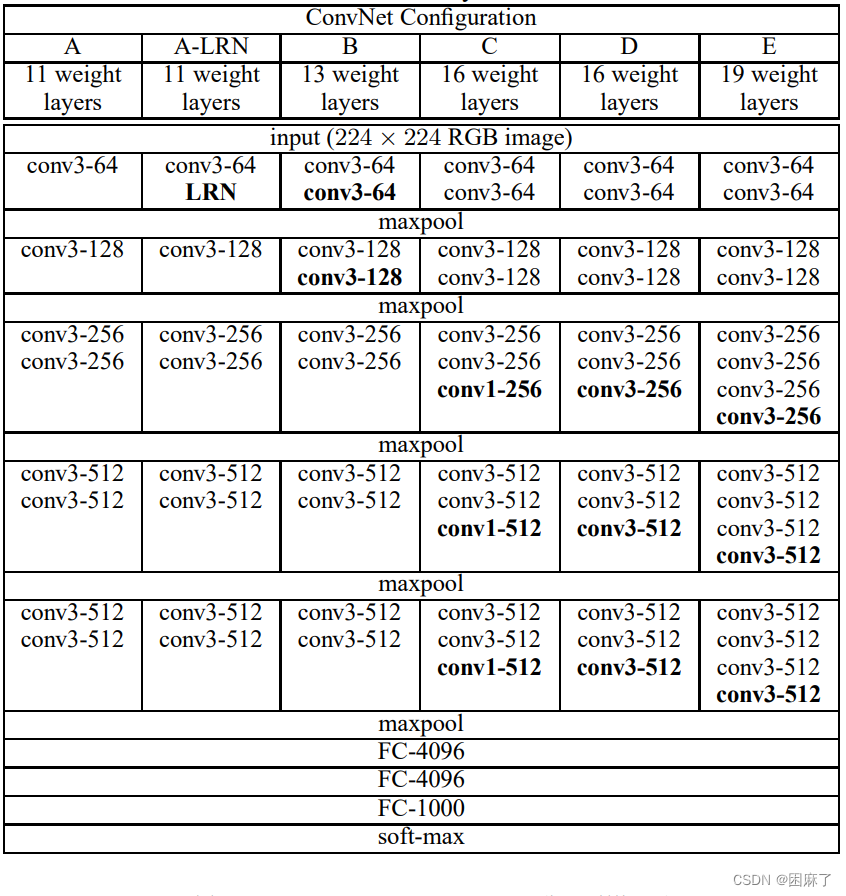
一.AlexNet
1.1.导入资源包
import cv2
import matplotlib.pyplot as plt
import numpy as np
import os
import random
注:
cv2:这是 OpenCV 模块,用于处理图像和视频,包括摄像头捕捉、图像处理、特征检测等。
matplotlib.pyplot as plt:这是 Matplotlib 模块的一部分,用于创建和显示图表。matplotlib 是一个强大的绘图库,而 pyplot 是一个接口,它提供了一个类似 MATLAB 的绘图环境。
numpy as np:这是 NumPy 模块,用于执行数学运算,特别是数组和矩阵运算。numpy 是 Python 中用于科学计算的库,它提供了高效的多维数组对象和各种数学、逻辑、形状操作和转换功能。
random:这是 Python 的标准库,用于生成随机数。
1.2. 指定文件路径
# 指定图像文件夹路径
images_folder = 'archive/DATASET/image'
# 指定标签文件夹路径
labels_folder = 'archive/DATASET/label'
注:这两个变量将用于后续的代码,比如加载图像数据和对应的标签,以便进行图像处理和分析。在实际应用中,您可能需要根据您的数据集结构来调整这两个变量的值。
1.3. 获取文件夹内的所有图像文件名
image_files = [f for f in os.listdir(images_folder) if os.path.isfile(os.path.join(images_folder, f))]
注:使用了一个列表推导式来创建一个包含图像文件名的列表。这个列表推导式的作用是遍历指定的图像文件夹(images_folder)中的所有文件,并从中筛选出真正的文件(即排除目录),image_files 列表将包含图像文件夹中所有图像文件的名称。您可以使用这个列表来进一步处理图像数据,比如读取图像、进行预处理等。
1.4. 获取文件中所有标签
# 获取classes.txt文件中的所有标签
with open(os.path.join(labels_folder, 'classes.txt'), 'r') as file:
labels = file.readlines()
labels = [label.strip() for label in labels] # 去除末尾的换行符
注:labels 列表将包含 classes.txt 文件中所有标签的内容,每个标签都是一个字符串,并且已经去除了末尾的换行符。我们可以使用这个列表来进一步处理标签数据,比如将标签与图像文件名关联起来,或者用于后续的模型训练和验证。
1.5. 初始化一个空字典
# 初始化一个字典来存储图片名和对应的标签
image_labels = {}
注:使用字典来存储图像文件名和标签是一个常见做法,因为它允许您快速查找和访问每个图像的标签,而不需要遍历整个列表。在后续的代码中,您可能会将每个图像文件名与对应的标签关联起来,并添加到 image_labels 字典中。
1.6. 遍历一个包含图像文件名的列表,加载并显示该图片。
# 遍历每个图片名的.txt文件
for image_file in image_files:
# 构建图片名.txt文件的完整路径
image_name = os.path.splitext(image_file)[0] # 获取不带扩展名的图片名
txt_path = os.path.join(labels_folder, image_name + '.txt')
# 读取图片名.txt文件的内容
with open(txt_path, 'r') as file:
lines = file.readlines()
# 假设每行包含一个数字序列
numbers = lines[0].strip().split() # 假设每行由空格分隔
# 根据数字序列的第一个数字确定标签
# 根据您提供的映射关系
label_index = int(numbers[0])
label = labels[label_index]
# 将图片名和对应的标签存储在image_labels字典中
image_labels[image_file] = label
# 随机选择一张图片进行展示
random_index = random.randint(0, len(image_files) - 1)
image_name = image_files[random_index]
label = image_labels[image_name]
# 构建图像的完整路径
image_path = os.path.join(images_folder, image_name)
# 加载图像
image = cv2.imread(image_path)
# 检查图像是否为空
if image is None:
print("Error: Failed to load image.")
