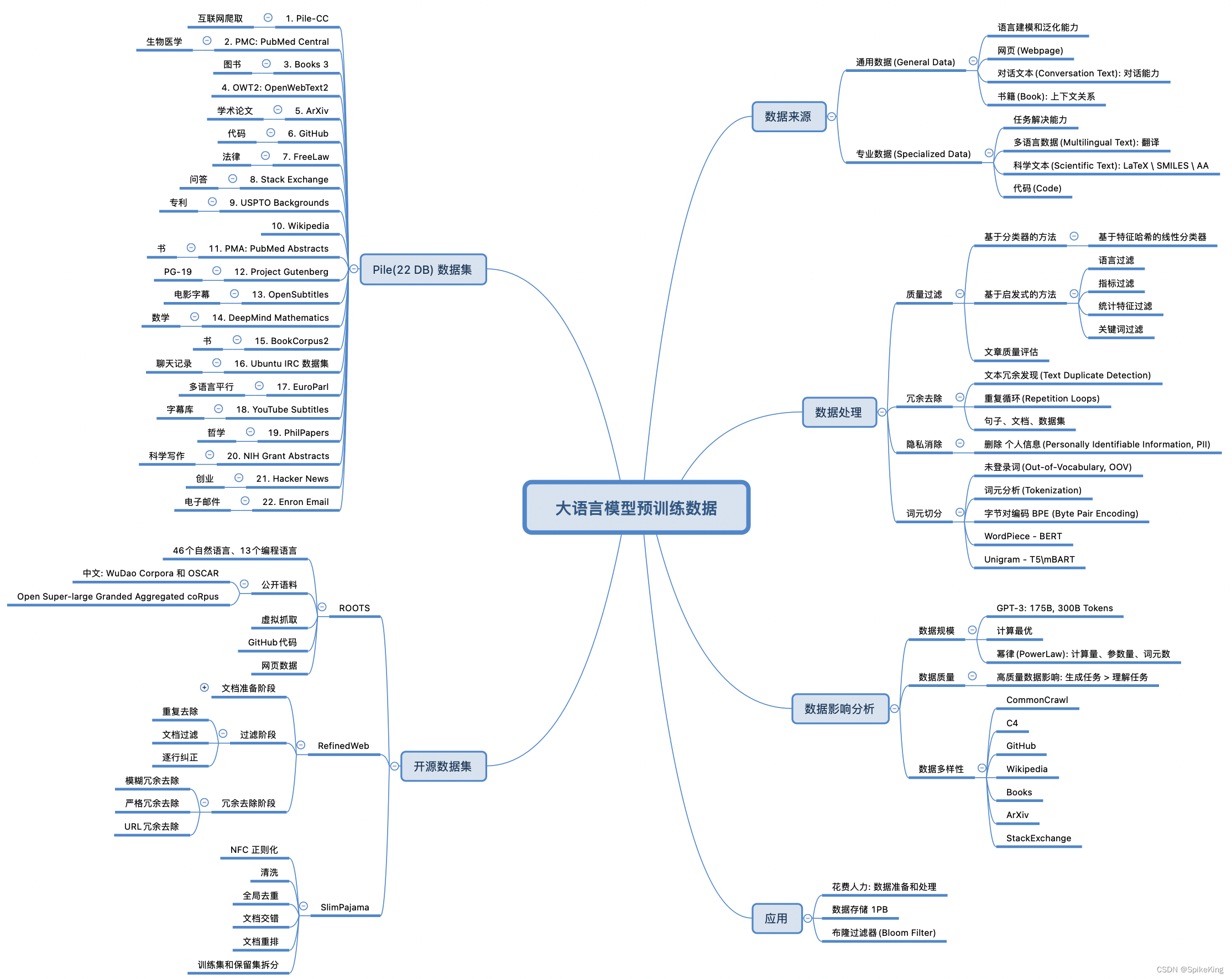
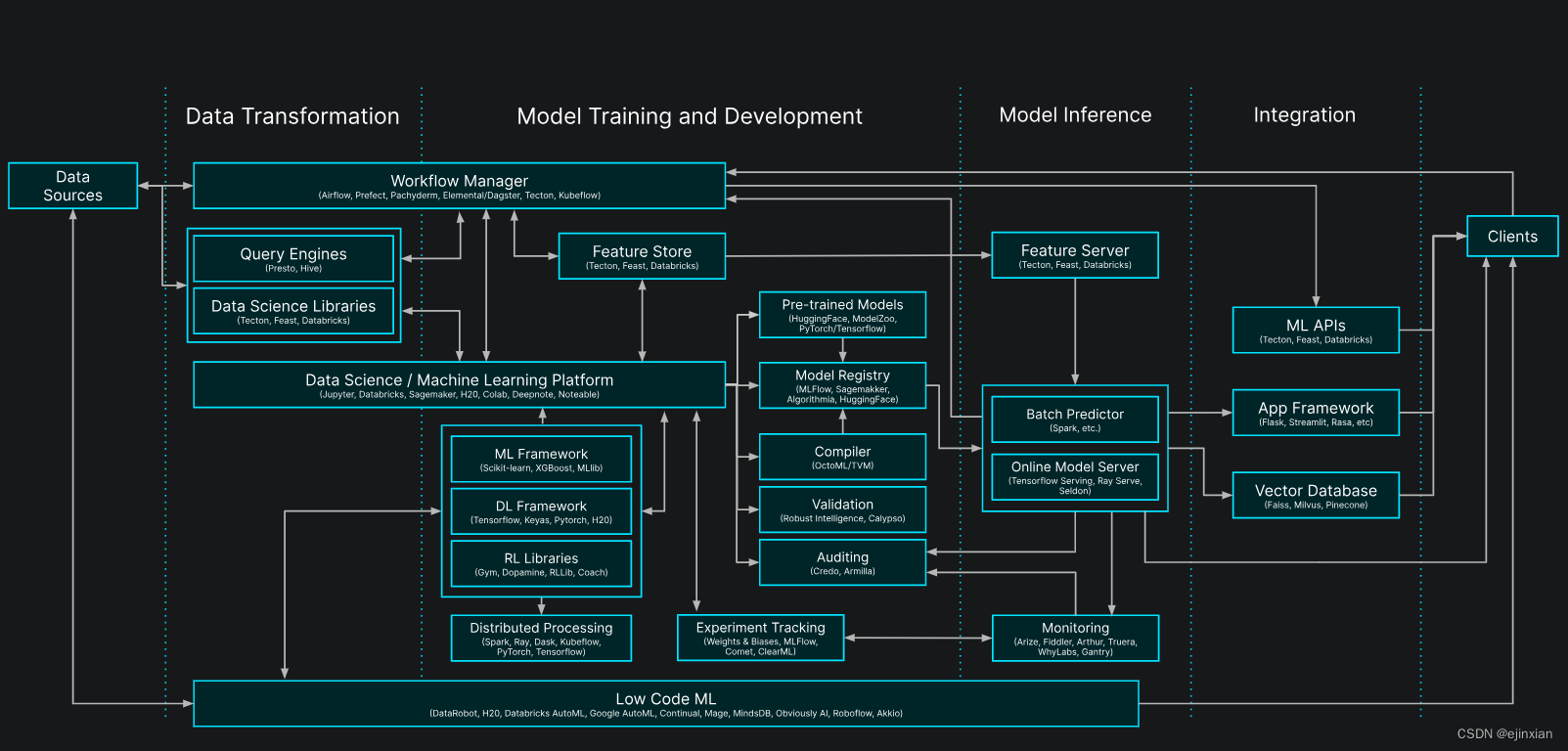
实现方案:设计并实现了一个大规模语言模型(GPT)的分布式预训练,结合RAG(文档、MySQL)、Agent、LLM连网等技术在基座上微调,以提高模型在特定领域任务上的性能和效率。
