深度学习中的损失函数种类与适用场景
深度学习中的损失函数种类与适用场景:精确度量模型误差的艺术
在深度学习的浩瀚星河中,损失函数(Loss Function)是那盏明灯,照亮模型优化的航道,引导我们从混沌迈向清晰。损失函数衡量模型预测与真实标签之间的误差,是模型学习的核心动力。本文将深入探讨几种常见损失函数的原理、适用场景,并通过代码示例,助你掌握如何在不同任务中选用合适的损失函数。
一、均方误差(Mean Squared Error, MSE)
均方误差是最直观的损失函数之一,适用于回归任务,计算预测值与真实值差的平方和的均值。
公式:[(\frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y_i})^2])
代码示例(使用PyTorch):
import torch
import torch.nn as nn
# 假设y_true和y_pred为张量
y_true = torch.tensor([2.5, 3.0, 4.5])
y_pred = torch.tensor([2.0, 2.5, 4.5])
loss_fn = nn.MSELoss()
loss = loss_fn(y_pred, y_true)
print(loss.item()) # 输出损失值
适用场景:图像去噪、回归预测等追求预测值与真实值尽量接近的场景。
二、交叉熵损失(Cross-Entropy)
交叉熵损失广泛应用于分类任务,衡量预测概率分布与真实分布的差异,特别适用于多分类问题。
公式:[-\sum_{i=1}^{n}y_ilog(p_i)]
代码示例(使用TensorFlow):
import tensorflow as tf
# 假设y_true为独热编码,y_pred为预测概率
y_true = tf.constant([[0., 1., 0.]]) # 正确分类
y_pred = tf.constant([[0.2, 0.8]]) # 预测概率
loss_fn = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
loss = loss_fn(y_true, y_pred)
print(loss.numpy()) # 输出损失值
适用场景:多分类任务,如图像分类、文本分类等。
三、Hinge损失(Margin Loss)
Hinge损失,又称为最大边距损失,常见于支持向量机(SVM)中,用于最大化间隔,增强分类边界。
公式:[ max(0, 1 - y_i(\mathbf{w}^Tx_i + b))]
代码示例(使用PyTorch):
import torch
from torch.nn import MarginRankingLoss
# 假设y_true为正负标签(1/-1),y_pred为预测得分
y_true = torch.tensor([1, -1])
y_pred = torch.tensor([0.8, 0.6])
loss_fn = MarginRankingLoss(margin=1.0)
loss = loss_fn(y_pred[None, :], y_true[None])
print(loss.item())
适用场景:二分类,特别是在关注间隔最大化的场景,如支持向量机。
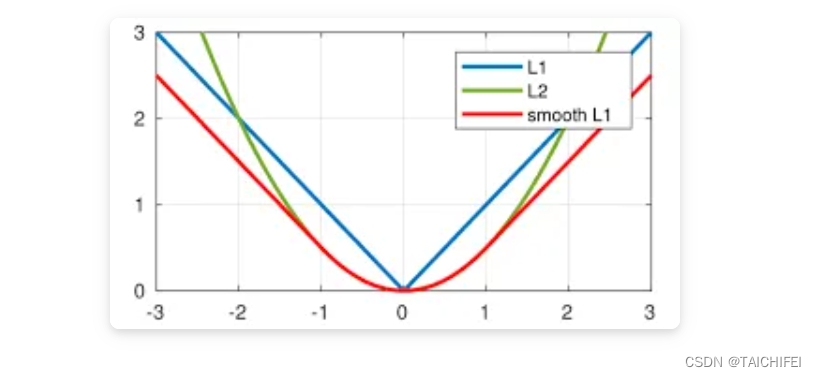
四、Huber损失
Huber损失是均方误差的改进版,对异常值更鲁棒,当误差较大时损失增长放缓,减少离群点的影响。
公式:[ \begin{cases}
\frac{1}{2}(y_i - \hat{y_i})^2 & \quad |y_i - \hat{y_i}| \leq \delta \
\delta(|y_i - \hat{y_i}| - \frac{1}{2}\delta), & otherwise
end{cases}]
代码示例(使用NumPy):
from sklearn.metrics import hinge_loss
y_true = [2, 1, 3]
y_pred = [1.5, 2.5]
# 将delta设为1作为示例
delta = 1
huber_loss = sum(hinge_loss(y_true - y_pred, delta)) / len(y_true)
print(huber_loss)
适用场景:回归任务,特别是在存在异常值时,要求模型对误差有一定鲁棒性。
结语
损失函数的选择是模型构建的关键,不同的任务和数据特性决定了损失函数的适用性。理解每种损失函数的原理,结合实际应用,才能在深度学习的海洋中掌舵前行,抵达精准预测的彼岸。本文所列举的代码示例,旨在提供实践的起点,鼓励你深入探索更多场景,发现损失函数的微妙与奥秘。