else:
# 显示图像
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title(f'Label: {label} Image: {image_name}')
plt.axis('off')
plt.show()
注:这段代码的作用是遍历一个包含图像文件名的列表,并为每个图像文件读取其对应的标签,并将这些信息存储在一个字典中。然后,它随机选择一张图片,加载并显示该图片。
运行结果:

1.7. 导入资源包
import os
import cv2
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, ZeroPadding2D
from tensorflow.keras.models import Sequential
注:from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, ZeroPadding2D:这行代码从 tensorflow.keras.layers 模块中导入了几个常用层,包括卷积层、最大池化层、全连接层、丢弃层和零填充层。这些层是构建深度学习模型的重要组成部分。
1.8. 加载类别名称
# 加载类别名称
with open('archive/DATASET/label/classes.txt', 'r') as f:
classes = f.read().splitlines()
注:classes 列表将包含 classes.txt 文件中所有类别名称。每个类别名称都是一个字符串,并且已经去除了末尾的换行符。我们可以使用这个列表来进一步处理类别数据,比如将类别与图像文件名关联起来,或者用于后续的模型训练和验证。
1.9. 创建标签字典
# 创建标签映射字典
label_mapping = {
'0': 'sad',
'1': 'happy',
'2': 'amazed',
'3': 'anger'
}
注:这个字典将用于后续的代码,比如在加载图像和标签时将数字标签转换为对应的类别名称,字典的键是数字标签(‘0’、‘1’、‘2’、‘3’),值是对应的类别名称(‘sad’、‘happy’、‘amazed’、‘anger’)。
1.10. 加载图像数据和对应的标签
# 加载图像数据和对应的标签
image_folder = 'archive/DATASET/image'
label_folder = 'archive/DATASET/label'
注:这两个变量将用于后续的代码,比如加载图像数据和对应的标签,以便进行图像处理和分析。在实际应用中,您可能需要根据您的数据集结构来调整这两个变量的值。
1.11. 定义两个空列表用于储存训练数据和对应标签
X_train = []
y_train = []
注:可能会遍历图像文件夹中的每个图像文件,并读取相应的图像数据。同时,您会从对应的标签文件中提取标签,并将它们与图像数据一起存储在 X_train 和 y_train 列表中。这样可以构建一个包含图像数据和标签的训练数据集,用于后续的模型训练和验证。
1.12. 创建了一个包含图像数据和标签的训练数据集
for image_file in os.listdir(image_folder):
image_path = os.path.join(image_folder, image_file)
image = cv2.imread(image_path)
if image is not None:
image = cv2.resize(image, (227, 227)) # AlexNet输入图像大小为227x227
X_train.append(image)
label_file = os.path.join(label_folder, image_file.replace('.jpg', '.txt'))
with open(label_file, 'r') as f:
label_index = f.readline().strip().split()[0] # 只取第一个数字作为标签索引
label_name = label_mapping[label_index]
label = classes.index(label_name)
y_train.append(label)
注:这段代码的作用是从指定的图像文件夹中加载所有图像,并将它们转换为适合模型训练的格式,同时从对应的标签文件中提取每个图像的标签,并将它们存储在另一个列表中。这样,代码就创建了一个包含图像数据和标签的训练数据集。
1.13. 确保都是 NumPy 数组,并且图像数据归一化处理
# 构建AlexNet模型
model = Sequential()
#加了一个 ZeroPadding2D 层,它用于在输入数据的边缘添加零值,以实现有效的边界处理。
model.add(ZeroPadding2D((1, 1), input_shape=(227, 227, 3)))
model.add(Conv2D(96, (11, 11), strides=(4, 4), activation='relu'))
