基于RNN和Transformer的词级语言建模 代码分析 log_softmax
flyfish
Word-level Language Modeling using RNN and Transformer
word_language_model
PyTorch 提供的 word_language_model 示例展示了如何使用循环神经网络RNN(GRU或LSTM)和 Transformer 模型进行词级语言建模 。默认情况下,训练使用Wikitext-2数据集,generate.py可以使用训练好的模型来生成新文本。
源码地址
https://github.com/pytorch/examples/tree/main/word_language_model
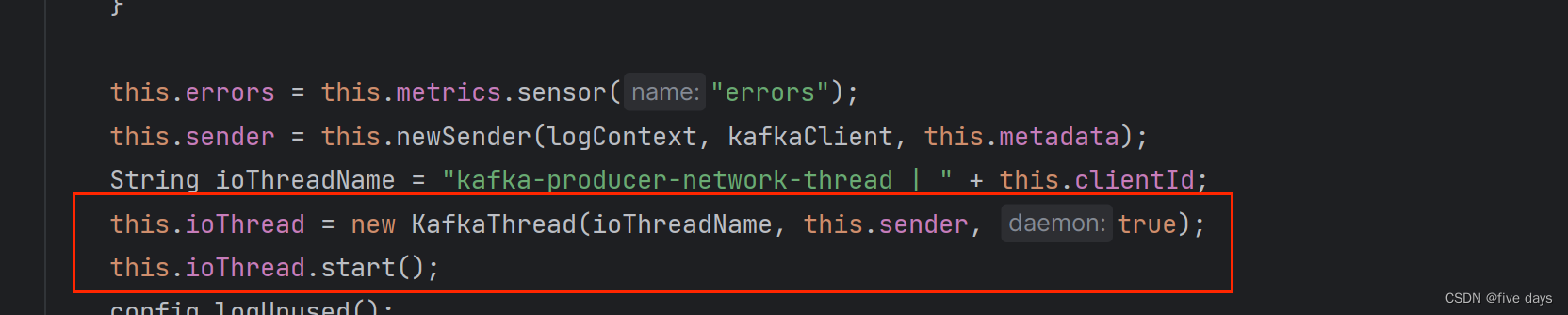
文件:model.py
F.log_softmax(output, dim=-1) 在 TransformerModel 的 forward 方法的最后一行中用于将模型的输出转换为对数概率分布,既提高了数值计算的稳定性,又与常用的损失函数(如NLLLoss)兼容.
数值计算的稳定性,请参考该文章的后半部分
https://flyfish.blog.csdn.net/article/details/106405099
1. 概率与对数概率
概率(Probability): 概率是某个事件发生的可能性,值在 [0, 1] 之间。比如,一个事件发生的概率为 P。
对数概率(Log Probability): 对数概率是将概率值
P 取对数后的结果,通常使用自然对数(ln)。对数概率可以表示为:log§,其中 log 是自然对数函数。
2. 对数概率的性质
范围: 因为概率 P 总是介于 0 和 1 之间,所以对数概率 log§ 总是小于或等于零。
当 P=1 时,log(1)=0。
当 0<P<1 时,log§<0。
当 P 趋近于 0 时,log§ 趋近于负无穷。
单调性: 对数函数是单调递增函数,这意味着如果两个概率
两个概率 P1和 P2, 满足 P1 > P2,则对应的对数概率也满足 log(P1) > log(P2)
3. 为什么使用对数概率
数值稳定性: 直接使用概率值进行计算时,若概率值非常小(接近于零),可能导致数值下溢问题。对概率取对数可以将乘法转化为加法,从而避免这种数值不稳定性。
例如,计算多个独立事件的联合概率
P(A∩B)=P(A)⋅P(B),使用对数概率可以转换为加法:
log(P(A∩B))=log(P(A))+log(P(B))。
简化计算: 在某些模型(如隐马尔可夫模型和深度学习模型)中,使用对数概率可以简化似然函数和损失函数的计算。
与损失函数的兼容性: 在深度学习中,常用的损失函数如负对数似然损失(Negative Log-Likelihood Loss, NLLLoss)需要对数概率作为输入。因此,模型输出对数概率是直接兼容这些损失函数的。
4. 对数概率在深度学习中的应用
在神经网络模型(特别是用于分类任务的模型)中,输出通常是一个概率分布。在语言建模任务中,我们希望输出每个词的概率。在训练过程中,为了计算损失,我们使用对数概率。
语言模型: 给定一个句子,模型输出每个词的对数概率。
损失函数: 使用 NLLLoss 来计算预测词与真实词之间的损失。
以下是一个示例,展示如何计算对数概率并使用负对数似然损失
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义一个简单的模型
class SimpleModel(nn.Module):
def __init__(self, ntoken, ninp):
super(SimpleModel, self).__init__()
self.embedding = nn.Embedding(ntoken, ninp)
self.decoder = nn.Linear(ninp, ntoken)
def forward(self, src):
embedded = self.embedding(src)
output = self.decoder(embedded)
return F.log_softmax(output, dim=-1)
# 超参数
ntoken = 10 # 词汇表大小
ninp = 512 # 嵌入维度
# 创建模型实例
model = SimpleModel(ntoken, ninp)
# 生成假数据
src = torch.randint(0, ntoken, (5, 2)) # 序列长度为5,批次大小为2
# 前向传播
log_probs = model(src)
# 计算损失
criterion = nn.NLLLoss()
target = torch.randint(0, ntoken, (5, 2)) # 生成目标序列
loss = criterion(log_probs.view(-1, ntoken), target.view(-1))
print("Log probabilities shape:", log_probs.shape)
print("Log probabilities:", log_probs)
print("Loss:", loss.item())
加入原始代码
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
r"""Inputs of forward function
Args:
x: the sequence fed to the positional encoder model (required).
Shape:
x: [sequence length, batch size, embed dim]
output: [sequence length, batch size, embed dim]
Examples:
