文章目录
1、线性模型
用于建立输入与输出特征之间的线性关系,假设输入与输出特征存在一个线性关系。目标是通过学习不断的更新权重参数,使损失函数越来越小,预测值和真实值越接近。
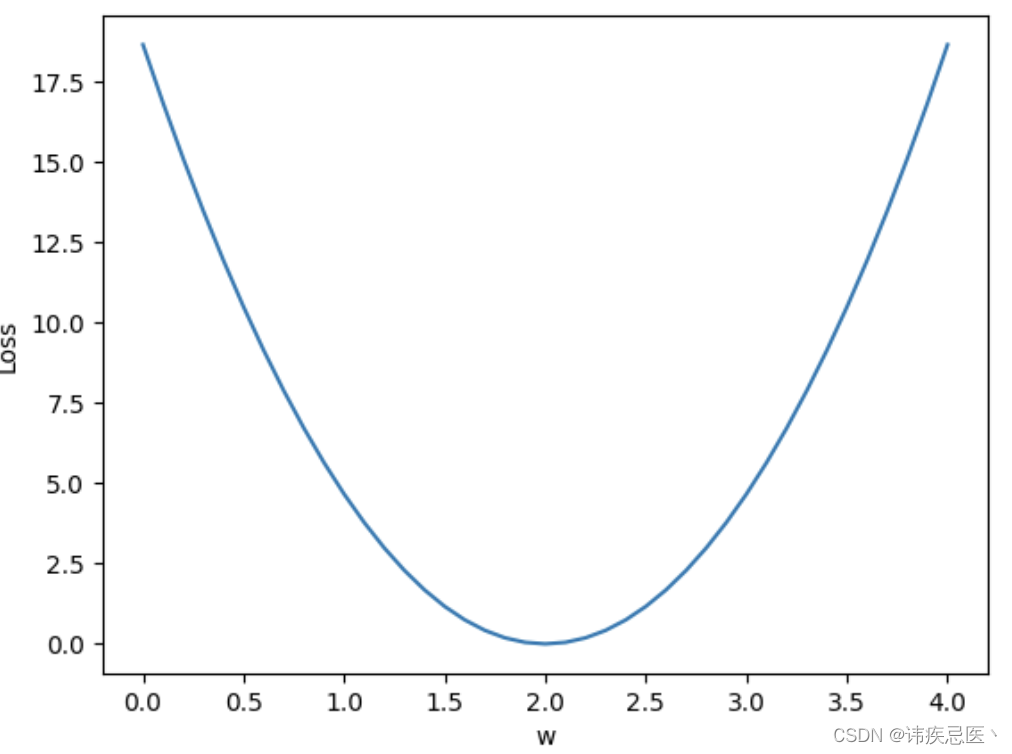
可以看出,当权重位2.0的时候,loss是最小的
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
# 线性模型y = x*w
def forward(x):
return x * w
def loss(x,y):
y_pred = forward(x)
return (y_pred-y) * (y_pred-y)
w_list = []
mse_list = []
# w权重值从0.0开始每次增加0.1到4.0结束
for w in np.arange(0.0,4.1,0.1):
print('w=',w)
l_sum = 0
for x_val,y_val in zip(x_data,y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val,y_val)
l_sum += loss_val
print('\t',y_pred_val,x_val,y_val,loss_val)
print('mes=',l_sum/3)
w_list.append(w)
mse_list.append(l_sum/3)
plt.plot(w_list,mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()
2、梯度下降
梯度下降是一种优化算法,常用于机器学习和数值优化中。它的目标是通过迭代的方式找到一个函数的局部最优解或全局最优解,梯度就是导数,梯度下降法就是一种通过求目标函数的导数来寻找目标函数最小化的方法。梯度下降目的是找到目标函数最小化时的取值所对应的自变量的值,目的是为了找自变量X。
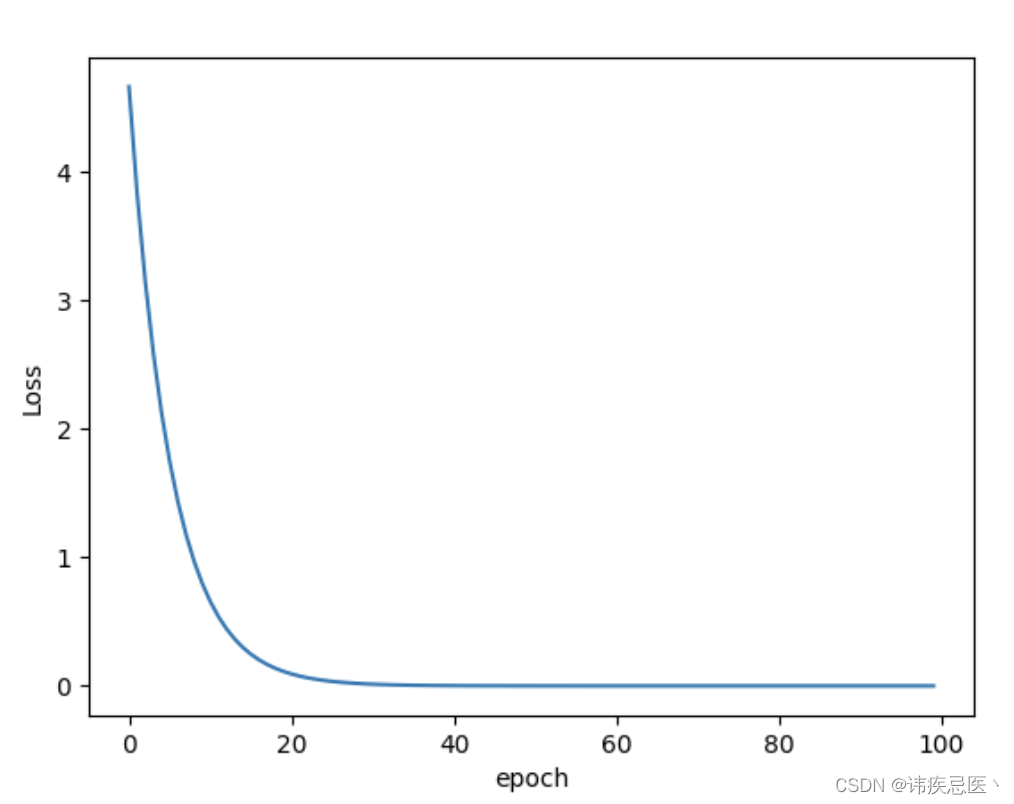

# 梯度下降法
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
w = 1.0
def forward(x):
return x * w
# mse均方误差
def cost(xs,ys):
cost = 0
for x,y in zip(xs,ys):
y_pred = forward(x)
cost += (y_pred-y)**2
return cost/len(xs)
# 梯度,求和求均值
def gradient(xs,ys):
grad = 0
for x,y in zip(xs,ys):
grad += 2 * x * (x * w - y)
return grad/len(xs)
w_list = []
cost_list = []
for epoch in range(100):
cost_val = cost(x_data,y_data)
grad_val = gradient(x_data,y_data)
w-=0.01*grad_val
w_list.append(epoch)
cost_list.append(cost_val)
print("Epoch:",epoch,'w=',w,'loss:',cost_val)
print("Predict(after training),",4,forward(4))
plt.plot(w_list,cost_list)
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.show()
3、反向传播
通过计算损失函数关于网络参数的梯度,然后利用梯度信息更新网络参数,使得网络能够逐步优化和学习。反向传播算法的核心思想是根据损失函数的梯度,将误差从网络的输出层向输入层进行反向传播,然后利用梯度信息来调整网络参数,使得网络能够逐渐优化和学习任务中的模式和特征。
import torch
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