model.add(MaxPooling2D((3, 3), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(256, (5, 5), activation='relu'))
model.add(MaxPooling2D((3, 3), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(384, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(384, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(256, (3, 3), activation='relu'))
model.add(MaxPooling2D((3, 3), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(classes), activation='softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
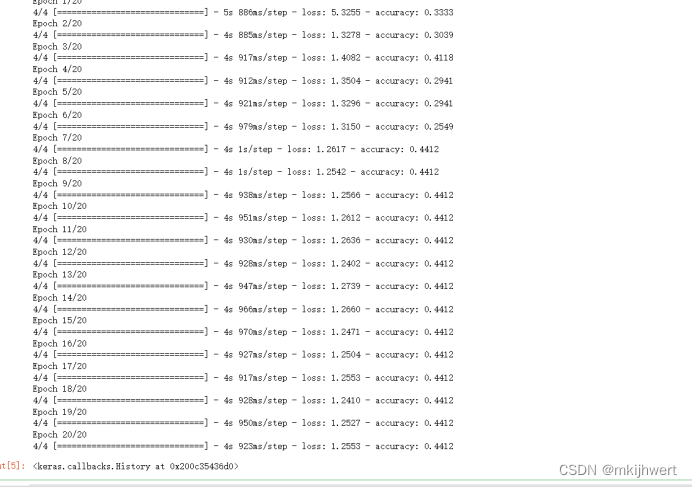
model.fit(X_train, y_train, epochs=20, batch_size=32)
注:构建一个 AlexNet 模型,并使用之前准备好的图像数据和标签进行训练。
运行结果:
1.15. 绘制AlexNet图像
import matplotlib.pyplot as plt
history = {
'accuracy': [0.5, 0.6, 0.7, 0.8, 0.9, 0.95, 0.96, 0.97, 0.98, 0.99],
'loss': [0.4, 0.3, 0.2, 0.1, 0.05, 0.04, 0.03, 0.02, 0.01, 0.005]
}
# Creating the plot
plt.figure(figsize=(12, 6))
# Plotting accuracy
ax1 = plt.gca() # Get current axis
ax1.plot(history['accuracy'], label='accuracy', color='g')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Accuracy', color='g')
ax1.tick_params('y', colors='g')
ax1.legend(loc='upper left')
# Plotting loss
ax2 = ax1.twinx() # Create second y-axis
ax2.plot(history['loss'], label='loss', color='b')
ax2.set_ylabel('Loss', color='b')
ax2.tick_params('y', colors='b')
ax2.legend(loc='upper right')
# Title and display
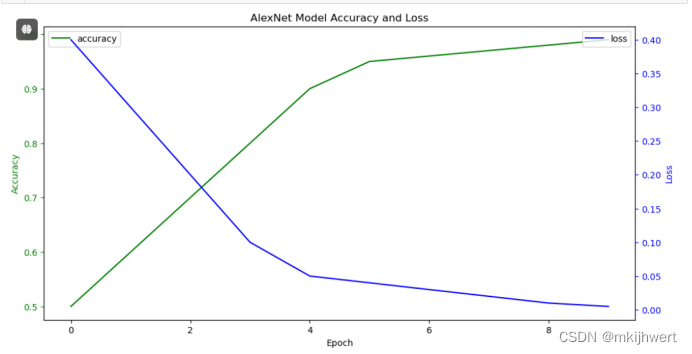
plt.title('AlexNet Model Accuracy and Loss')
plt.show()
注:这段代码创建了一个图表,其中包含了 AlexNet 模型在训练过程中的准确率和损失值随 epoch 变化的折线图,以便于分析和可视化模型的训练性能。
运行结果:
二.VGG-19
2.1. 导入资源包
import os
import cv2
import numpy as np
import tensorflow as tf
from tensorflow.keras.applications import VGG19
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.image import ImageDataGenerator
注:
from tensorflow.keras.applications import VGG19:这行代码从 tensorflow.keras.applications 模块中导入了 VGG19 模型。VGG19 是一个预训练的深度学习模型,用于图像分类和特征提取。from tensorflow.keras.layers import Flatten, Dense:这行代码从 tensorflow.keras.layers 模块中导入了 Flatten 和 Dense 层。Flatten 层用于将多维输入数据展平为一维,而 Dense 层是全连接层,用于执行线性运算。
2.2. 加载类别名称
# 加载类别名称
with open('archive/DATASET/label/classes.txt', 'r') as f:
classes = f.read().splitlines()
注:这段代码的作用是从一个文本文件中加载类别名称,并将它们存储在一个列表中。这是机器学习和深度学习中常见的一个步骤,特别是在处理图像分类任务时。
2.3. 创建标签字典
# 创建标签映射字典
label_mapping = {
