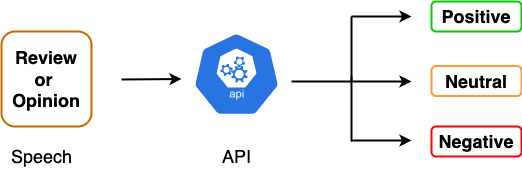
情感分析,也被称为观点挖掘,是自然语言处理(NLP)中一个流行的任务,因为它有着广泛的工业应用。在专门将自然语言处理技术应用于文本数据的背景下,主要目标是训练出一个能够将给定文本分类到不同情感类别的模型。下图给出了情感分类器的高级概述。
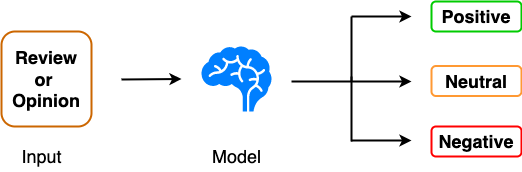
例如,三类分类问题的类可以是 Positive 、 Negative 和 Neutral 。三类情感分析问题的一个例子是流行的 Twitter 情感分析数据集(https://www.kaggle.com/datasets/jp797498e/twitter-entity-sentiment-analysis),这是一个实体级别的情感分析任务,针对 Twitter 上不同用户发布的多语言推文。
尽管以往大多数自然语言处理(NLP)研究和开发主要集中在对文本进行情感分析,但最近我们看到语音互动工具已被广泛采用和流行,使得研究人员和组织着手构建语音领域的情感分类器。
因此,这篇文章将演示如何使用 AssemblyAI API 和 Python 在对话数据上构建情感分析系统。端到端系统在涉及严格客户支持和反馈评估的领域有广泛的适用性,这使其成为一个重要而有价值的问题,特别是在语音领域。最后,我还将进行深入分析,以增强所得结果的可解释性,并从数据中得出适当的见解。
本文的代码在这里:https://deepnote.com/workspace/jacky-su-683574b3-f209-4c4a-871f-2917f8e4b220/project/Conversational-Sentiment-Analysis-Duplicate-4d2c8161-1773-4114-a416-d37e393c3ee5/notebook/sentiment%20analysis-0476d5b83f0346d3958dba74bc803e83。
文中有很多处本应该有嵌入代码,但是CSDN编辑器不支持展示,所以最好对照着代码链接来看文章,代码链接中的代码也是按照本文的目录结构分的,所以很容易对应。
对话音频数据的情感分析
在这一部分,我将演示如何使用 AssemblyAI API 将给定录音对话中的单句分类为三种情感类别: Positive 、 Negative 和 Neutral 。
步骤 1:安装要求
构建情感分类器的要求非常少。就 Python 库而言,我们只需要 requests 包。可以按照以下方式进行:
pip install requests
步骤 2:生成您的 API 令牌
下一步是在 AssemblyAI 网站(https://www.assemblyai.com/)上创建一个免费账户。完成后,您将获得私有 API 访问密钥,我们将使用它来访问语音转文本模型。
第 3 步:上传音频文件
为了完成本教程,我将使用两人之间的预录音对话来执行情感分析。一旦您获得 API 密钥,就可以开始对预录音文件进行情感分类任务。
然而,在此之前,您需要上传音频文件,以便通过 URL 访问。选项包括上传到 AWS S3 存储桶、SoundCloud 等音频托管服务,或 AssemblyAI 的自托管服务等。我已将音频文件上传到 SoundCloud,可以在下面访问。
如果您希望将音频文件直接上传到 AssemblyAI 的托管服务,您也可以这样做。我已在下面的代码块中逐步演示了这一步骤。
步骤 3.1:导入需求
我们从导入项目所需的要求开始。
步骤 3.2:指定文件位置和 API_Key
接下来,我们需要指定本地机器上音频文件的位置以及注册后获得的 API 密钥。
第 3.3 步:指定上传端点
- endpoint : 这指定了要调用的服务,在本例中是"上传"服务。
- headers :这包含了 API 密钥和内容类型。
步骤 3.4:定义上传函数
音频文件一次最多只能上传 5MB(5,242,880 字节)。因此需要分块上传数据,然后在服务端合并这些块。因此您无需担心处理大量 URL。
步骤 3.5:上传
最后一步是发起 POST 请求。POST 请求的响应是一个 JSON,其中包含了音频文件的 upload_url 。我将在执行音频情感分类的下一步骤中使用这个 URL。
第 4 步:情感分析
在这一步中,我们已经完成了执行对音频文件进行情感分析任务所需的所有必要前提条件。现在,我们可以继续调用 API 来获取所需的结果。这是一个分两步进行的过程,将在下面的小节中进行演示。
第 4.1 步:提交文件进行转录
第一步是调用一个 HTTP POST 请求。这实质上是将您的音频文件发送到后台运行的 AI 模型以进行转录,并指示它们对转录的文本执行情感分析。
发送到 POST 请求的参数是:
- endpoint :它指定要调用的转录服务。
- json :这包含你的音频文件的 URL 作为 audio_url 键。由于我们希望对对话数据进行情感分析, sentiment_analysis 标志和 speaker_labels 被设置为 True 。
- headers :这包含了 authorization 键和 content-type 。
在收到的 JSON 响应中,当前的 post 请求状态为 queued 。这表示音频正在进行转录。
此外, sentiment_analysis 标志也出现在 JSON 响应中。但是,与 sentiment_analysis_results 键相对应的值为 None,因为当前状态为 queued 。
步骤 4.2:获取转录结果
要检查我们的 POST 请求的状态,我们需要使用上面收到的 JSON 响应中的 id 键发出一个 GET 请求。
接下来,我们可以进行一个 GET 请求,如下面的代码块所示。
传递给 GET 请求的参数为:
- endpoint :这指定了通过 id 键确定的调用的服务和 API 调用标识符。
- headers :这里保存您的唯一 API 密钥。
在这里,您应该知道转录结果在 status 键变为 completed 之前是不会准备好的。转录所需的时间取决于输入音频文件的长度。因此,您必须定期重复 GET 请求来检查转录状态。下面实现了一种简单的方法:
情感分析结果
一旦 status 变为 completed ,您将收到类似于下面提到的响应。
