学习参考:
①如有冒犯、请联系侵删。
②已写完的笔记文章会不定时一直修订修改(删、改、增),以达到集多方教程的精华于一文的目的。
③非常推荐上面(学习参考)的前两个教程,在网上是开源免费的,写的很棒,不管是开始学还是复习巩固都很不错的。
深度学习回顾,专栏内容来源多个书籍笔记、在线笔记、以及自己的感想、想法,佛系更新。争取内容全面而不失重点。完结时间到了也会一直更新下去,已写完的笔记文章会不定时一直修订修改(删、改、增),以达到集多方教程的精华于一文的目的。所有文章涉及的教程都会写在开头、一起学习一起进步。
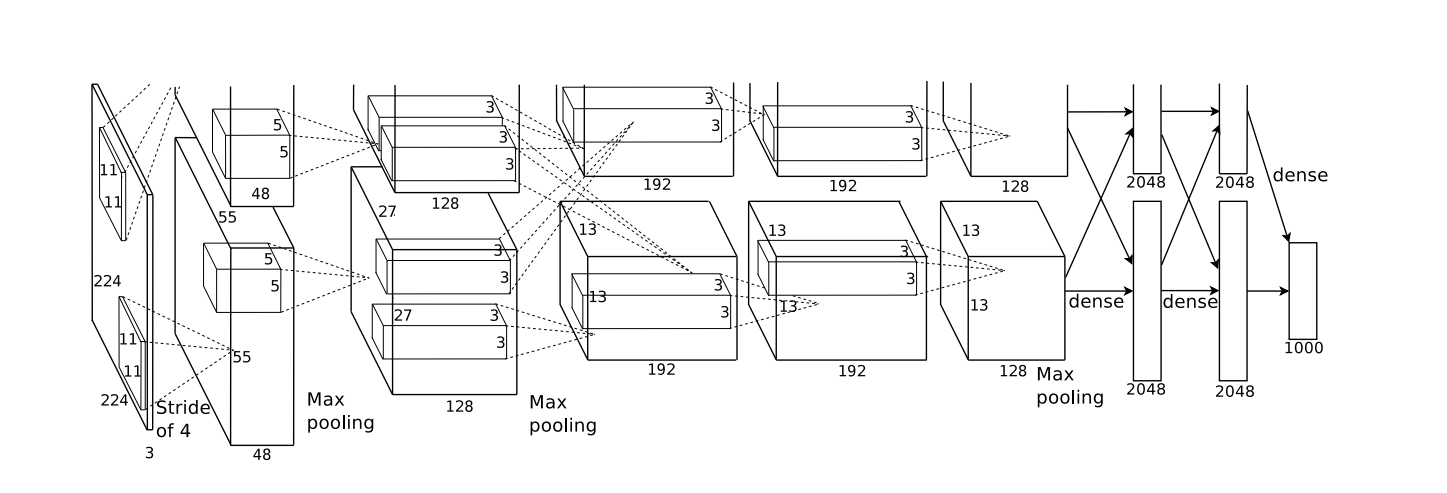
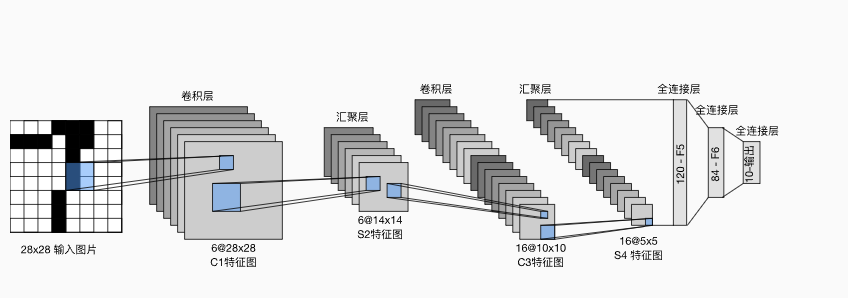
1.LeNet模型结构
LeNet(LeNet-5)由两个部分组成:
- 卷积编码器:由两个卷积层组成;
- 全连接层密集块:由三个全连接层组成。
结构如下:
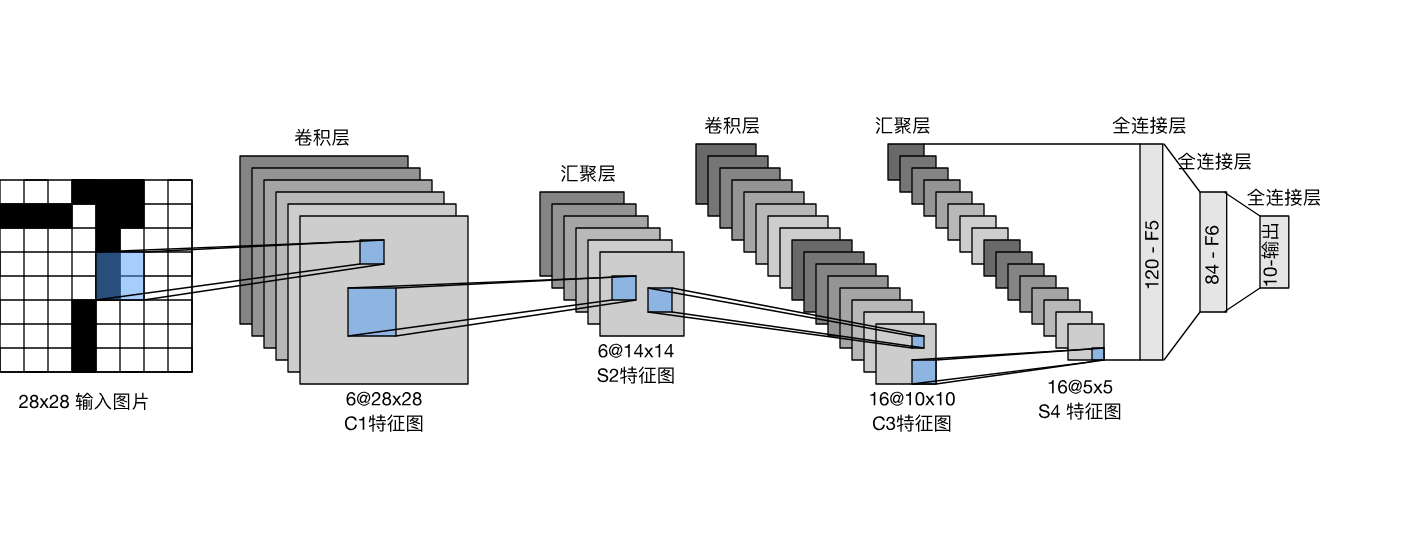
每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层。请注意,虽然ReLU和最大汇聚层更有效,但它们在20世纪90年代还没有出现(所以该模型就没有)。
每个卷积层使用 5×5 卷积核和一个sigmoid激活函数。些层将输入映射到多个二维特征输出,通常同时增加通道的数量。第一卷积层有6个输出通道,而第二个卷积层有16个输出通道。每个 2×2池操作(步幅2)通过空间下采样将维数减少4倍。卷积的输出形状由批量大小、通道数、高度、宽度决定。

为了将卷积块的输出传递给稠密块(全连接那部分),必须在小批量中展平每个样本。换言之,将这个四维输入转换成全连接层所期望的二维输入。这里的二维表示的第一个维度索引小批量中的样本,第二个维度给出每个样本的平面向量表示。LeNet的稠密块有三个全连接层,分别有120、84和10个输出。因为在执行分类任务,所以输出层的10维对应于最后输出结果的数量。
请注意,在整个卷积块中,与上一层相比,每一层特征的高度和宽度都减小了。 第一个卷积层使用2个像素的填充,来补偿 5×5
卷积核导致的特征减少。 相反,第二个卷积层没有填充,因此高度和宽度都减少了4个像素。 随着层叠的上升,通道的数量从输入时的1个,增加到第一个卷积层之后的6个,再到第二个卷积层之后的16个。 同时,每个汇聚层的高度和宽度都减半。最后,每个全连接层减少维数,最终输出一个维数与结果分类数相匹配的输出。
模型结构实现如下:(对原始模型做了一点小改动,去掉了最后一层的高斯激活。除此之外,这个网络与最初的LeNet-5一致。)
import tensorflow as tf
from d2l import tensorflow as d2l
def net():
return tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=6, kernel_size=5, activation='sigmoid',
padding='same'),
tf.keras.layers.AvgPool2D(pool_size=2, strides=2),
tf.keras.layers.Conv2D(filters=16, kernel_size=5,
activation='sigmoid'),
tf.keras.layers.AvgPool2D(pool_size=2, strides=2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(120, activation='sigmoid'),
tf.keras.layers.Dense(84, activation='sigmoid'),
tf.keras.layers.Dense(10)])
将一个大小为 28×28 的单通道(黑白)图像通过LeNet。通过在每一层打印输出的形状,可以检查模型,以确保其操作与期望的结构 一致。
X = tf.random.uniform((1, 28, 28, 1))
for layer in net().layers:
X = layer(X)
print(layer.__class__.__name__, 'output shape: \t', X.shape)
