欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/136924304
大语言模型的分布式训练是一个复杂的过程,涉及到将大规模的计算任务分散到多个计算节点上。这样做的目的是为了处理巨大的模型和数据集,同时,提高训练效率和缩短训练时间。
- 模型并行:这是分布式训练中的一个重要概念,涉及到将模型的不同部分放置在不同的计算节点上。例如,一个大型的Transformer模型可能会被分割成多个小块,每个小块在不同的GPU上进行计算。
- 数据并行:在数据并行中,每个计算节点都有模型的一个副本,并且每个节点都在模型的不同部分上工作,但是都在处理不同的数据子集。这样可以在多个节点上同时进行模型训练,从而提高效率。
- 通信优化:由于分布式训练需要在不同的节点之间传输数据,因此优化通信以减少延迟和带宽消耗是非常重要的。这包括优化数据传输的方式和减少必要的数据传输量。
- 资源管理:有效地管理计算资源,如GPU和内存,是确保分布式训练顺利进行的关键。这可能涉及到在不同的节点之间平衡负载,以及确保每个节点都有足够的资源来处理其分配的任务。
- 容错机制:在分布式系统中,节点可能会失败,因此需要有容错机制来保证训练过程的稳定性。这可能包括保存检查点以便于从中断处恢复训练,或者在节点失败时重新分配任务。
具体实现更加复杂,需要考虑到算法的具体细节和硬件的特性。
1. 并行策略
在大型语言模型的分布式训练中,主要采用以下几种并行策略来提高训练效率和优化内存使用:
数据并行(Data Parallel): 数据并行是将训练数据集分割成多个小批量,然后分配给多个计算设备(如GPU)并行处理。每个设备都有模型的完整副本,并独立计算梯度。计算完成后,所有设备的梯度会聚合起来更新模型参数。这种方法适用于模型较小而数据量较大的情况。
模型并行(Model Parallel): 模型并行涉及将模型的不同部分分布到不同的计算设备上。每个设备负责模型的一部分计算,并在需要时与其他设备交换信息。这种策略适用于模型太大,无法在单个设备上完整存储的情况。
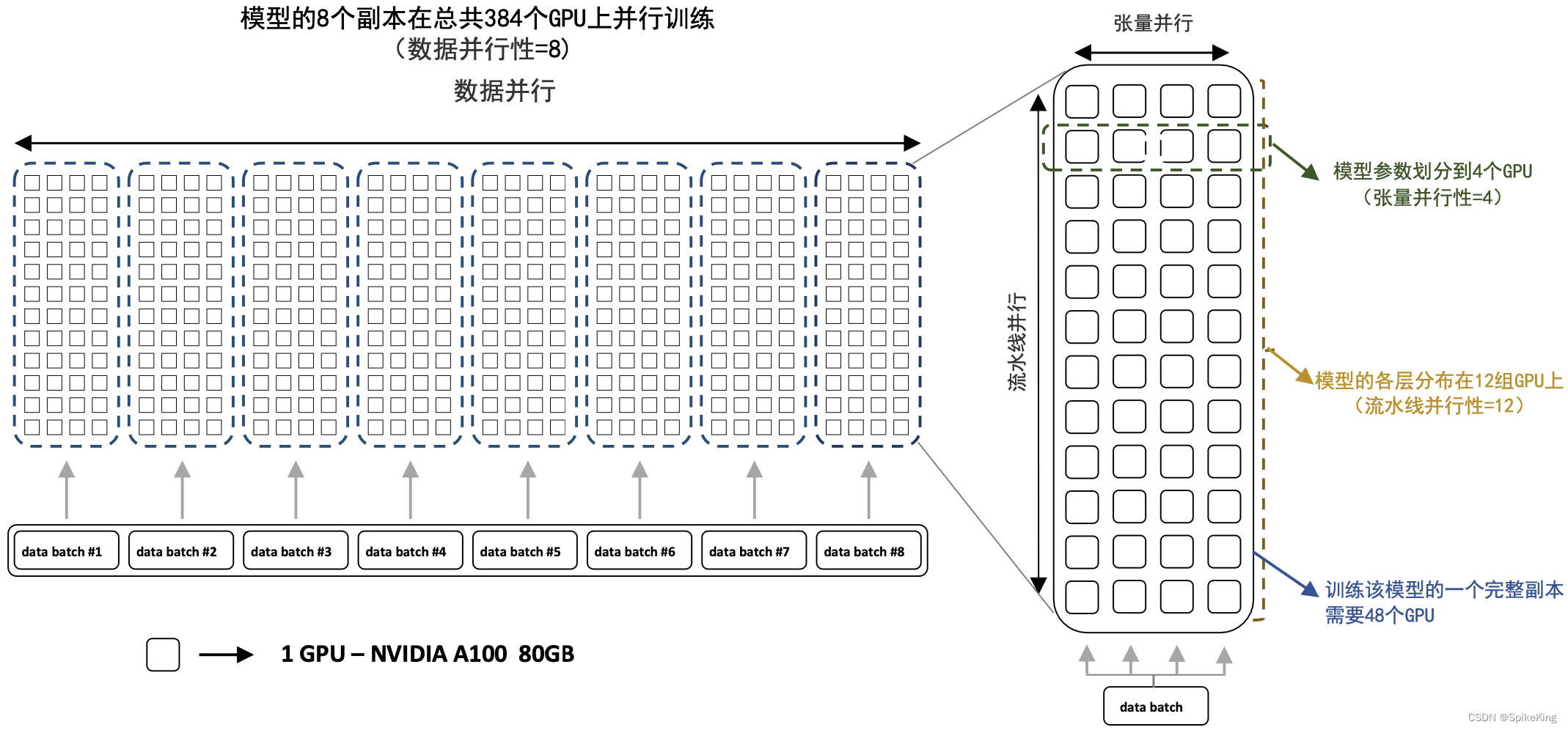