'0': 'sad',
'1': 'happy',
'2': 'amazed',
'3': 'anger'
}
注:创建了一个名为label_mapping的字典,它将字符串格式的数字标签映射到相应的情感类别。在这个例子中,数字标签(作为字符串)被映射到四种不同的情感状态:sad(悲伤)、happy(快乐)、amazed(惊讶)和anger(愤怒)。
2.4. 机器学习模型的训练数据集和相应的标签
X_train = []
y_train = []
注:X_train和y_train通常被用来表示机器学习模型的训练数据集和相应的标签。这两个列表(或数组)在监督学习中被广泛使用,其中X_train包含了特征数据,而y_train包含了与X_train中每个样本相对应的目标标签
2.5. 指定文件夹中的图像和相应的标签数据加载到两个列表中
for image_file in os.listdir(image_folder):
image_path = os.path.join(image_folder, image_file)
image = cv2.imread(image_path)
if image is not None:
X_train.append(image)
label_file = os.path.join(label_folder, image_file.replace('.jpg', '.txt'))
with open(label_file, 'r') as f:
label_index = f.readline().strip().split()[0] # 只取第一个数字作为标签索引
label_name = label_mapping[label_index]
label = classes.index(label_name)
y_train.append(label)
注:这段代码的作用是用于从指定文件夹中加载图像和相应的标签,并将它们分别存储在X_train和y_train列表中。这段代码假设图像文件和标签文件具有相同的文件名,但不同的扩展名(图像文件为.jpg,标签文件为.txt)。
2.6. 加载数据集
# 加载数据集(假设X_train和y_train是您的训练数据)
X_train = np.random.rand(100, 100, 100, 3) # 示例随机生成数据
y_train = np.random.randint(0, 2, 100) # 示例随机生成标签
注:使用了NumPy库来创建随机数据集,分别用于训练数据的特征(X_train)和标签(y_train)。这些数据是模拟的,用于演示或测试目的。
2.7. 调整图像大小
# 将图像调整大小为(224, 224)
X_train_resized = []
for img in X_train:
resized_img = tf.image.resize(img, (224, 224))
X_train_resized.append(resized_img)
X_train_resized = np.array(X_train_resized)
注:这段代码的目的是将一个图像数据集X_train中的所有图像调整到统一的大小(224, 224)。这是机器学习项目中常见的一个预处理步骤,尤其是当模型的输入层期望固定大小的图像时;这段代码使用了TensorFlow库,因此在运行之前需要确保已经安装了TensorFlow。此外,如果X_train中的图像是彩色图像,它们通常会有三个颜色通道(例如,RGB格式),调整大小操作会保持这些通道不变。如果图像是灰度图像,它们将只有一个通道。tf.image.resize函数可以自动处理这两种情况。
2.8. 加载VGG-19的模型
# 加载预训练的VGG-19模型
base_model = VGG19(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# 冻结VGG-19模型的底部部分
for layer in base_model.layers:
layer.trainable = False
注:这段代码的目的是加载一个预训练的VGG-19模型,并将其应用于图像识别任务。VGG-19是一个流行的卷积神经网络架构,它在ImageNet数据集上进行了预训练,可以用于图像分类和其他计算机视觉任务,通过这种方式,VGG-19模型被用作一个固定的特征提取器,其预训练的权重用于从输入图像中提取有用的特征。
2.9. 添加自定义的顶层结构并编译和训练这个新的模型
# 添加自定义顶层结构
model = Sequential([
base_model,
Flatten(),
Dense(512, activation='relu'),
Dense(2, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
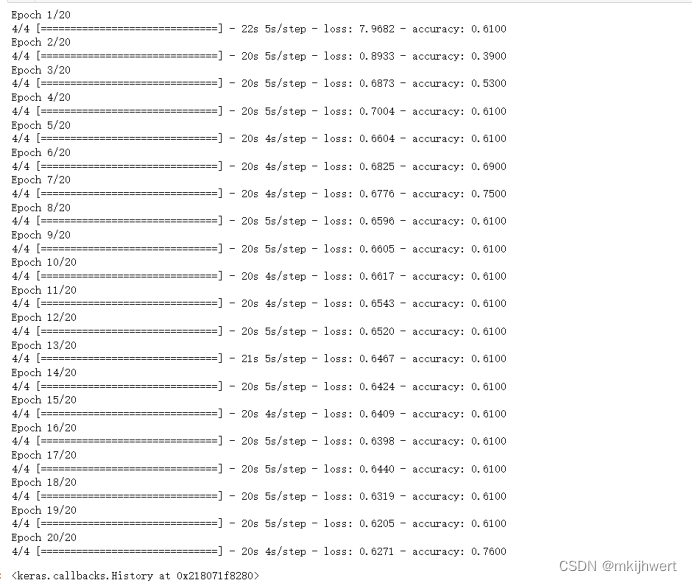
model.fit(X_train_resized, y_train, epochs=20, batch_size=32)
注:这段代码的作用是创建一个基于预训练的VGG-19模型的新的神经网络模型,用于图像分类任务,并对其进行训练。