如下,输出维度和层次变化与结构一致,说明模型没有搭建出错。
Conv2D output shape: (1, 28, 28, 6)
AveragePooling2D output shape: (1, 14, 14, 6)
Conv2D output shape: (1, 10, 10, 16)
AveragePooling2D output shape: (1, 5, 5, 16)
Flatten output shape: (1, 400)
Dense output shape: (1, 120)
Dense output shape: (1, 84)
Dense output shape: (1, 10)
2.LeNet5在Fashion-MNIST数据集上的表现
虽然卷积神经网络的参数较少,但与深度的多层感知机相比,它们的计算成本仍然很高,因为每个参数都参与更多的乘法。
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
通过使用GPU,可以用它加快训练。为了使用GPU,还需要一点小改动,在进行正向和反向传播之前,需要将每一小批量数据移动到我们指定的设备(例如GPU)上。将实现多层神经网络,因此将主要使用高级API。 以下训练函数假定从高级API创建的模型作为输入,并进行相应的优化。
- 使用在 Xavier随机初始化模型参数。
- 使用交叉熵损失函数和小批量随机梯度下降。
class TrainCallback(tf.keras.callbacks.Callback): #@save
"""一个以可视化的训练进展的回调"""
def __init__(self, net, train_iter, test_iter, num_epochs, device_name):
self.timer = d2l.Timer()
self.animator = d2l.Animator(
xlabel='epoch', xlim=[1, num_epochs], legend=[
'train loss', 'train acc', 'test acc'])
self.net = net
self.train_iter = train_iter
self.test_iter = test_iter
self.num_epochs = num_epochs
self.device_name = device_name
def on_epoch_begin(self, epoch, logs=None):
self.timer.start()
def on_epoch_end(self, epoch, logs):
self.timer.stop()
test_acc = self.net.evaluate(
self.test_iter, verbose=0, return_dict=True)['accuracy']
metrics = (logs['loss'], logs['accuracy'], test_acc)
self.animator.add(epoch + 1, metrics)
if epoch == self.num_epochs - 1:
batch_size = next(iter(self.train_iter))[0].shape[0]
num_examples = batch_size * tf.data.experimental.cardinality(
self.train_iter).numpy()
print(f'loss {metrics[0]:.3f}, train acc {metrics[1]:.3f}, '
f'test acc {metrics[2]:.3f}')
print(f'{num_examples / self.timer.avg():.1f} examples/sec on '
f'{str(self.device_name)}')
#@save
def train_ch6(net_fn, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
device_name = device._device_name
strategy = tf.distribute.OneDeviceStrategy(device_name)
with strategy.scope():
