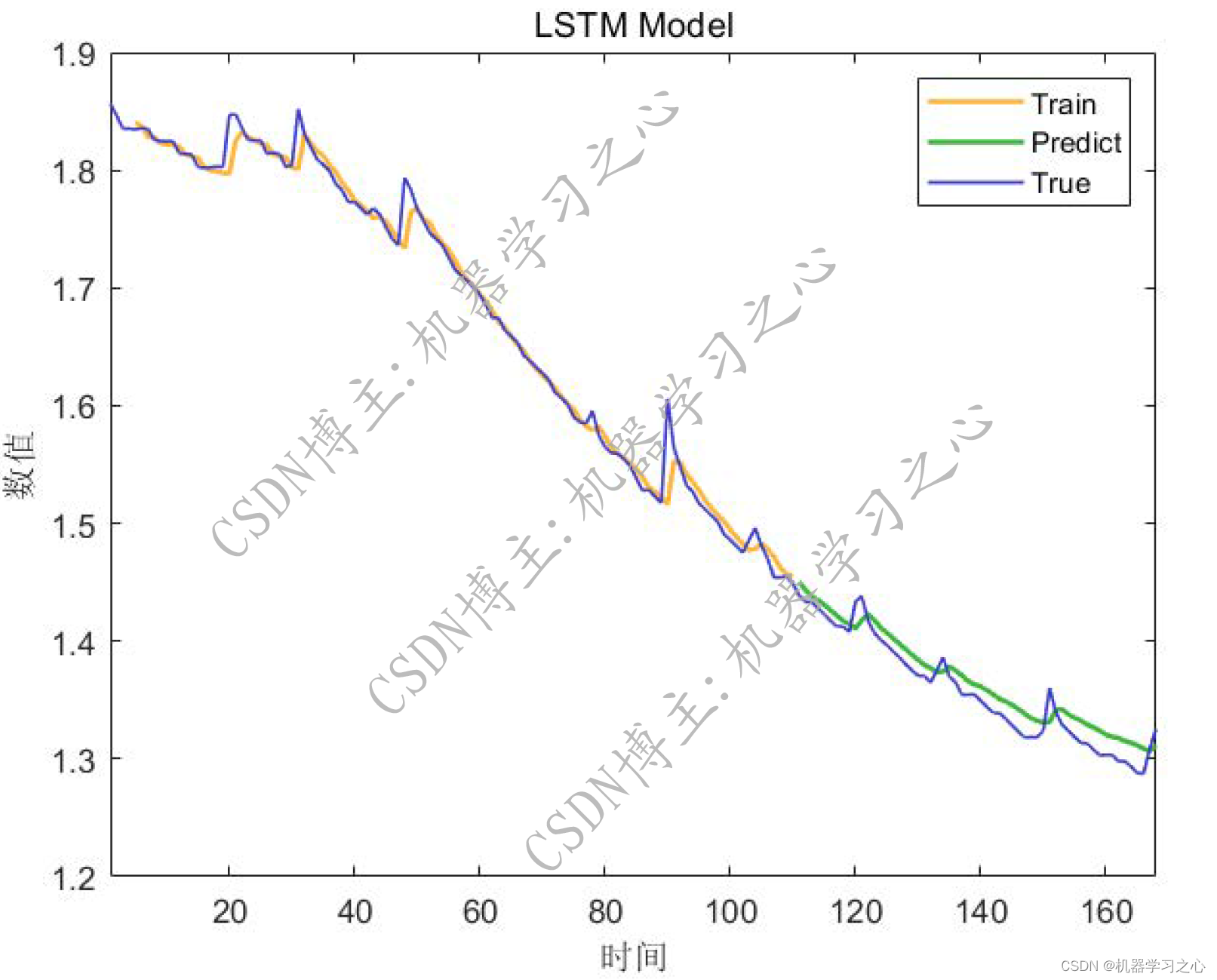
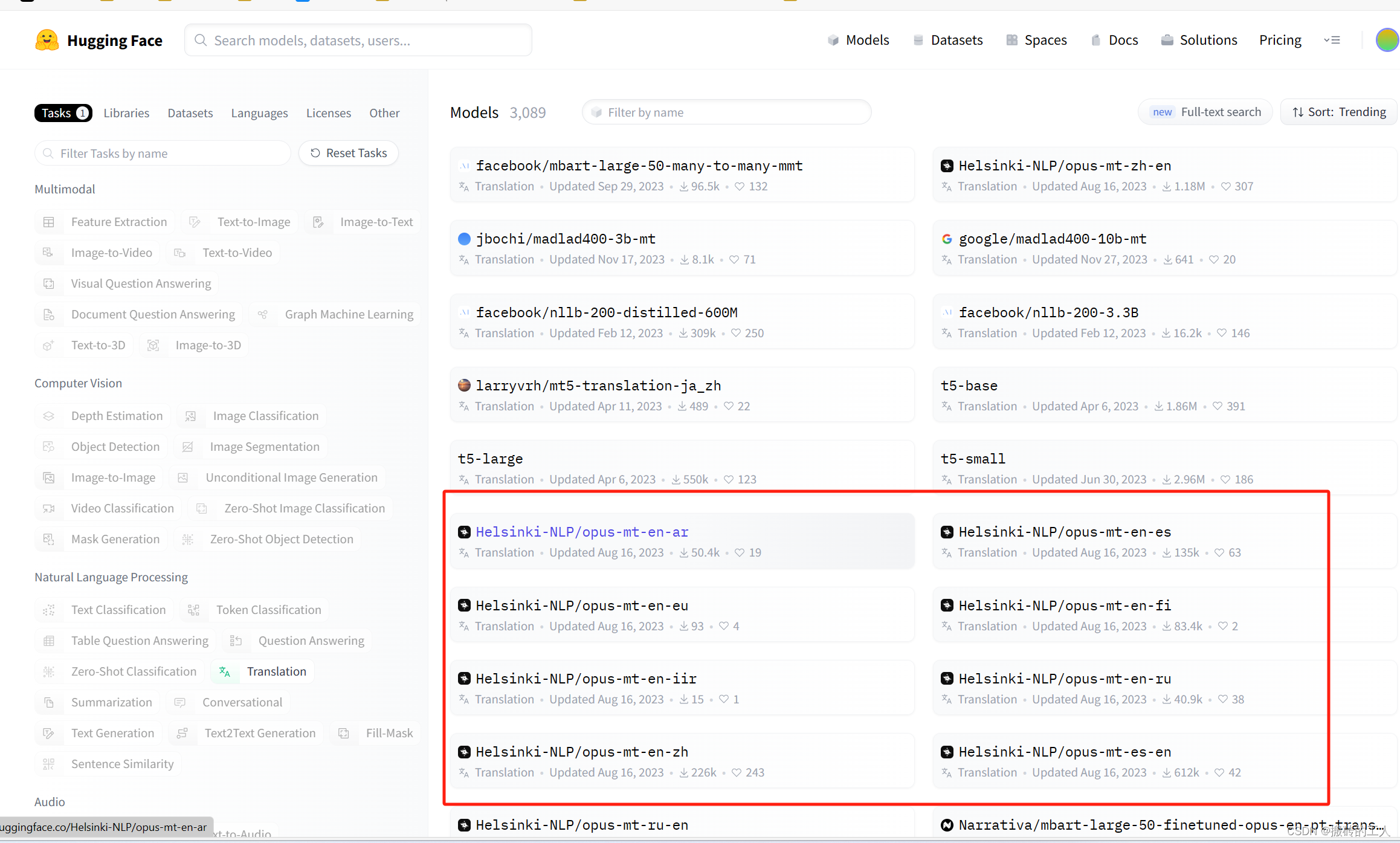
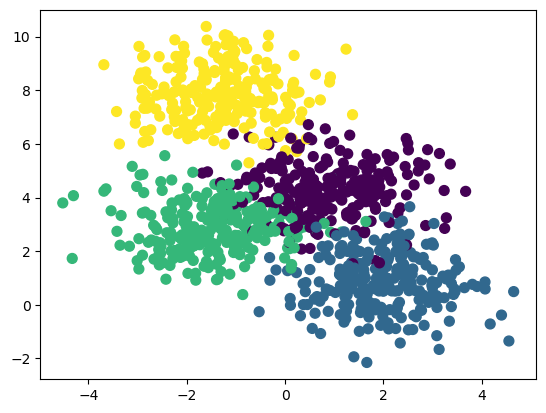
K-均值聚类(K-means clustering)是一种常用的无监督学习算法,用于将样本数据划分成K个不同的类别。K-均值聚类试图找到K个簇,使得簇内的样本点相似度最高,而簇间的样本点相似度最低。
算法步骤如下:
- 随机选择K个初始中心点作为簇的质心。
- 将每个样本点分配给离其最近的质心,形成K个簇。
- 计算每个簇的质心,作为新的质心。
- 重复步骤2和步骤3,直到质心不再发生变化或达到最大迭代次数。
K-均值聚类算法的优点如下:
- 简单易实现,计算复杂度较低。
- 适用于大规模数据集,可以处理大量数据。
- 可以灵活地选择簇的数量K。
K-均值聚类算法的缺点如下:
- 对初始质心的选择敏感,可能会陷入局部最优解。
- 需要提前确定簇的数量K,但在实际应用中往往无法准确确定。
- 对离群点(异常值)敏感,可能会影响簇的划分结果。
总结起来,K-均值聚类算法是一种简单而有效的聚类算法,适用于大规模数据集,但对初始质心的选择和簇的数量的确定十分重要,且对异常点敏感。在应用时需要根据具体问题进行调参和处理。
























![【算法每日一练]-动态规划(保姆级教程 篇14) #三倍经验 #散步 #异或和 #抽奖概率](https://img-blog.csdnimg.cn/direct/5c176a1b429b49f081dbdfed2f496f74.png)