混合并行(Hybrid Parallel): 混合并行结合了数据并行和模型并行的优点。它可以在不同层面上进行优化,例如,某些层使用模型并行,而其他层使用数据并行。这种策略旨在平衡计算和通信开销,以适应不同的训练需求。混合并行,如下:
内存优化: 内存优化技术,如ZeRO(Zero Redundancy Optimizer),通过减少冗余数据和更有效地管理内存来减少每个设备上的内存占用。这允许更大的模型在有限的硬件资源上进行训练。
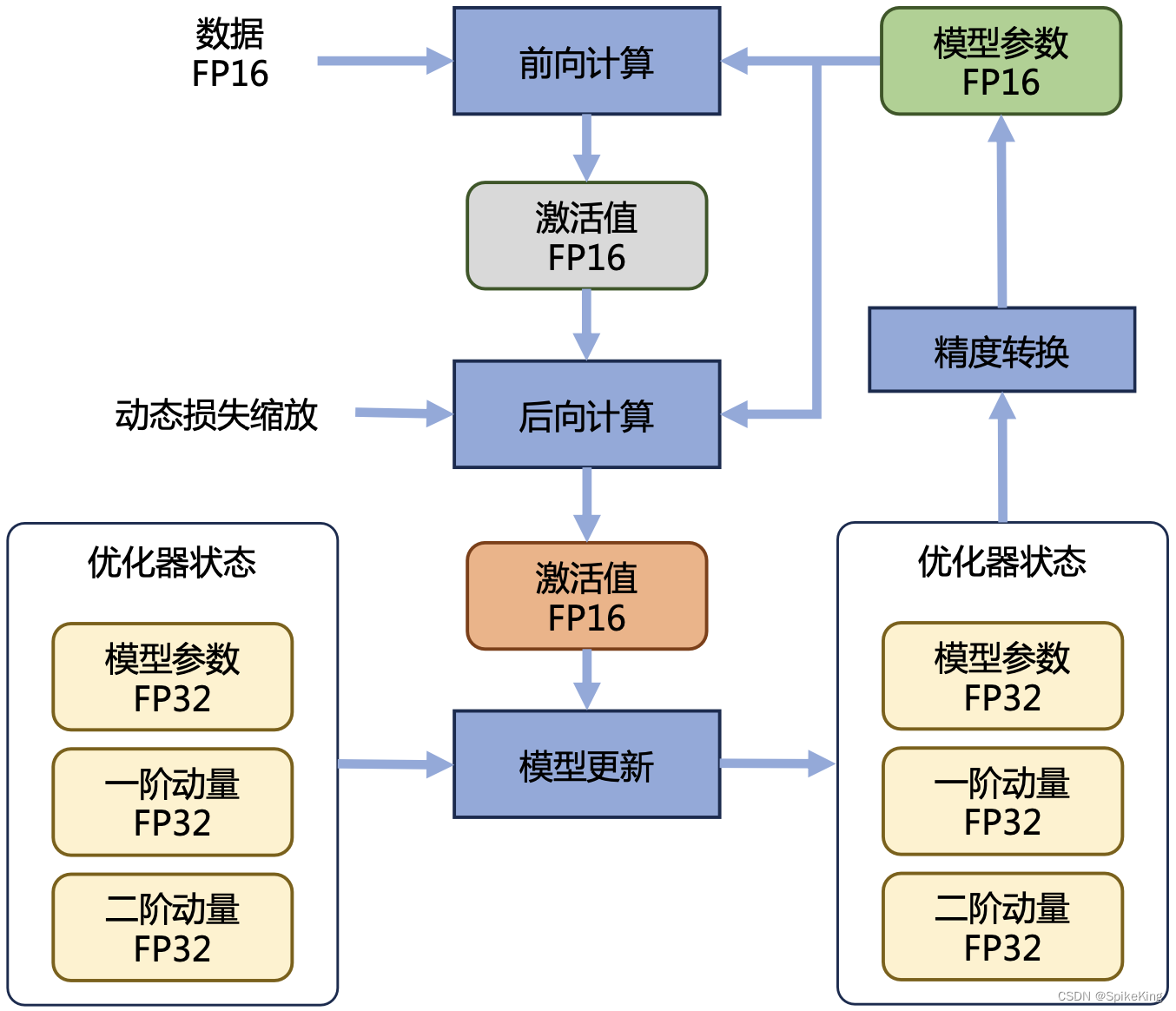
混合精度的优化过程,如下:
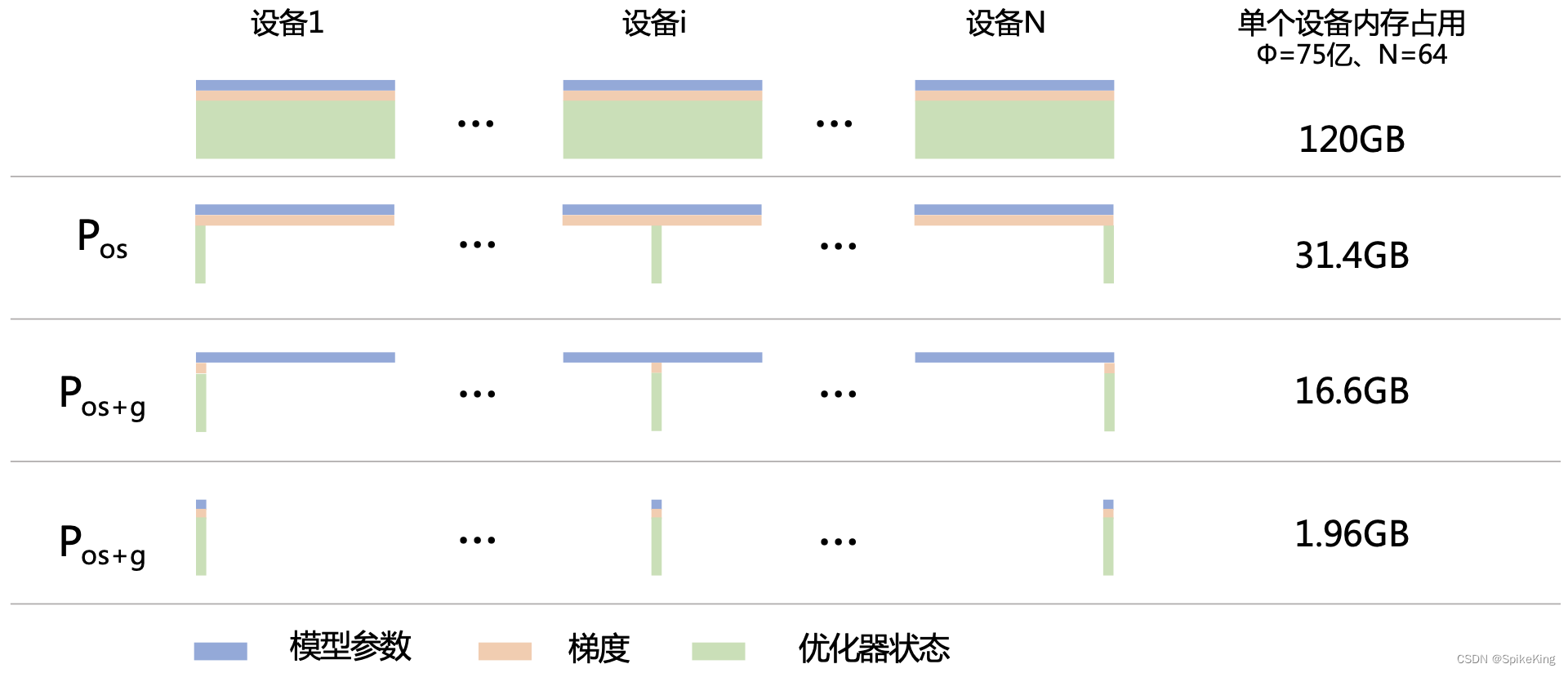
Zero Redundancy Data Parallelism,ZeRO,零冗余优化器,1-3策略,如下:
这些并行策略的选择和实现取决于具体的模型大小、数据集大小、硬件配置和训练目标。
2. 集群架构
在大型语言模型的分布式训练中,集群架构主要有两种类型,即参数服务器架构和去中心化服务器架构。
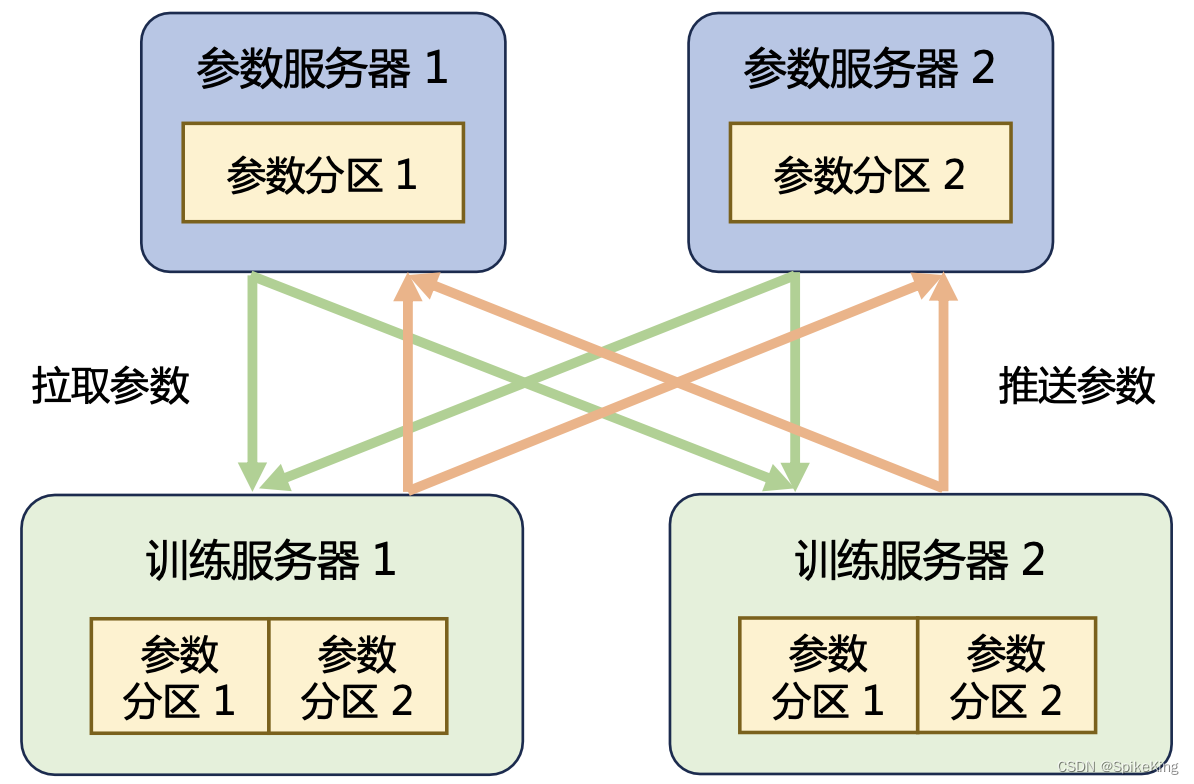