optimizer = tf.keras.optimizers.SGD(learning_rate=lr)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
net = net_fn()
net.compile(optimizer=optimizer, loss=loss, metrics=['accuracy'])
callback = TrainCallback(net, train_iter, test_iter, num_epochs,
device_name)
net.fit(train_iter, epochs=num_epochs, verbose=0, callbacks=[callback])
return net
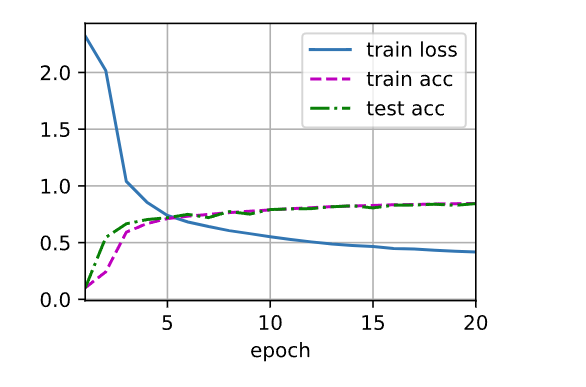
训练和评估LeNet-5模型:
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
3. TensorFlow实现LeNet
基于 MNIST 手写数字图片数据集训练 LeNet-5 网络,并测试其最终准确度。
在 LeNet-5 的基础上进行了少许调整,使得它更容易在现代深度学习框架上实 现。首先我们将输入𝒀形状由32 × 32调整为28 × 28,然后将 2 个下采样层实现为最大池化层(降低特征图的高、宽,后续会介绍),最后利用全连接层替换掉 Gaussian connections层。
import tensorflow as tf
# 获取GPU列表
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# 设置GPU为增长式占用
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
# 打印异常
print(e)
# LeNet-5模型
from tensorflow.keras import Sequential,layers,losses
network = Sequential([ # 网络容器
layers.Conv2D(6,kernel_size=3,strides=1), # 第一个卷积层, 6 个 3x3 卷积核
layers.MaxPooling2D(pool_size=2,strides=2), # 高宽各减半的池化层
layers.ReLU(), # 激活函数
layers.Conv2D(16,kernel_size=3,strides=1), # 第二个卷积层, 16 个 3x3 卷积核
layers.MaxPooling2D(pool_size=2,strides=2), # 高宽各减半的池化层
layers.ReLU(), # 激活函数
layers.Flatten(), # 打平层,方便全连接层处理
layers.Dense(120, activation='relu'), # 全连接层,120 个节点
layers.Dense(84, activation='relu'), # 全连接层,84 节点
layers.Dense(10) # 全连接层,10 个节点
])
# build 一次网络模型,给输入 X 的形状,其中 4 为随意给的 batchsize
network.build(input_shape=(4, 28, 28, 1))
# 统计网络信息
network.summary()
from tensorflow.keras import datasets
# 准备数据
(x_train, y_train), (x_test, y_test) = datasets.mnist.load_data() # 加载 MNIST 数据集
x_train = 2*tf.convert_to_tensor(x_train, dtype=tf.float32)/255.-1 # 转换为浮点张量,并缩放到-1~1
y_train = tf.convert_to_tensor(y_train, dtype=tf.int32) # 转换为整形张量
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # 构建数据集对象
train_dataset = train_dataset.batch(64).repeat(10) # 设置批量训练的batch为32,要将训练集重复训练10遍