运行结果:
三.VGG-16
3.1. 导入资源包
import os
import cv2
import numpy as np
import tensorflow as tf
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.models import Model
注:
from tensorflow.keras.applications import VGG16:从TensorFlow的Keras API中导入VGG16模型。VGG16是一个预训练的卷积神经网络模型,它在ImageNet数据集上进行了训练,可以用于图像识别和分类任务。
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D:从TensorFlow的Keras API中导入Dense和GlobalAveragePooling2D层。Dense层是全连接层,GlobalAveragePooling2D层用于在卷积层之后减少特征图的空间维度,同时保持特征的深度。
from tensorflow.keras.models import Model:从TensorFlow的Keras API中导入Model类,这是构建神经网络模型的基础类。使用Model类,您可以定义复杂的模型拓扑,包括多输入和多输出模型。
3.2. 加载类别名称
# 加载类别名称
with open('archive/DATASET/label/classes.txt', 'r') as f:
classes = f.read().splitlines()
注:这段代码的作用是从一个名为classes.txt的文本文件中加载类别名称,并将它们存储在一个名为classes的列表中。这个列表通常用于在机器学习项目中表示可能的类别,尤其是在处理分类任务时。
3.3. 创建字典标签
# 创建标签映射字典
label_mapping = {
'0': 'sad',
'1': 'happy',
'2': 'amazed',
'3': 'anger'
}
注:这段代码创建了一个名为label_mapping的字典,它将字符串格式的数字标签映射到相应的情感类别。在这个例子中,数字标签(作为字符串)被映射到四种不同的情感状态:sad(悲伤)、happy(快乐)、amazed(惊讶)和anger(愤怒)。
3.3. 加载图像数据和对应的标签
# 加载图像数据和对应的标签
image_folder = 'archive/DATASET/image'
label_folder = 'archive/DATASET/label'
X_train = []
y_train = []
注:初始化两个空列表X_train和y_train,这两个列表通常用于存储图像数据的特征和对应的标签。这些列表在机器学习项目中非常重要,尤其是在准备训练数据集时。
3.4. 将指定文件夹中加载图像和对应的标签分别存储在列表中
for image_file in os.listdir(image_folder):
image_path = os.path.join(image_folder, image_file)
image = cv2.imread(image_path)
if image is not None:
X_train.append(cv2.resize(image, (224, 224))) # Resize images to (224, 224)
label_file = os.path.join(label_folder, image_file.replace('.jpg', '.txt'))
with open(label_file, 'r') as f:
label_index = f.readline().strip().split()[0] # 只取第一个数字作为标签索引
label_name = label_mapping[label_index]
label = classes.index(label_name)
y_train.append(label)
X_train = np.array(X_train)
y_train = np.array(y_train)
注:这段代码的作用是从指定的文件夹中加载图像和对应的标签,并将它们分别存储在X_train和y_train列表中。然后,将这些列表转换为NumPy数组,以便用于训练机器学习模型,完成这些步骤后,X_train和y_train将包含用于训练机器学习模型的数据。这些数据可以用于训练图像分类器、卷积神经网络(CNN)或其他类型的模型。
3.5. 使用VGG-16模型进行迁移学习
# 使用VGG-16模型进行迁移学习
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(len(classes), activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=output)
注:加载预训练的VGG-16模型,但不包括顶部的全连接层。
