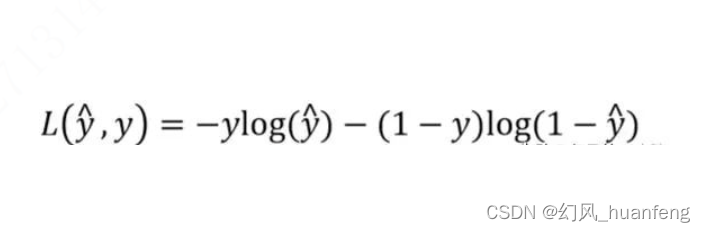以下以GRU为例讲解RNN作为解码器时如何根据用户、商品特征信息hidden生成评价。
解码器部分代码如下:
class GRUDecoder(nn.Module):
def __init__(self, ntoken, emsize, hidden_size):
super(GRUDecoder, self).__init__()
self.word_embeddings = nn.Embedding(ntoken, emsize)
self.gru = nn.GRU(emsize, hidden_size, batch_first=True)
self.linear = nn.Linear(hidden_size, ntoken)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.word_embeddings.weight.data.uniform_(-initrange, initrange)
self.linear.weight.data.uniform_(-initrange, initrange)
self.linear.bias.data.zero_()
def forward(self, seq, hidden): # seq: (batch_size, seq_len), hidden: (nlayers, batch_size, hidden_size)
seq_emb = self.word_embeddings(seq) # (batch_size, seq_len, emsize)\
output, hidden = self.gru(seq_emb, hidden) # (batch_size, seq_len, hidden_size) vs. (nlayers, batch_size, hidden_size)
decoded = self.linear(output) # decoded shape = (batch_size, seq_len, ntoken), e.g., (256, 18, 20004)
return func.log_softmax(decoded, dim=-1), hidden
在训练时,解码器会有两个输入:一是编码器提取的用户、商品特征,二是用户对商品的评价。
评价是文字,在训练开始前已经转换成了Token ID, 比如I love this item, 每个单词会对应词典里的一个元素并配上ID,转换后就成了向量格式了[5, 64, 89, 13]。·
self.word_embeddings(seq)中的word_embedding是Token向量,它是一个矩阵,行数和词典的元素数量相同,每一行是32维度的词向量(维度是用户设定的,Word2Vec一般用200维度)。这一步像查词典,对着ID从word_embedding取第x行的向量。
output, hidden = self.gru(seq_emb, hidden)的过程如下:
- 初始状态设置成
hidden,即从编码器提取的信息 seq_emb则是评价序列,计算从左往右开始,第t个文字的计算会受到[0, t-1]文字的影响,生成output的特征用来预测t+1个文字是什么
所以,以I love this item为例,代码的评价序列为[bos] I love this item,解码器会收到[bos] I love this,理想情况下,它应该生成I love this item.
下面的代码 体现出序列前面会加上[bos]:
def sentence_format(sentence, max_len, pad, bos, eos):
length = len(sentence)
if length >= max_len:
return [bos] + sentence[:max_len] + [eos]
else:
return [bos] + sentence + [eos] + [pad] * (max_len - length)
output对应的是生成文本的特征,它经过线性层输出20004维度的向量,第i个维度对应词典里第i个字的生成概率。
func.log_softmax(decoded, dim=-1) 先会对20004维度的向量进行Softmax计算,这样确保所有词语生成的概率相加为1,然后取对数。
text_criterion = nn.NLLLoss(ignore_index=pad_idx) # ignore the padding when computing loss是在计算取了logsoftmax的概率和真实文本概率(这是一个0/1矩阵)的差,定义如下
N L L = − y i log y ^ i NLL=-y_i\log \hat y_i NLL=−yilogy^i
因为 y i y_i yi是一个0/1矩阵,实际上NLL计算的是真实的文字预测概率 N L L = − log y ^ i NLL=-\log \hat y_i NLL=−logy^i, NLLLoss本身并不计算对数,所以需要使用log_softmax对概率取对数
文本生成的损失写成公式的形式为:
l Text = − 1 N ∑ t = 1 N log y ^ i = − 1 N ∑ t = 1 N log P ( y t ∣ y 1 , y 2 ⋯ y t − 1 ) l_\text{Text}=-\frac{1}{N}\sum_{t=1}^N \log \hat y_i= -\frac{1}{N}\sum_{t=1}^N \log P(y_t|y_1,y_2\cdots y_{t-1}) lText=−N1t=1∑Nlogy^i=−N1t=1∑NlogP(yt∣y1,y2⋯yt−1)
N N N是文本的长度, P ( y t ∣ y 1 , y 2 ⋯ y t − 1 ) P(y_t|y_1,y_2\cdots y_{t-1}) P(yt∣y1,y2⋯yt−1)强调的是 t t t个文字的生成只基于前面的文字。
测试的时候,编码器提取的特征已知,然后文本评价只给[bos], 每一步计算下一位文字的概率,取概率最大的(这个是贪心算法生成文本,也可以加入一些随机程度采样增加文本多样性)