参数服务器架构:通常包括参数服务器(PS)节点和工作节点。PS节点负责存储和更新模型参数,而且,工作节点则负责计算梯度,并且,将其发送给PS节点以更新模型参数。这种架构易于实现和扩展,但是,随着模型和数据规模的增长,可能会遇到通信瓶颈。
去中心化服务器架构:即没有中心化的参数服务器。在这种架构中,每个工作节点都存储模型的一部分,并与其他节点直接通信以同步更新。这种架构可以减少通信延迟,提高扩展性和容错能力,但是,实现起来更为复杂。
这两种架构都旨在利用多个计算节点的资源来并行处理大规模的数据和模型,从而加速训练过程。在实际应用中,这两种架构有时会结合使用,以优化性能和资源利用率。例如,可以在去中心化架构中使用参数服务器来管理某些全局状态,或者,在参数服务器架构中使用去中心化的通信策略来减少瓶颈。
参数服务器架构,如下:
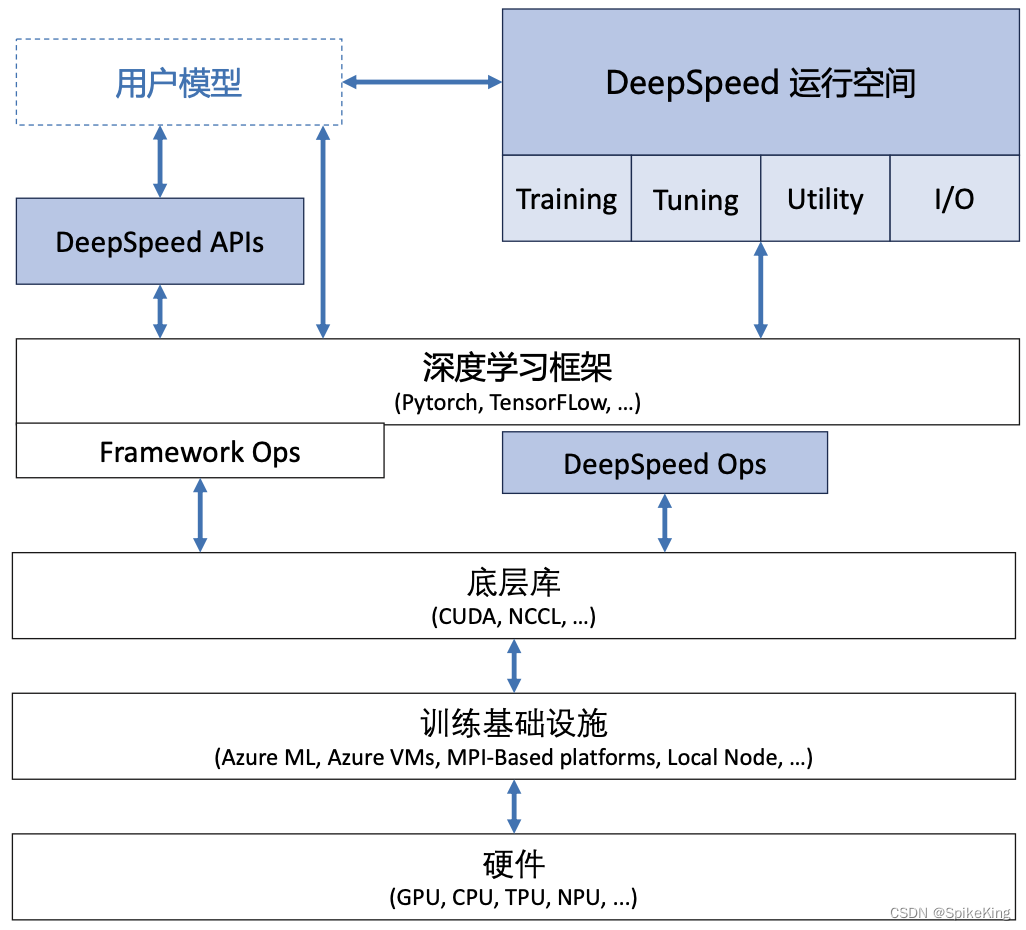
3. DeepSpeed
DeepSpeed是一个开源深度学习优化库,由微软研究院开发,专为大规模模型的分布式训练设计。提供了一系列创新的优化技术,提高训练速度、扩展模型大小,并减少计算资源的需求。
DeepSpeed的核心特点包括:
- ZeRO优化:ZeRO(Zero Redundancy Optimizer)是DeepSpeed的一个关键组件,它通过优化数据并行训练中的内存使用,允许在有限的硬件资源上训练更大的模型。ZeRO通过减少冗余数据来降低每个GPU的内存需求,从而实现了更高的数据并行效率。
- 模型并行性:DeepSpeed支持模型并行性,允许将大型模型分布在多个GPU上,每个GPU处理模型的一部分。
- 流水线并行性:通过流水线并行处理,DeepSpeed可以进一步提高训练效率,允许不同阶段的模型训练同时进行。
- CPU和NVMe负载:DeepSpeed可以将部分计算和数据存储卸载到CPU和NVMe存储,从而减轻GPU的负担,使得单个GPU可以训练更大的模型。
- 稀疏注意力:DeepSpeed提供了稀疏注意力机制,支持更长的序列输入,这对于某些类型的语言模型特别有用。
这些特性使DeepSpeed成为训练大型语言模型的有力工具,尤其是在资源有限的情况下。通过减少所需的计算资源,使研究人员和开发者能够探索和训练以前无法实现的大型模型。
DeepSpeed架构: