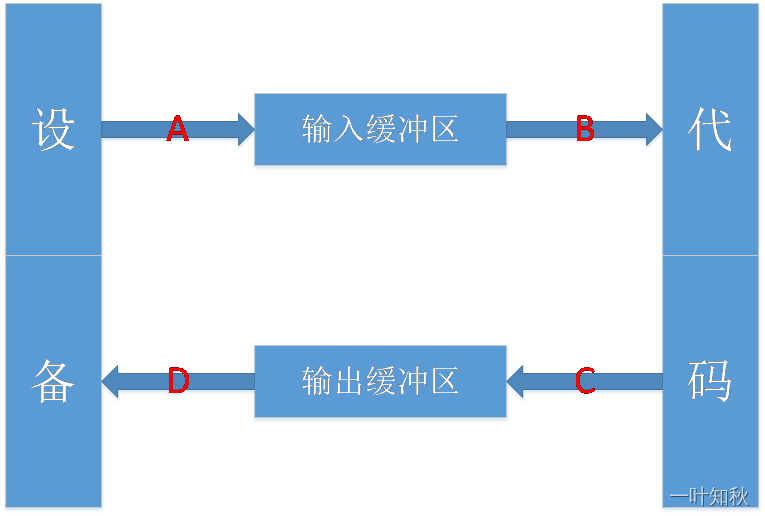
深入解析:训练损失与测试损失的关系
在深度学习的世界中,理解训练损失与测试损失之间的关系是至关重要的。这不仅关系到模型的性能,还直接影响到模型在实际应用中的有效性和可靠性。本文将深入探讨训练损失的好坏对测试损失的影响,帮助读者更好地理解如何评估和优化深度学习模型。
一、训练损失与测试损失的基本概念
训练损失
训练损失反映了模型在训练数据集上的性能。它是模型预测结果与实际结果之间差异的量化,通常通过一个损失函数来计算,如均方误差(MSE)或交叉熵损失。训练损失的主要目标是指导模型学习,减少误差,使模型能够在训练数据上尽可能地进行准确预测。
测试损失
测试损失衡量的是模型在未见过的数据集(测试集)上的表现。测试损失是检验模型泛化能力的重要指标,即模型应用于新数据的效果如何。理想情况下,一个具有良好泛化能力的模型在测试集上的表现应接近其在训练集上的表现。
二、训练损失对测试损失的影响
训练损失的降低
当训练损失持续降低时,这通常意味着模型正在从训练数据中学习到有用的模式和关联。理论上,这应该导致测试损失也随之降低,因为模型的预测能力得到了提高。然而,这种正面影响只在模型未过拟合时有效。
- 过拟合:当模型过度学习训练数据中的细节和噪声,以至于失去了泛化能力时,即使训练损失很低,测试损失也可能很高。这是因为模型学习到了训练数据的特定特征,而这些特征并不适用于新的、未见过的数据。
训练损失的稳定性
一个稳定的训练损失通常表明模型已经达到了对当前训练数据的最优拟合。在这种情况下,关键是观察测试损失是否也表现出稳定性。如果测试损失随着训练损失的稳定而增加,这可能是过拟合的征兆。
三、如何平衡训练与测试损失
为了确保训练损失的降低能有效转化为测试损失的降低,以下策略至关重要:
1. 交叉验证
使用交叉验证可以有效评估模型的泛化能力。通过将数据分成多个小组,轮流使用其中一组作为测试集,其余作为训练集,可以帮助确保模型在各种数据子集上都表现良好。
2. 正则化技术
引入正则化(如L1、L2正则化)可以减少模型复杂度,防止过拟合。这有助于提高模型在未见数据上的表现。
3. 早停法(Early Stopping)
早停法是一种防止神经网络过拟合的技术。如果测试损失开始增加,即使训练损失仍在下降,也应停止训练。这有助于避免过拟合,保存最优模型状态。
四、总结
训练损失的好坏对测试损失确实有重大影响,但这种影响并非总是直接正相关。为了确保深度学习模型在实际应用中具有良好的性能和泛化能力,重要的是要通过各种技术和策略来监控和优化训练过程中的损失。理解并应用这些策略,将有助于开发出更加健壮和有效的深度学习模型。