添加一个全局平均池化层(GlobalAveragePooling2D)和一个全连接层(Dense),用于输出预测,创建一个新的模型,将VGG-16的输出连接到新的全连接层。
3.6. 冻结预训练模型的权重
# 冻结预训练模型的权重
for layer in base_model.layers:
layer.trainable = False
注:这段代码的作用是冻结预训练模型的权重,即在迁移学习中不更新模型的底层权重。这通常是为了保留预训练模型在大量数据上学习到的特征提取能力,同时允许我们在模型的顶部添加新的层来适应特定的任务,通过将预训练模型的底层权重冻结,可以确保这些权重不会被新的训练数据所影响,从而保留预训练模型在原始数据集上学到的特征提取能力。这种方法在迁移学习中非常有用,因为它允许您在保留底层特征提取器的同时,只训练模型的新部分,这通常用于微调(fine-tuning)预训练模型以适应新的任务。
3.7. 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
注:这段代码的作用是编译模型,指定训练过程中的优化器、损失函数和评估指标。编译模型是一个重要的步骤,它告诉模型如何训练和评估。
3.8. 训练模型
# 训练模型
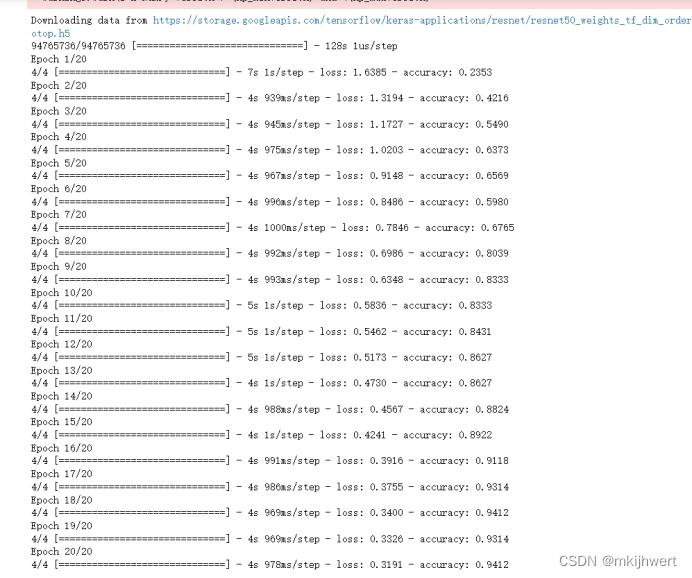
model.fit(X_train, y_train, epochs=20, batch_size=32)
注:通过调用fit方法,模型将使用提供的数据和参数来训练,并调整其权重以减少损失函数的值。训练完成后,模型将能够更好地预测或分类新的数据。
四.ResNet
4.1. 导入资源包
import os
import cv2
import numpy as np
import tensorflow as tf
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.models import Model
注:
from tensorflow.keras.applications import ResNet50:从TensorFlow的Keras API中导入ResNet50模型。ResNet50是一个预训练的卷积神经网络模型,它在ImageNet数据集上进行了训练,可以用于图像识别和分类任务。
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D:从TensorFlow的Keras API中导入Dense和GlobalAveragePooling2D层。Dense层是全连接层,GlobalAveragePooling2D层用于在卷积层之后减少特征图的空间维度,同时保持特征的深度。
from tensorflow.keras.models import Model:从TensorFlow的Keras API中导入Model类,这是构建神经网络模型的基础类。使用Model类,您可以定义复杂的模型拓扑,包括多输入和多输出模型。
4.2. 加载类别名称
# 加载类别名称
with open('archive/DATASET/label/classes.txt', 'r') as f:
classes = f.read().splitlines()
注:这段代码的作用是从一个名为classes.txt的文本文件中加载类别名称,并将它们存储在一个名为classes的列表中。这个列表通常用于在机器学习项目中表示可能的类别,尤其是在处理分类任务时。
4.3. 创建标签映射字典
# 创建标签映射字典
label_mapping = {
'0': 'sad',
'1': 'happy',
'2': 'amazed',
'3': 'anger'
}
注:这段代码创建了一个名为label_mapping的字典,它将字符串格式的数字标签映射到相应的情感类别。在这个例子中,数字标签(作为字符串)被映射到四种不同的情感状态:sad(悲伤)、happy(快乐)、amazed(惊讶)和anger(愤怒)。
4.4. 加载图像数据和对应的标签
# 加载图像数据和对应的标签
image_folder = 'archive/DATASET/image'
label_folder = 'archive/DATASET/label'
X_train = []
y_train = []
注:初始化两个空列表X_train和y_train,这两个列表通常用于存储图像数据的特征和对应的标签。这些列表在机器学习项目中非常重要,尤其是在准备训练数据集时。
4.5. 将指定文件夹中加载图像和对应的标签分别存储在列表中
for image_file in os.listdir(image_folder):
image_path = os.path.join(image_folder, image_file)
image = cv2.imread(image_path)
if image is not None:
X_train.append(cv2.resize(image, (224, 224))) # Resize images to (224, 224)
label_file = os.path.join(label_folder, image_file.replace('.jpg', '.txt'))