>>> output = pos_encoder(x)
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
class TransformerModel(nn.Transformer):
"""Container module with an encoder, a recurrent or transformer module, and a decoder."""
def __init__(self, ntoken, ninp, nhead, nhid, nlayers, dropout=0.5):
super(TransformerModel, self).__init__(d_model=ninp, nhead=nhead, dim_feedforward=nhid, num_encoder_layers=nlayers)
self.model_type = 'Transformer'
self.src_mask = None
self.pos_encoder = PositionalEncoding(ninp, dropout)
self.input_emb = nn.Embedding(ntoken, ninp)
self.ninp = ninp
self.decoder = nn.Linear(ninp, ntoken)
self.init_weights()
def _generate_square_subsequent_mask(self, sz):
return torch.log(torch.tril(torch.ones(sz,sz)))
def init_weights(self):
initrange = 0.1
nn.init.uniform_(self.input_emb.weight, -initrange, initrange)
nn.init.zeros_(self.decoder.bias)
nn.init.uniform_(self.decoder.weight, -initrange, initrange)
def forward(self, src, has_mask=True):
if has_mask:
device = src.device
if self.src_mask is None or self.src_mask.size(0) != len(src):
mask = self._generate_square_subsequent_mask(len(src)).to(device)
self.src_mask = mask
else:
self.src_mask = None
src = self.input_emb(src) * math.sqrt(self.ninp)
src = self.pos_encoder(src)
output = self.encoder(src, mask=self.src_mask)
output = self.decoder(output)
return F.log_softmax(output, dim=-1)
# Hyperparameters
ntoken = 10 # size of vocabulary
ninp = 512 # embedding dimension
nhead = 8 # number of heads in the multiheadattention models
nhid = 512 # the dimension of the feedforward network model in nn.Transformer
nlayers = 2 # the number of nn.TransformerEncoderLayer in nn.TransformerEncoder
dropout = 0.2 # the dropout value
# Create model
model = TransformerModel(ntoken, ninp, nhead, nhid, nlayers, dropout)
# Example input (sequence length: 5, batch size: 2)
src = torch.randint(0, ntoken, (5, 2))
# Forward pass
output = model(src)
print("Output shape:", output.shape) # Should be (sequence length, batch size, ntoken)
print("Output:", output)
# Visualize the output
output_np = output.detach().numpy() # Convert to numpy for visualization
plt.figure(figsize=(12, 6))
for i in range(output_np.shape[1]): # Iterate over batch elements
plt.subplot(1, output_np.shape[1], i+1)
plt.imshow(output_np[:, i, :], aspect='auto', cmap='viridis')
plt.colorbar()
plt.title(f"Batch {i+1}")
plt.xlabel("Token Index")
plt.ylabel("Sequence Position")
plt.show()
在 TransformerModel 的 forward 方法中,return F.log_softmax(output, dim=-1) 的作用是将模型的最终输出转换为对数概率分布。为了更好地理解其意义和用途,我们需要详细解释以下几个方面:
1. output 的来源
在 forward 方法中,output 是经过嵌入层(embedding layer)、位置编码(positional encoding)、编码器(encoder)、和解码器(decoder)处理后的张量。假设输入 src 的形状为 (sequence_length, batch_size),则:
经过嵌入层后,形状为 (sequence_length, batch_size, ninp)。
经过位置编码后,形状保持不变。
经过编码器后,形状仍然保持不变。
最后经过解码器后,形状为 (sequence_length, batch_size, ntoken),其中 ntoken 是词汇表的大小。
2. F.log_softmax(output, dim=-1) 的作用
F.log_softmax 是 PyTorch 中的一个函数,用于计算张量的对数软最大值。
主要功能:
归一化:将输出转换为概率分布形式。
对数变换:取对数以提高数值稳定性。
为什么在 dim=-1 维度上应用:
dim=-1 表示在最后一个维度上应用 log_softmax,即在 ntoken 维度上。这意味着对于每个时间步和每个批次,模型输出的每个向量都被归一化为一个概率分布,并且这些概率值是通过取对数的方式表示的。
3. 应用
语言建模任务中,将模型输出转换为对数概率分布是非常常见的做法。这是因为:
数值稳定性:计算对数概率可以避免溢出或下溢的问题。
损失函数兼容性:在训练过程中,通常使用负对数似然损失(negative log-likelihood loss,NLLLoss)来优化模型参数。NLLLoss 需要对数概率作为输入,因此在前向传播中计算 log_softmax 是必要的。
4. 示例代码
假设我们有一个训练好的 TransformerModel 实例,并且我们输入一些假数据来运行前向传播。F.log_softmax(output, dim=-1) 的具体效果如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
# Define the TransformerModel and PositionalEncoding classes here (from previous messages)
# Example input (sequence length: 5, batch size: 2)
src = torch.randint(0, ntoken, (5, 2))
# Forward pass
output = model(src)
log_probs = F.log_softmax(output, dim=-1)
# Output shape
print("Output shape:", log_probs.shape) # Should be (sequence length, batch size, ntoken)
# Output values (log probabilities)
print("Log probabilities:", log_probs)
Output shape: torch.Size([5, 2, 10])
Log probabilities: tensor([[[-1.8122, -1.6211, -2.8076, -2.8982, -3.4530, -1.0481, -3.1035,
-3.0695, -6.4251, -3.0296],
[-7.1732, -1.0471, -4.7220, -0.9092, -4.7615, -3.8586, -2.5530,
-2.2406, -4.5940, -4.3775]],
[[-1.8474, -2.3659, -4.0811, -3.3230, -1.9491, -1.2751, -2.2046,
-3.1314, -3.8996, -2.3072],
[-3.8504, -3.6711, -1.3957, -1.1146, -2.9621, -2.0949, -3.4236,
-3.6456, -2.7213, -2.5475]],
[[-3.3242, -3.7939, -3.4796, -4.5979, -1.9281, -1.7997, -3.2005,
-1.9959, -3.0253, -1.0088],
[-4.1581, -0.9709, -4.3932, -0.9737, -5.2762, -2.2979, -3.6968,
-3.6558, -4.9326, -2.9538]],
[[-2.0125, -1.7920, -2.7189, -3.7525, -2.9609, -2.4254, -3.8162,
-2.4056, -4.5775, -1.0567],
[-3.5996, -2.0966, -3.8215, -1.6972, -4.0127, -3.1117, -3.2421,
-2.7508, -2.3296, -0.9629]],
[[-1.7974, -2.0685, -2.4899, -2.8838, -1.9412, -1.7804, -4.3274,
-4.6523, -1.6798, -3.0407],
[-1.8604, -1.2988, -2.9066, -3.4268, -3.1218, -3.0153, -3.0892,
-4.5497, -1.1045, -5.5781]]], grad_fn=<LogSoftmaxBackward0>)



















![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-24.5,6 SPI驱动实验-ICM20608 ADC采样值](https://img-blog.csdnimg.cn/direct/1b6c4839bee24d2593c60c81bd5fcacb.png)