x_test = 2*tf.convert_to_tensor(x_test, dtype=tf.float32)/255.-1 # 转换为浮点张量,并缩放到-1~1
y_test = tf.convert_to_tensor(y_test, dtype=tf.int32) # 转换为整形张量
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # 构建数据集对象
test_dataset = test_dataset.batch(64) #
# 导入误差计算,优化器模块
from tensorflow.keras import losses, optimizers,metrics
# 创建损失函数的类,在实际计算时直接调用类实例即可
criteon = losses.CategoricalCrossentropy(from_logits=True)
acc_meter = metrics.Accuracy() # 创建准确度测量器
optimizer = optimizers.SGD(lr=0.01) # 声明采用批量随机梯度下降方法,学习率=0.01
for step, (x, y) in enumerate(train_dataset): # 一次输入batch组数据进行训练
# 构建梯度记录环境
with tf.GradientTape() as tape:
x = tf.expand_dims(x,axis=3)#添加一个维度[64,28,28,1]
# 前向计算,获得 10 类别的概率分布,[b, 784] => [b, 10]
out = network(x)
# 真实标签 one-hot 编码,[b] => [b, 10]
y_onehot = tf.one_hot(y, depth=10)
# 计算交叉熵损失函数,标量
loss = criteon(y_onehot, out)
# 自动计算梯度
grads = tape.gradient(loss, network.trainable_variables)
# 自动更新参数
optimizer.apply_gradients(zip(grads, network.trainable_variables))
acc_meter.update_state(tf.argmax(out, axis=1), y) # 比较预测值与标签,并计算精确度
if step % 200 == 0: # 每200个step,打印一次结果
print('Step', step, ': Loss is: ', float(loss), ' Accuracy: ', acc_meter.result().numpy())
acc_meter.reset_states() # 每一个step后准确度清零
"""
测试集评估
"""
# 记录预测正确的数量,总样本数量
correct, total = 0,0
for step, (x, y) in enumerate(test_dataset): # 遍历所有测试集样本
# 插入通道维度,=>[b,28,28,1]
x = tf.expand_dims(x,axis=3)
# 前向计算,获得 10 类别的预测分布,[b, 784] => [b, 10]
out = network(x)
# # 真实的流程时先经过 softmax,再 argmax
# # 但是由于 softmax 不改变元素的大小相对关系,故省去
pred = tf.argmax(out, axis=-1)
y = tf.cast(y, tf.int64)
# # 统计预测正确数量
correct += float(tf.reduce_sum(tf.cast(tf.equal(pred, y),tf.float32)))
# # 统计预测样本总数
total += x.shape[0]
# 计算准确率
print('test acc:', correct/total)
在数据集上面循环训练 30 个 Epoch 后,网络的训练准确度达到了 98.1%,测试准确度 也达到了 97.7%。对于非常简单的手写数字图片识别任务,古老的 LeNet-5 网络已经可以 取得很好的效果,但是稍复杂一点的任务,比如彩色动物图片识别,LeNet-5 性能就会急 剧下降。