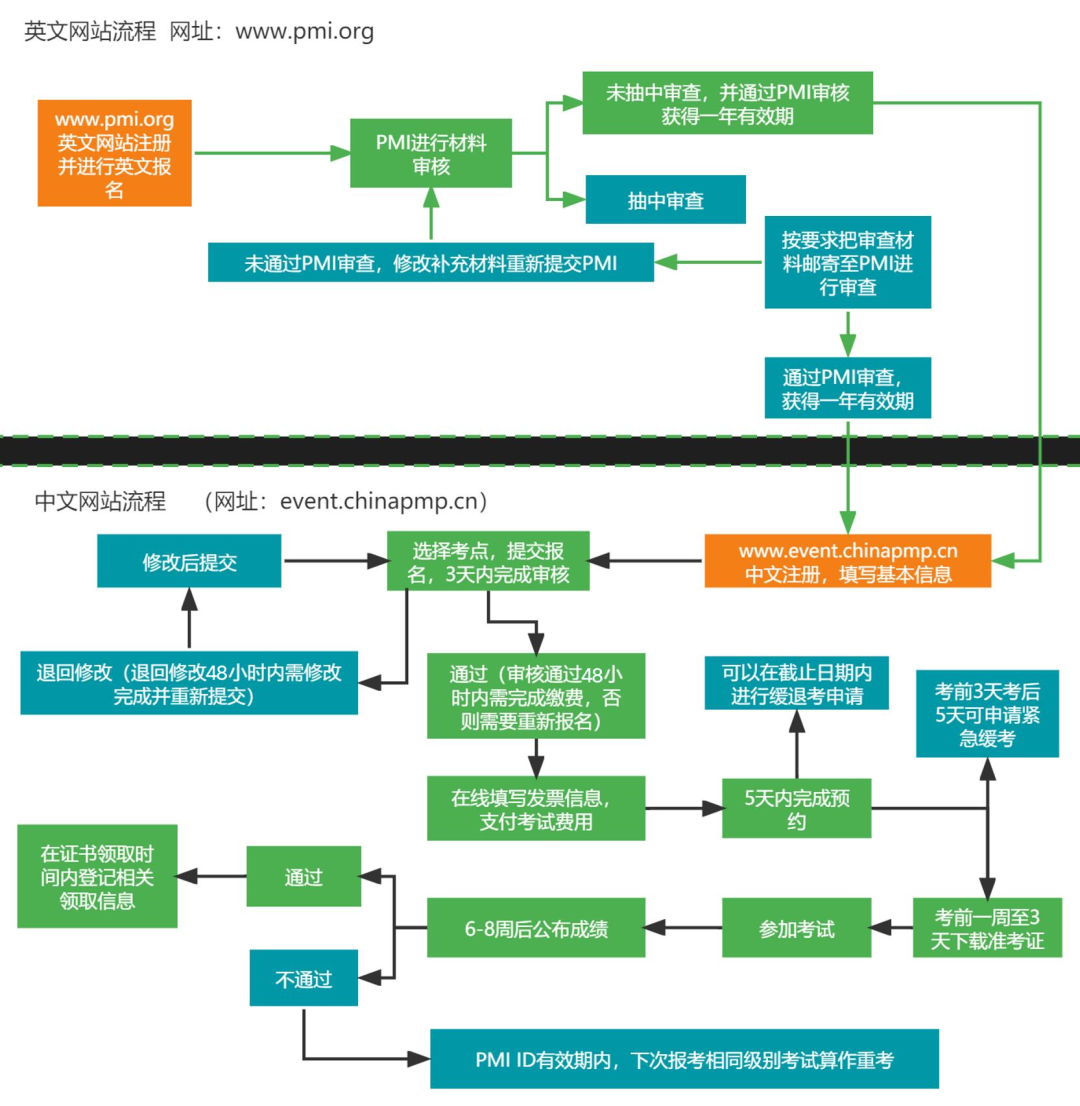
推理流程
从输入文本,到推理输出文本,LLama2模型处理流程如下:
step1 Tokenization
输入数据:一个句子或一段话。通常表示成单词或字符序列。 Tokenization即对文本按单词或字符序列切分,形成Token序列。Token序列再转换为整数索引序列(索引即是单子或字符在语料库中index)。
# input text
[Where is Shanxi]
# 切分tokens序列
['Where' 'is' 'Shanxi']
# 转换为语料库index
['BOS' '8' '21' '33' 'EOS']
step2 Embedding
Embedding将每个Token映射为一个实数向量,为Embeding Vector。
'BOS' -> [p_{00},p_{01},p_{02},...,p_{0d-1}]
'8' -> [p_{10},p_{11},p_{12},...,p_{1d-1}]
...
'EOS'-> [p_{n0},p_{n1},p_{n2},...,p_{nd-1}]
step3 位置编码
位置编码(Positional Encoding)向量提供Token在序列中位置的信息。位置编码是为了区分不同位置的Token,并为模型提供上下文关系的信息。
[p_{00},p_{01},p_{02},...,p_{0d-1}] [pe_{00},pe_{01},pe_{02},...,pe_{0d-1}]
[p_{10},p_{11},p_{12},...,p_{1d-1}] [pe_{10},pe_{11},pe_{12},...,pe_{1d-1}]
[p_{20},p_{21},p_{22},...,p_{2d-1}] + [pe_{20},pe_{21},pe_{22},...,pe_{2d-1}]
... ...
[p_{n0},p_{n1},p_{n2},...,p_{nd-1}] [pe_{n0},pe_{n1},pe_{n2} ,...,pe_{nd-1}]
step4 自回归生成
在生成任务中,使用自回归(Autoregressive)方式,即逐个生成输出序列中的每个Token,Decoder-Only。在解码过程中,每次生成一个Token时,使用前面已生成的内容作为上下文,来帮助预测下一个Token
自回归生成demo如下:
model = LLaMA2()
def generate(inputs, n_tokens_to_generate):
for _ in range(n_tokens_to_generate): # auto-regressive decode loop
output = model(inputs) # model forward pass
next = np.argmax(output[-1]) # greedy sampling
inputs.append(next) # append prediction to input
return inputs[len(inputs) - n_tokens_to_generate :] # only return generated tokens
input = [p0, p1,p2] #对应['BOS','where','is', 'shanxi']
output_ids = generate(input, 3) # 生成 ['p3','p4','p5']
output_ids = decode(output_ids) # 通过Tokenization解码
output_tokens = [vocab[i] for i in output_ids] # "Shanxi" "is" "a" "province"
step5 输出处理
生成的Token序列通过一个输出层,通常是线性变换加上Softmax函数,将每个位置的概率分布转换为对应Token的概率。根据概率,选择概率最高的Token或者作为模型的预测结果。
模型结构