- 在 JSON 响应中, status 被标记为 completed 。这表示在转录音频时没有出现错误。
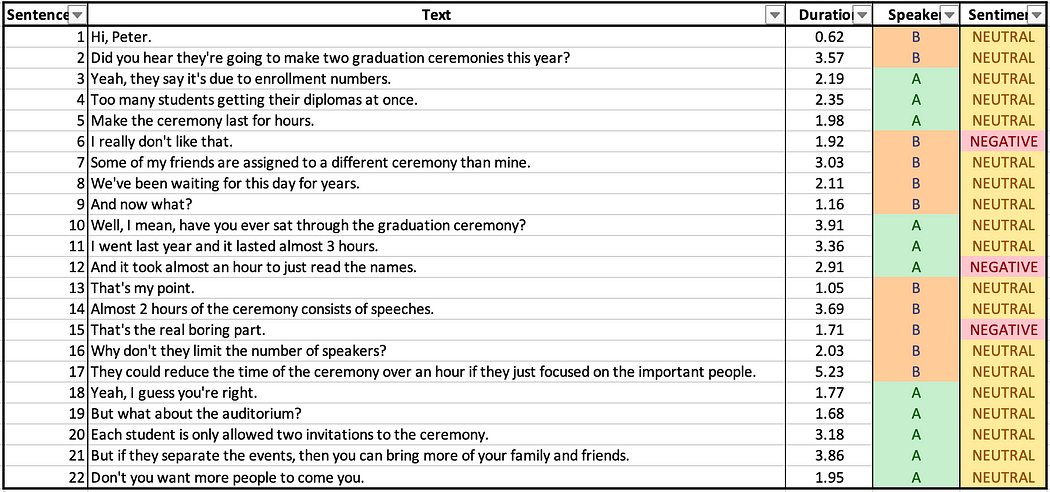
- text 键包含了输入音频对话的全部转录文本,其中包括22个句子。
- 由于音频文件由多个扬声器组成,我们在 words 键中看到所有 speaker 键均为非空。 speaker 键要么为"A"要么为"B"。
- 我们可以看到所有个别单词和整个转录文本的置信度得分。该得分范围从 0 到 1,0 为最低,1 为最高。
- 对于音频中 22 个单独句子的情感分析结果可以通过 JSON 响应中的 sentiment_analysis_results 键访问。
- 与每个句子相对应,我们获得一个与上述第 4 点类似的 confidence 分数。
- 每个句子的情感可以使用句子字典的 sentiment 键来检索。以下显示了第二句的情感分析结果:
情感分析洞见
JSON 通常很难阅读和解释。因此,为了使数据更具有视觉吸引力,并进行进一步分析,让我们将上述情感分析结果转换为 DataFrame。我们将存储句子的 text 、 duration 、 speaker 和 sentiment 。下面是实现:
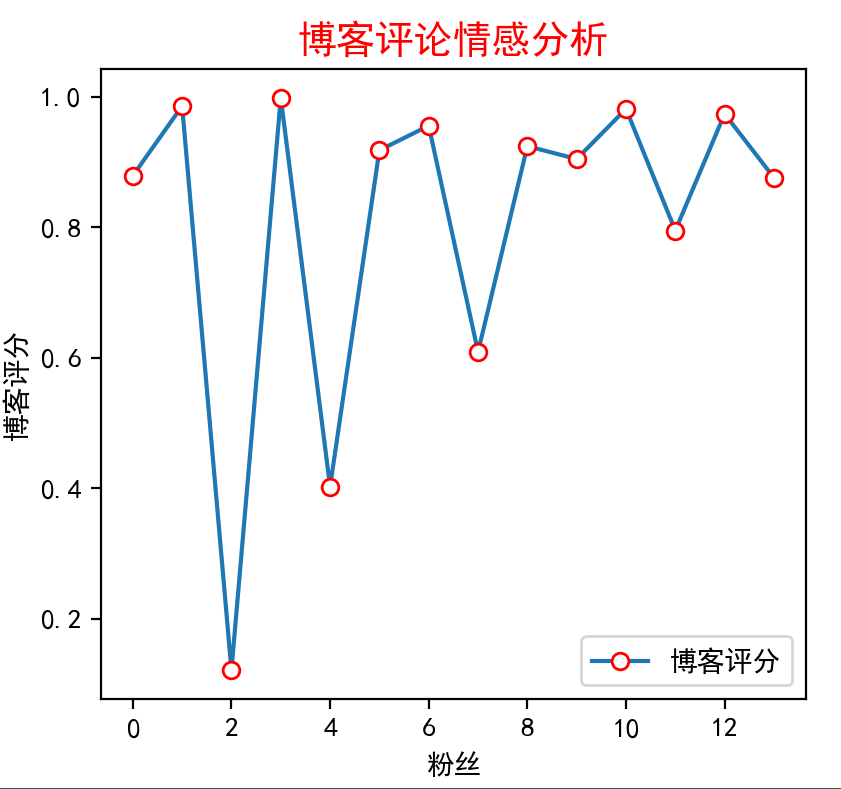
在上述代码生成的 DataFrame 如下图所示。其中包括对话中说的 22 句话,以及相应的说话者标签(“A"和"B”)、持续时间(秒)和模型预测的情绪。
演讲者的分布
每个演讲者发言的句子数量可以使用如下所示的 value_counts() 方法进行计算:
想查看说话人的百分比分布,可以像下面这样将 normalize = True 传递给 value_counts() 方法:
演讲者"A"和"B"在句子数量方面对对话做出了同等贡献。
扬声器持续时间分布
接下来,让我们计算对话中每位发言者的个人贡献。如下所示:
我们使用 groupby() 方法并计算他们演讲的总时长。A 人是演讲持续时间最长的主要演讲者。
#3 情绪分布
在通话过程中说的 22 句话中,只有三句被标记为 negative 情感。此外,没有任何一句被预测为 positive 情感。
正态分布可以按以下方式计算:
#4 发言人层面的情感分布
最后,让我们计算个人发言者的情感分布。这里,我们将使用 crosstab() 而不是 groupby() 方法来实现更好的可视化效果。这如下所示:
发言人"A"说出的否定性句子的比例高于发言人"B"。
#5 情感层面平均句子持续时间
最后,我们将计算属于个别情绪类别的句子的平均持续时间。这是使用 groupby() 方法实现的:
平均 negative 句子的持续时间小于 neutral 句子的持续时间。
总之,在这篇文章中,我们讨论了 AssemblyAI API 的一个特定的 NLP 用例。具体来说,我们看到如何在一个由多个说话者组成的预录音音频文件上构建一个情感分类模块。最后,我们对情感分析结果进行了深入分析。从 API 获得的结果突出了输入音频文件中 22 个单独句子的情感。