架构图
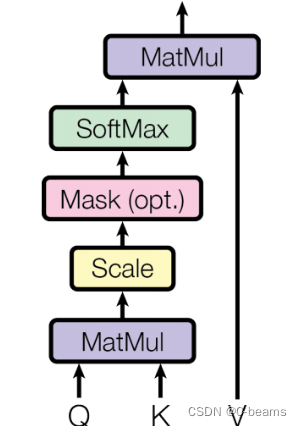
注意力机制与自注意力
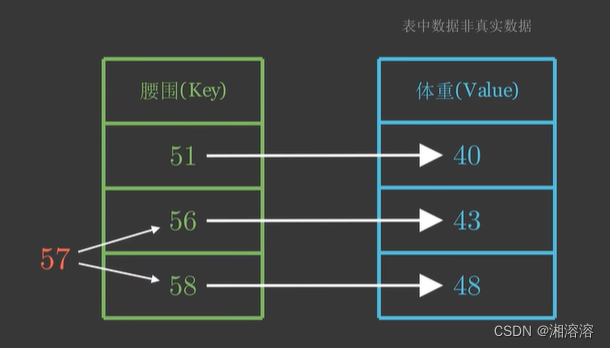
何为注意力机制,就像在理解句子时,关注特定的某个单词或短语。放到模型中,它能集中注意力在输入序列的某些部分,而忽略其他部分。
自注意力机制是一种特定类型的注意力机制,也称内部注意力。它使序列中的每个单词能“关注”其他单词,包括自己在内,以更好的理解上下文。
自注意力的工作原理
嵌入
首先,模型将输入序列中的每个单词嵌入到一个高维向量中,这个嵌入过程允许模型捕捉单词的语义相似性。
查询、键和值向量
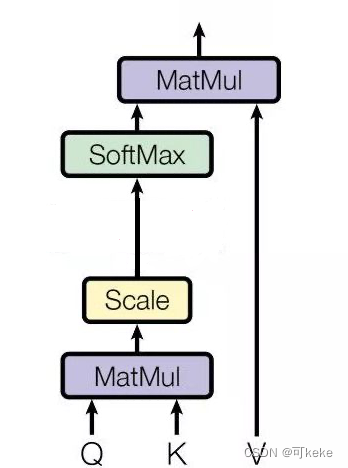
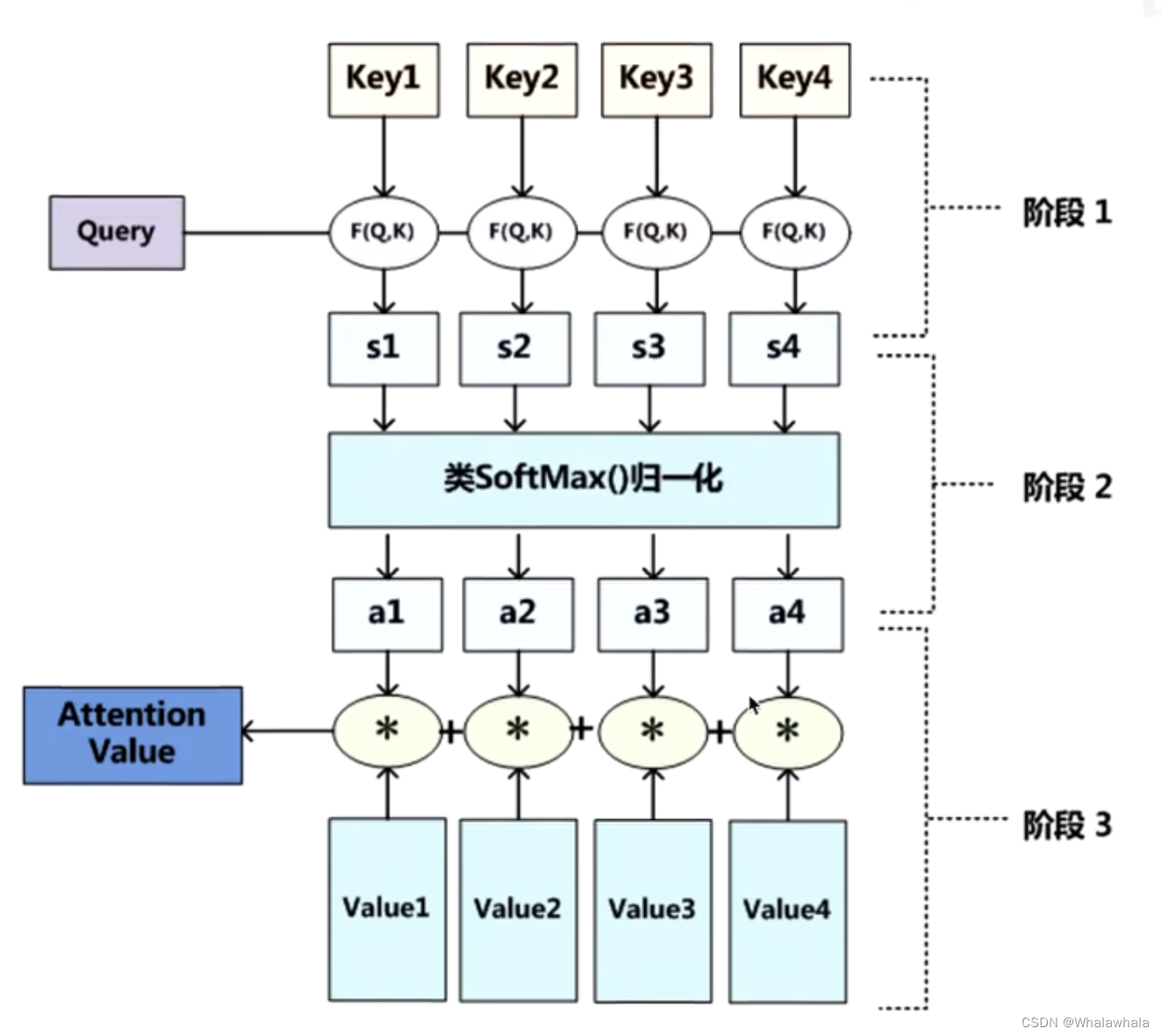
接下来,模型为序列的每个单词计算三个向量:查询向量、键向量和值向量。在训练过程中,模型学习这些向量,查询向量表示模型在序列中寻找的内容,键向量表示单词的键,即序列中其他单词应该注意的内容,值向量表示单词对输出所贡献的信息。
注意力分数
注意力分数通常通过查询向量的点积来实现,以评估单词之间的相似性。
SoftMax 归一化
利用softmax函数对注意力分数进行归一化,以获得注意力权重。这些权重表示每个单词应该关注序列中其他单词的程度。注意力权重较高的单词被认为对正在执行的任务更为关键。
加权求和
使用注意力权重计算向量的加权和,生成每个序列中单词的自注意机制输出,补货了来自其他单词的上下文信息。
一个简单通透的案例
# lib
import torch
import torch.nn.functional as F
# input
input_sequence = torch.tensor([[0.1, 0.2, 0.3],
[0.4, 0.5, 0.6],
[0.7, 0.8, 0.9]])
# gen weights of key, query and value
random_weights_key = torch.randn(input_sequence.size(-1), input_sequence.size(-1))
random_weights_query = torch.randn(input_sequence.size(-1), input_sequence.size(-1))
random_weights_value = torch.randn(input_sequence.size(-1), input_sequence.size(-1))
# compute key, query and value matrix
key = torch.matmul(input_sequence, random_weights_key)
query = torch.matmul(input_sequence, random_weights_query)
value = torch.matmul(input_sequence, random_weights_value)
# compute attention scores
attention_scores = torch.matmul(query, key.T) / torch.sqrt(torch.tensor(query.size(-1), dtype=torch.float32))
# compute attention weights
attention_weights = F.softmax(attention_scores, dim=-1)
# compute weighted sum
output = torch.matmul(attention_weights, value)
print(output)