LLama2模型结构与标 准Transformer Decoder结构基本一致,由32个Transfomer Block组成,不同点如下:
- 1 前置RMSNorm层
- 2 RoPE位置编码
- 3 KVCache
- 4 FeedForward层
1 RMSNorm
Transformer中的Normalization层采用LayerNorm来对Tensor进行归一化,RMSNorm就是LayerNorm的变体。 公式图:
# RMSNorm
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps # ε
self.weight = nn.Parameter(torch.ones(dim)) #可学习参数γ
def _norm(self, x):
# RMSNorm
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weight
2 RoPE旋转位置编码
什么是绝对位置编码,什么是相对位置编码?
位置编码向量生成方法有很多,常见绝对位置编码是使用三角函数对位置进行编码,公式如下:

绝对位置编码具有实现简单、计算速度快等优点,而相对位置编码则直接地体现了相对位置信号,跟直观理解吻合,实际性能往往也更好。
RoPE解决了一个什么问题?通过绝对位置编码的方式实现相对位置编码。
详细公式推理不展开,可参考引用。
# 精简版Attention
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.wq = Linear(...)
self.wk = Linear(...)
self.wv = Linear(...)
self.freqs_cis = precompute_freqs_cis(dim, max_seq_len * 2)
def forward(self, x: torch.Tensor):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
# attention 操作之前,应用旋转位置编码
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
#...
# 进行后续Attention计算
scores = torch.matmul(xq, xk.transpose(1, 2)) / math.sqrt(dim)
scores = F.softmax(scores.float(), dim=-1)
output = torch.matmul(scores, xv) # (batch_size, seq_len, dim)
# ......
3 KV Cache
KV cache的峰值显存占用大小: b(s+n)∗h∗l∗2∗2=4blh(s+n)b(s+n)*h*l*2*2=4blh(s+n)b(s+n)∗h∗l∗2∗2=4blh(s+n),输入序列长度s,输出序列长度n,fp16占用2个字节,transformer模型的层数为l,隐藏层维度为h。
def mha(x, c_attn, c_proj, n_head, kvcache=None): # [n_seq, n_embd] -> [n_seq, n_embd]
# qkv projection
# when we pass kvcache, n_seq = 1. so we will compute new_q, new_k and new_v
x = linear(x, **c_attn) # [n_seq, n_embd] -> [n_seq, 3*n_embd]
# split into qkv
qkv = np.split(x, 3, axis=-1) # [n_seq, 3*n_embd] -> [3, n_seq, n_embd]
if kvcache:
# qkv
new_q, new_k, new_v = qkv # new_q, new_k, new_v = [1, n_embd]
old_k, old_v = kvcache
k = np.vstack([old_k, new_k]) # k = [n_seq, n_embd], where n_seq = prev_n_seq + 1
v = np.vstack([old_v, new_v]) # v = [n_seq, n_embd], where n_seq = prev_n_seq + 1
qkv = [new_q, k, v]
4 FeedForward
SiLu激活函数:

那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。