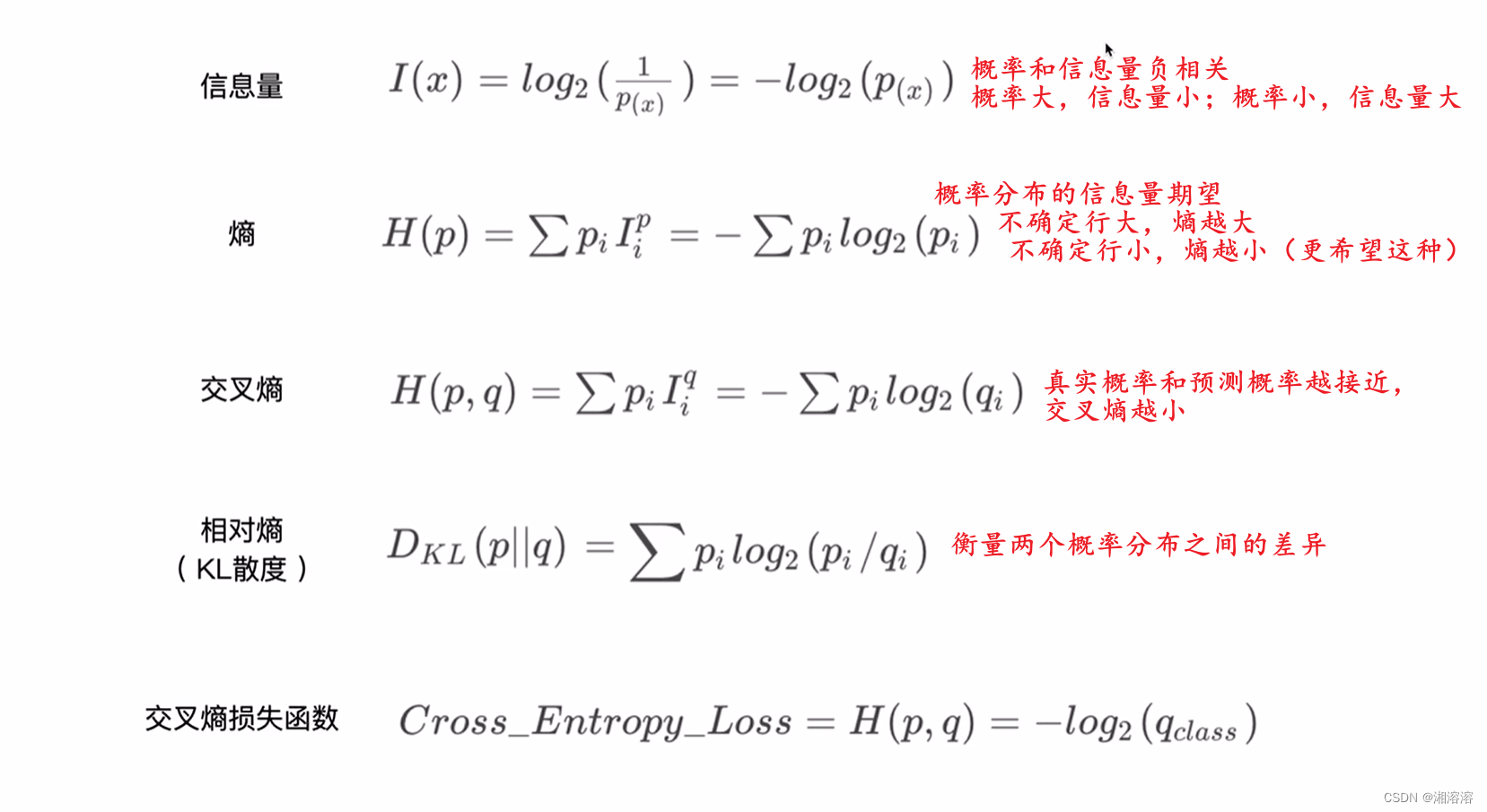深入理解交叉熵损失CrossEntropyLoss - 损失函数
flyfish
损失函数的定义
在机器学习和统计学中,损失函数(Loss Function),也称为代价函数(Cost Function)或误差函数(Error Function),用于量化模型预测与实际目标之间的差距。损失函数的值越大,表示模型预测越不准确;值越小,表示模型预测越准确。损失函数在模型训练过程中起着关键作用,因为它指导模型参数的优化方向。
损失函数的命名
损失函数的名字源于其表示的“损失”或“代价”的概念。以下是对这一命名的进一步解释:
- 损失的概念:
- 在任何预测任务中,我们希望模型的预测尽可能接近实际结果。然而,由于模型的限制和数据的复杂性,预测通常会有误差。这个误差可以被视为一种损失,因为它表示了模型的性能不理想的程度。
- 损失函数量化了这种误差,将其转换为一个数值,这个数值越大,表示误差越大,也就是模型的表现越差。
- “损失”的直观意义:
- 想象一个商业场景,假设我们有一个销售预测模型,预测错误会导致库存过多或过少,这种情况会带来经济上的损失。损失函数量化了这种经济损失。
- 在分类问题中,错误分类可能带来错误决策的风险,这也是一种损失。
常见的损失函数
不同类型的任务有不同的损失函数。以下是一些常见的损失函数:
- 均方误差(Mean Squared Error, MSE):
- 主要用于回归问题。
- 定义为预测值和实际值之差的平方和的平均值。
- 数学形式: MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE=n1∑i=1n(yi−y^i)2
- 其中, y i y_i yi 是实际值, y ^ i \hat{y}_i y^i 是预测值, n n n 是样本数量。
- 交叉熵损失(Cross-Entropy Loss):
- 主要用于分类问题。
- 定义为实际分布与预测分布之间的交叉熵。
- 数学形式: Loss = − ∑ i = 1 n y i log ( y ^ i ) \text{Loss} = -\sum_{i=1}^{n} y_i \log(\hat{y}_i) Loss=−∑i=1nyilog(y^i)
- 其中, y i y_i yi 是实际标签的分布, y ^ i \hat{y}_i y^i 是预测概率分布。
- 绝对误差(Mean Absolute Error, MAE):
- 主要用于回归问题。
- 定义为预测值和实际值之差的绝对值的平均值。
- 数学形式: MAE = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ \text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| MAE=n1∑i=1n∣yi−y^i∣