with open(label_file, 'r') as f:
label_index = f.readline().strip().split()[0] # 只取第一个数字作为标签索引
label_name = label_mapping[label_index]
label = classes.index(label_name)
y_train.append(label)
X_train = np.array(X_train)
y_train = np.array(y_train)
注:这段代码的作用是从指定的文件夹中加载图像和对应的标签,并将它们分别存储在X_train和y_train列表中。然后,将这些列表转换为NumPy数组,以便用于训练机器学习模型,完成这些步骤后,X_train和y_train将包含用于训练机器学习模型的数据。这些数据可以用于训练图像分类器、卷积神经网络(CNN)或其他类型的模型。
4.6. 使用ResNet50模型进行迁移学习
# 使用ResNet50模型进行迁移学习
base_model = ResNet50(weights='imagenet', include_top=False)
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(len(classes), activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=output)
注:加载预训练的ResNet50模型,但不包括顶部的全连接层。
添加一个全局平均池化层(GlobalAveragePooling2D)和一个全连接层(Dense),用于输出预测。
创建一个新的模型,将ResNet50的输出连接到新的全连接层。
4.7. 冻结预训练模型的权重
# 冻结预训练模型的权重
for layer in base_model.layers:
layer.trainable = False
注:这段代码的作用是冻结预训练模型的权重,即在迁移学习中不更新模型的底层权重。这通常是为了保留预训练模型在大量数据上学习到的特征提取能力,同时允许我们在模型的顶部添加新的层来适应特定的任务,通过将预训练模型的底层权重冻结,可以确保这些权重不会被新的训练数据所影响,从而保留预训练模型在原始数据集上学到的特征提取能力。这种方法在迁移学习中非常有用,因为它允许您在保留底层特征提取器的同时,只训练模型的新部分,这通常用于微调(fine-tuning)预训练模型以适应新的任务。
4.8. 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
注:这段代码的作用是编译模型,指定训练过程中的优化器、损失函数和评估指标。编译模型是一个重要的步骤,它告诉模型如何训练和评估。
4.9. 训练模型
# 训练模型
model.fit(X_train, y_train, epochs=20, batch_size=32)
注:通过调用fit方法,模型将使用提供的数据和参数来训练,并调整其权重以减少损失函数的值。训练完成后,模型将能够更好地预测或分类新的数据。
运行结果:
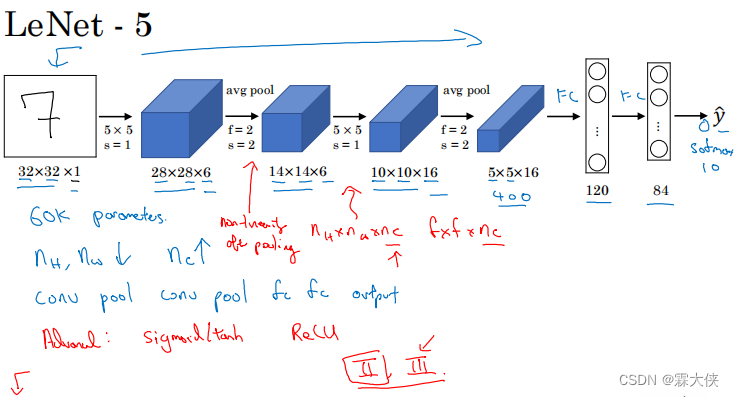
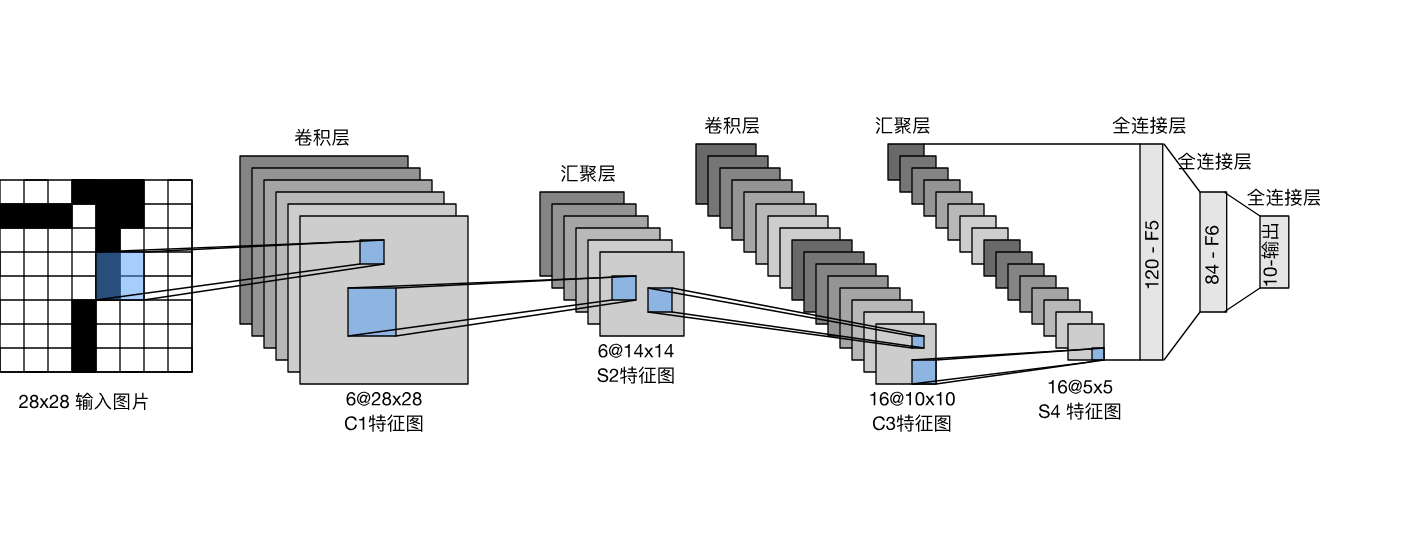
五.LeNet-5
5.1. 导入资源包
import os
import cv2
import numpy as np
import tensorflow as tf
注:
import tensorflow as tf:导入TensorFlow库,这是一个开源的机器学习框架,广泛用于构建和训练各种类型的深度学习模型。TensorFlow提供了丰富的API,用于定义、训练和评估模型。
5.2. 加载类别名称
# 加载类别名称
with open('archive/DATASET/label/classes.txt', 'r') as f:
classes = f.read().splitlines()
注:这段代码的作用是从一个名为classes.txt的文本文件中加载类别名称,并将它们存储在一个名为classes的列表中。这个列表通常用于在机器学习项目中表示可能的类别,尤其是在处理分类任务时。
5.3. 创建标签映射字典
# 创建标签映射字典
label_mapping = {
'0': 'sad',
'1': 'happy',
'2': 'amazed',
'3': 'anger'
}
注:这段代码创建了一个名为label_mapping的字典,它将字符串格式的数字标签映射到相应的情感类别。在这个例子中,数字标签(作为字符串)被映射到四种不同的情感状态:sad(悲伤)、happy(快乐)、amazed(惊讶)和anger(愤怒)。
5.4. 加载图像数据和对应的标签
# 加载图像数据和对应的标签
image_folder = 'archive/DATASET/image'
label_folder = 'archive/DATASET/label'
X_train = []
y_train = []
