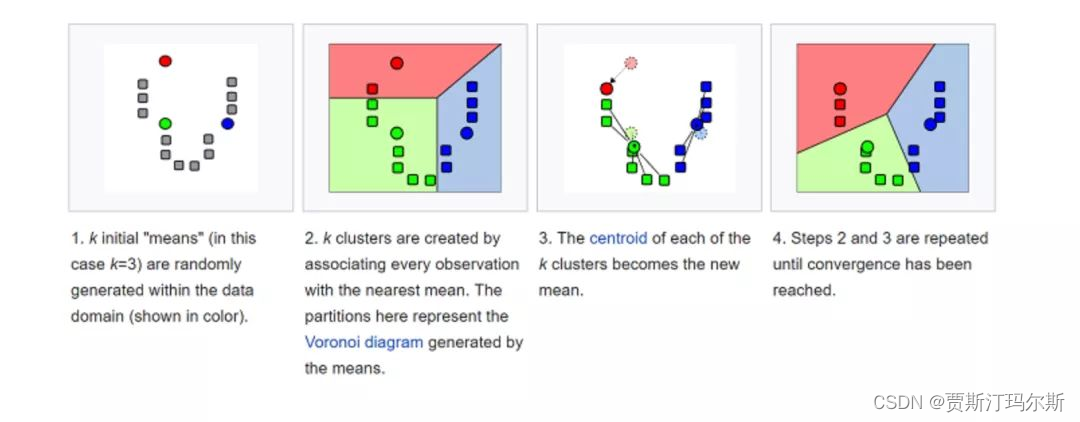
K-means 是一种经典的无监督学习算法,用于将数据集中的样本点自动分组到不同的类别,也称为簇。这个算法的基本思想是迭代地优化聚类中心和分配样本点的过程,直到达到某个终止条件,比如聚类中心不再显著变化或者达到预设的最大迭代次数。以下是K-means算法的详细步骤:
初始化:
选择 K 个初始聚类中心,通常随机从数据集中选取 K 个样本点作为初始的质心(centroid)。
K 的选择需要根据问题的具体需求和数据分布来确定,没有固定的最优值。
分配样本:
计算每个样本点到所有聚类中心的距离,通常使用欧氏距离。
每个样本点被分配到与其最近的聚类中心所属的簇。
更新质心:
对于每个簇,重新计算其所有成员的平均值,这个平均值就是新的聚类中心。
如果簇中没有样本点,可能需要采取特殊策略,如随机选择一个新的样本点作为质心,或者保留旧的质心。
重复迭代:
重复步骤2和3,直到满足停止条件,比如聚类中心的位置变化小于某个阈值,或者达到预设的最大迭代次数。
结果评估:
结束迭代后,每个样本点都属于一个簇,形成 K 个聚类。
可以使用内部评价指标(如轮廓系数、Calinski-Harabasz指数或Davies-Bouldin指数)来评估聚类的质量,但请注意,这些指标并不总是能够反映实际应用中的最佳结果。
K-means算法的优点包括简单快速、易于理解以及对大规模数据集的处理效率。然而,它也有一些缺点,如对初始质心敏感(可能导致局部最优解)、对异常值敏感以及无法处理非凸形状的簇。此外,K-means假设簇的大小和形状大致相同,这在实际问题中可能不成立。
在Python中,可以使用sklearn.cluster.KMeans库来实现K-means聚类。以下是一个简单的代码示例:
from sklearn.cluster import KMeans
import numpy as np
# 假设我们有以下数据
data = np.array([[1, 2], [1, 4], [1, 0],
[4, 2], [4, 4], [4, 0]])
# 初始化KMeans模型,设置K为3
kmeans = KMeans(n_clusters=3)
# 训练模型
kmeans.fit(data)
# 获取聚类结果
labels = kmeans.labels_
centroids = kmeans.cluster_centers_
# 输出结果
print("Labels: ", labels)
print("Centroids: ", centroids)
K-means聚类的深入探讨与改进
算法局限性与挑战
尽管K-means因其简单高效而广受欢迎,但它存在几个显著的局限性和挑战,这些因素限制了其在某些应用场景中的表现:
初始化敏感性:K-means的最终结果对初始聚类中心的选择非常敏感。不同的初始化可能导致完全不同的聚类结果,特别是在数据分布复杂的情况下,容易陷入局部最优解。
球形簇假设:K-means假设簇是凸的、大小相近且形状相似的球形,这在实际数据中往往不成立。对于非球形或大小差异大的簇,算法表现不佳。
处理噪声和离群点:K-means对噪声和离群点敏感,这些点可能会被误归类,从而影响整个簇的中心位置。
需要预先设定K值:K的选择对聚类效果至关重要,但事先确定最优的K值是一个难题,通常需要借助肘部法则、轮廓系数等方法进行估计。
不适合处理高维数据:随着维度增加,数据点之间的距离计算变得困难(所谓的“维度灾难”),导致K-means性能下降。
改进方法与变种
为了克服上述局限,研究者们提出了多种K-means的改进方法和变体,以下是一些代表性的改进:
K-means++:这是一种改进的初始化策略,旨在减少对初始质心选择的敏感性。K-means++通过概率选择的方式,确保初始质心之间尽可能分散,从而提高算法的稳定性和聚类质量。
Mini-Batch K-means:为了加速K-means在大规模数据集上的运算,Mini-Batch K-means每次迭代只使用数据的一个子集来更新质心,虽然牺牲了一定的精确度,但显著提高了效率。
二分K-means:不是一次性划分所有数据,而是先将所有数据看作一个簇,然后逐步分裂最不纯的簇,直至达到预定的K值。这种方法适用于发现任意形状的簇,但可能需要更多计算资源。
Kernel K-means:通过引入核函数,将原始数据映射到高维特征空间,使得原本线性不可分的数据在高维空间变得线性可分,从而能够处理非线性分布的数据。
Density-Based Clustering:如DBSCAN和OPTICS等,这些算法不依赖于预先设定的簇数,而是基于密度的概念来发现任意形状的簇,特别适合含有噪声和复杂结构的数据集。
谱聚类:通过图论中的谱理论对数据进行降维和聚类,能够有效处理非凸簇和高维数据,但计算复杂度较高。
实践中的应用与注意事项
在实际应用K-means或其他聚类算法时,需要注意以下几点:
数据预处理:标准化或归一化数据,去除噪声和处理缺失值,可以显著影响聚类效果。
特征选择:合理选择或构建特征,减少维度,可以提高算法效率和聚类质量。
评估与验证:选择合适的评估指标(如轮廓系数、Calinski-Harabasz指数)来衡量聚类效果,并进行交叉验证以确保结果的稳健性。
迭代次数与收敛条件:合理设置最大迭代次数,并监控算法收敛情况,避免不必要的计算。
可视化分析:对于低维数据,可视化聚类结果可以帮助直观理解数据分布和聚类效果,对于高维数据,则可能需要降维技术(如PCA、t-SNE)辅助分析。
综上所述,K-means聚类作为一种基础且强大的无监督学习方法,通过不断地优化和改进,仍然在数据分析、模式识别、市场细分、社交网络分析等多个领域发挥着重要作用。然而,针对具体问题选择合适的聚类算法和参数设置,以及对数据的适当预处理,都是确保聚类效果的关键。随着人工智能和机器学习技术的不断进步,未来将有更多的创新方法涌现,以解决现有聚类算法面临的挑战。
![[机器学习]<span style='color:red;'>K</span>-<span style='color:red;'>means</span>——<span style='color:red;'>聚</span><span style='color:red;'>类</span>算法](https://img-blog.csdnimg.cn/direct/2079fdc508124a808fb7216649db5432.png)


















![[经验] 榴莲保鲜时间有多久 #经验分享#其他](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fwww.hao123rr.com%2Fzb_users%2Fcache%2Fly_autoimg%2F%25E6%25A6%25B4%25E8%258E%25B2%25E4%25BF%259D%25E9%25B2%259C%25E6%2597%25B6%25E9%2597%25B4%25E6%259C%2589%25E5%25A4%259A%25E4%25B9%2585.jpg&pos_id=2J5Ztr4E)





![[图解]企业应用架构模式2024新译本讲解12-领域模型5](https://img-blog.csdnimg.cn/direct/16f5a61e5a094747bb6ee1d0c368e7f1.png)