- 0-1 损失(0-1 Loss):
- 主要用于分类问题。
- 定义为预测错误时损失为1,预测正确时损失为0。
- 数学形式: Loss = ∑ i = 1 n 1 ( y i ≠ y ^ i ) \text{Loss} = \sum_{i=1}^{n} \mathbf{1}(y_i \neq \hat{y}_i) Loss=∑i=1n1(yi=y^i)
- 其中, 1 \mathbf{1} 1 是指示函数,当 y i ≠ y ^ i y_i \neq \hat{y}_i yi=y^i 时为1,否则为0。
损失函数的作用
- 指导模型优化:
- 损失函数的值提供了模型性能的直接反馈。通过最小化损失函数,可以提高模型的预测精度。
- 在训练过程中,优化算法(如梯度下降)利用损失函数的梯度来调整模型参数,减少误差。
- 衡量模型性能:
- 损失函数提供了一个量化标准,可以用来比较不同模型或同一模型在不同参数下的表现。
- 在模型评估阶段,损失函数的值可以帮助选择最佳模型。
- 在代码 loss = criterion(logits, labels) 中,criterion 是指损失函数(也称为准则函数或标准函数),它用于计算模型预测(logits)与实际标签(labels)之间的差异,并返回一个标量值,该值用于指导模型的优化过程。
详细解释
- criterion:criterion 通常是一个由 PyTorch 提供的损失函数实例,例如 torch.nn.CrossEntropyLoss 或 torch.nn.MSELoss。它是一个可调用对象,接收模型的输出(logits)和实际标签(labels)作为输入,返回一个标量损失值。
中文翻译
- criterion 通常翻译为:损失函数,准则函数,标准函数
示例
假设我们在做一个分类任务,使用交叉熵损失函数:
import torch
import torch.nn as nn
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 模拟模型输出 (logits) 和实际标签 (labels)
logits = torch.tensor([[2.0, 0.5, 0.3], [0.1, 1.2, 0.8]]) # 形状为 (batch_size, num_classes)
labels = torch.tensor([0, 1]) # 形状为 (batch_size,)
# 计算损失
loss = criterion(logits, labels)
print(loss)
在这个例子中:
- logits 是模型的输出,表示每个类别的未归一化分数。
- labels 是实际的类别标签。
- criterion 是交叉熵损失函数。
- loss 是计算得到的损失值,用于指导模型参数的更新。