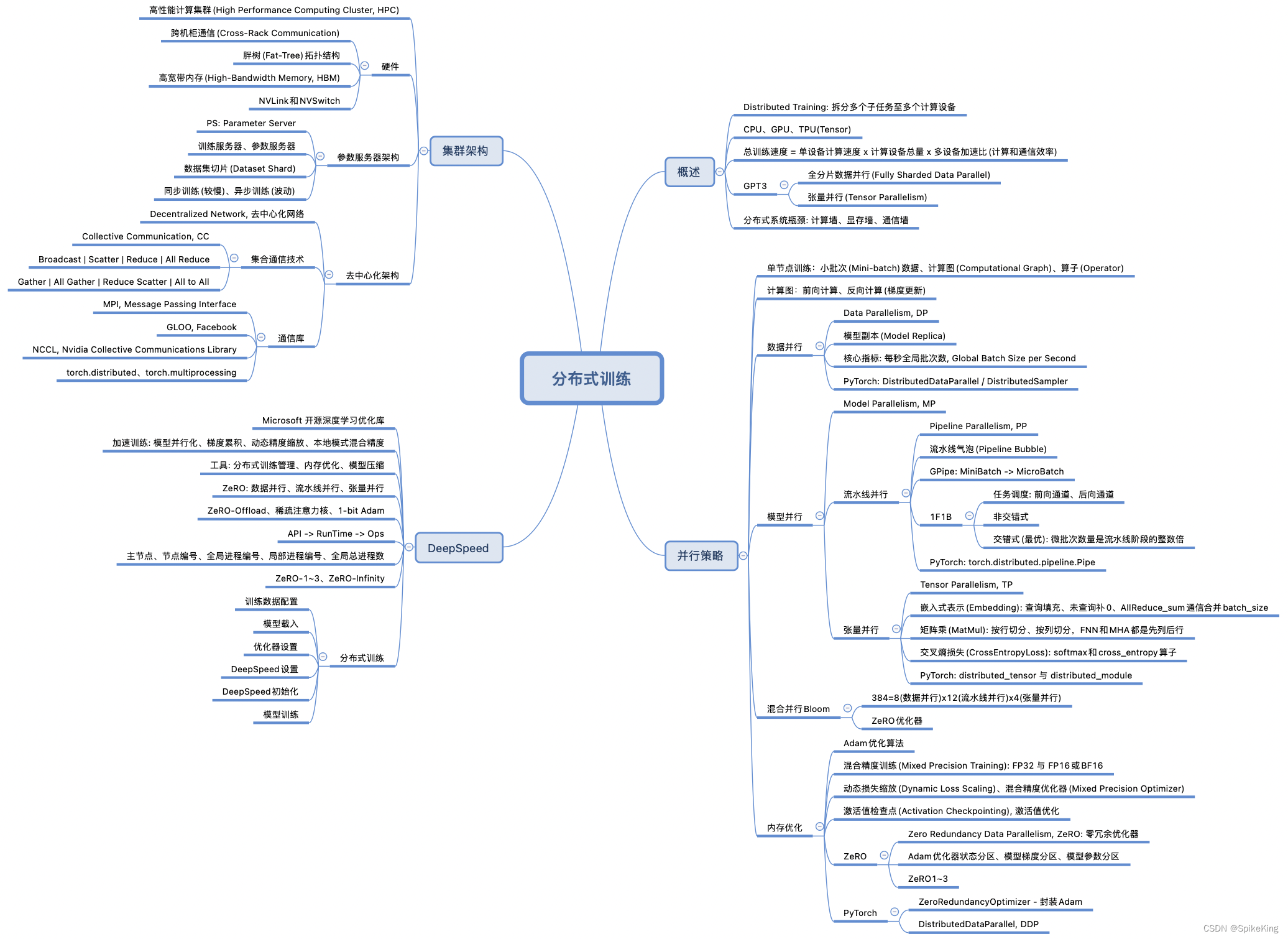
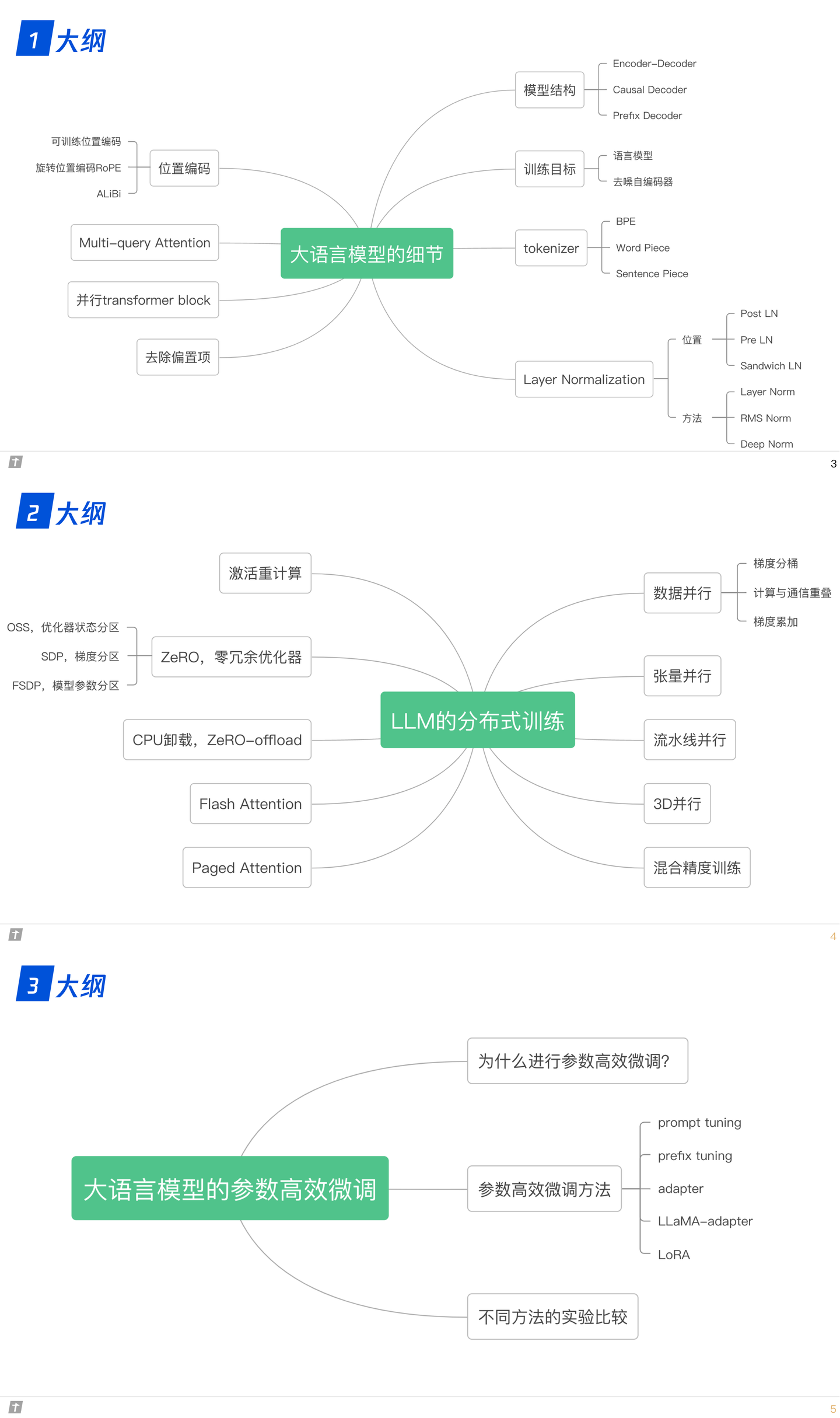
技术栈:PyTorch, CUDA, NCCL, DistributedDataParallel (DDP), torch分布式训练init_process_group , Transformer,GPT
项目细节
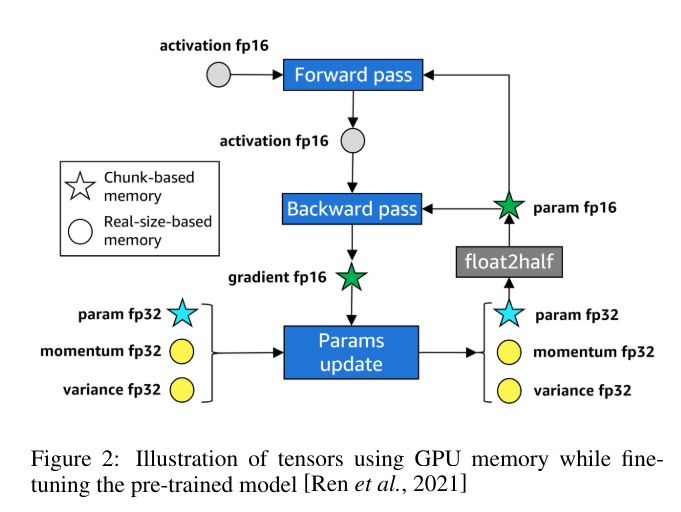
- 使用NCCL作为后端,通过init_process_group初始化分布式环境,实现了模型的高效并行训练。
- 应用了余弦衰减(Cosine Decay),Warmup learning(预热学习)和梯度裁剪技术,优化了模型的稳定性和收敛速度。
- 实现了模型的微调,通过加载预训练的权重,针对特定任务进行了进一步的训练和优化。
成就:成功预训练了一个具有1.24亿(124M)参数的GPT模型