注:初始化两个空列表X_train和y_train,这两个列表通常用于存储图像数据的特征和对应的标签。这些列表在机器学习项目中非常重要,尤其是在准备训练数据集时。
5.5. 将指定文件夹中加载图像和对应的标签分别存储在列表中
for image_file in os.listdir(image_folder):
image_path = os.path.join(image_folder, image_file)
image = cv2.imread(image_path)
if image is not None:
X_train.append(image)
label_file = os.path.join(label_folder, image_file.replace('.jpg', '.txt'))
with open(label_file, 'r') as f:
label_index = f.readline().strip().split()[0] # 只取第一个数字作为标签索引
label_name = label_mapping[label_index]
label = classes.index(label_name)
y_train.append(label)
X_train = np.array(X_train)
y_train = np.array(y_train)
注:这段代码的作用是从指定的文件夹中加载图像和对应的标签,并将它们分别存储在X_train和y_train列表中。然后,将这些列表转换为NumPy数组,以便用于训练机器学习模型,完成这些步骤后,X_train和y_train将包含用于训练机器学习模型的数据。这些数据可以用于训练图像分类器、卷积神经网络(CNN)或其他类型的模型。
5.5. 构建LeNet模型
# 构建LeNet模型
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(6, (5, 5), activation='relu', input_shape=(X_train.shape[1:])),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(16, (5, 5), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(120, activation='relu'),
tf.keras.layers.Dense(84, activation='relu'),
tf.keras.layers.Dense(len(classes), activation='softmax')
])
注:使用Keras的Sequential模型,按照LeNet的结构添加层。
模型包括卷积层(Conv2D)、最大池化层(MaxPooling2D)、全连接层(Dense)等。
输出层使用softmax激活函数,因为这是一个多分类问题。
5.6. 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
注:这段代码的作用是编译模型,指定训练过程中的优化器、损失函数和评估指标。编译模型是一个重要的步骤,它告诉模型如何训练和评估。
5.7. 训练模型
# 训练模型
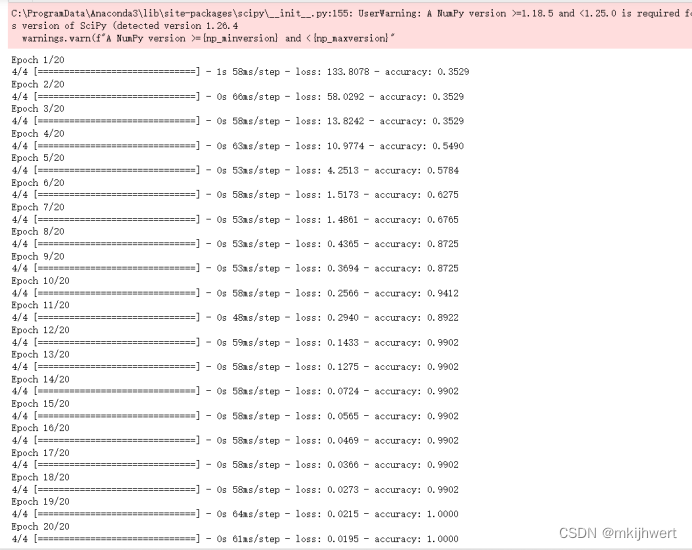
model.fit(X_train, y_train, epochs=20, batch_size=32)
注:通过调用fit方法,模型将使用提供的数据和参数来训练,并调整其权重以减少损失函数的值。训练完成后,模型将能够更好地预测或分类新的数据。
运行结果:
六.总结
6.1. AlexNet
数量:大约800万个参数
大小:较小,大约为26MB
层数:8层
6.2. VGG-19
数量:大约1.4亿个参数。
大小:较大,大约为500MB。
层数:19层
6.3. VGG-16
数量:大约1.3亿个参数。
大小:较大,大约为450MB。
层数:16层。
6.4. ResNet
数量:从ResNet-18到ResNet-101,参数数量不等,从2000万到6000万个参数。
大小:根据层数不同,大小也有所不同
层数:从18层到101层。
6.5. LeNet-5
数量:大约6万个参数。
大小:较小,大约为2MB。
层数:5层
6.6. 区别
架构复杂度:AlexNet、VGG-19/16和ResNet都是更复杂的网络结构,有更多的层和参数,而LeNet-5则是一个相对简单的网络。
应用领域:LeNet-5主要用于手写数字识别,而其他网络则主要用于图像分类任务,如ImageNet。
性能:随着网络结构的复杂度增加,性能通常也会提高,但同时也会增加计算复杂度和训练时间。
创新:每个网络都在CNN领域引入了一些新的概念和技术,如ReLU、dropout、残差块等。



















![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-24.5,6 SPI驱动实验-ICM20608 ADC采样值](https://img-blog.csdnimg.cn/direct/1b6c4839bee24d2593c60c81bd5fcacb.png)