w = torch.Tensor([1.0])
w.requires_grad = True
def forward(x):
return x * w
def loss(x,y):
y_pred = forward(x)
return (y_pred-y)**2
for epoch in range(100):
for x,y in zip(x_data,y_data):
# 1、计算损失
l = loss(x,y)
# 2、做反向传播
# 计算梯度保存在w中
l.backward()
print("\tgrad:",x,y,w.grad.item())
# 3、使用梯度去更新权重信息
w.data = w.data-0.01*w.grad.data
# 把权重里面梯度数据全部清零
w.grad.data.zero_()
print("progress:",epoch,l.item())
4、使用Pytorch实现线性回归
import torch
# pytorch 线性回归问题
# 4步操作
# 1、先准备数据集
# 2、设计模型
# 3、构造损失函数,优化器
# 4、训练过程
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[2.0],[4.0],[6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel,self).__init__()
# 输入和输出都是1,1
self.linear = torch.nn.Linear(1,1)
def forward(self,x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
# 设置MSE损失函数
criterion = torch.nn.MSELoss(size_average=False)
# 设置优化器,学习率更新
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
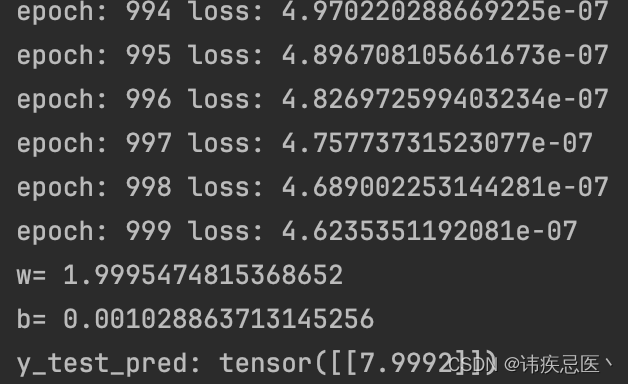
print("epoch:",epoch,"loss:",loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("w=",model.linear.weight.item())
print("b=",model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print("y_test_pred:",y_test.data)
5、使用Pytorch实现逻辑回归
5.1、二分类问题
# 逻辑回归处理而分类问题
import torch
import torch.nn.functional as F
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[0],[0],[1]])
class LogisticRegression(torch.nn.Module):
def __init__(self):
super(LogisticRegression,self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self,x):
# 使用sigmoid函数将线性模型转化成非线性模型,结果转化成0-1之间的数
y_pred = F.sigmoid(self.linear(x))
return y_pred
model = LogisticRegression()
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
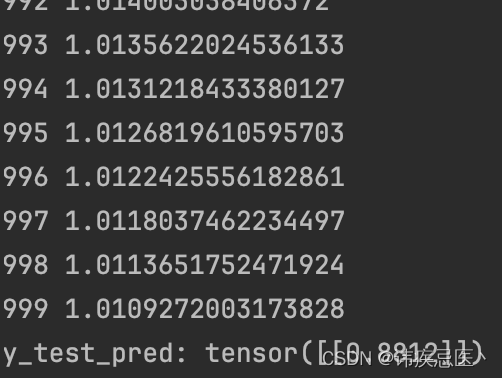
print(epoch,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print("y_test_pred:",y_test.data)
5.2、多维输入二分类问题
数据集格式
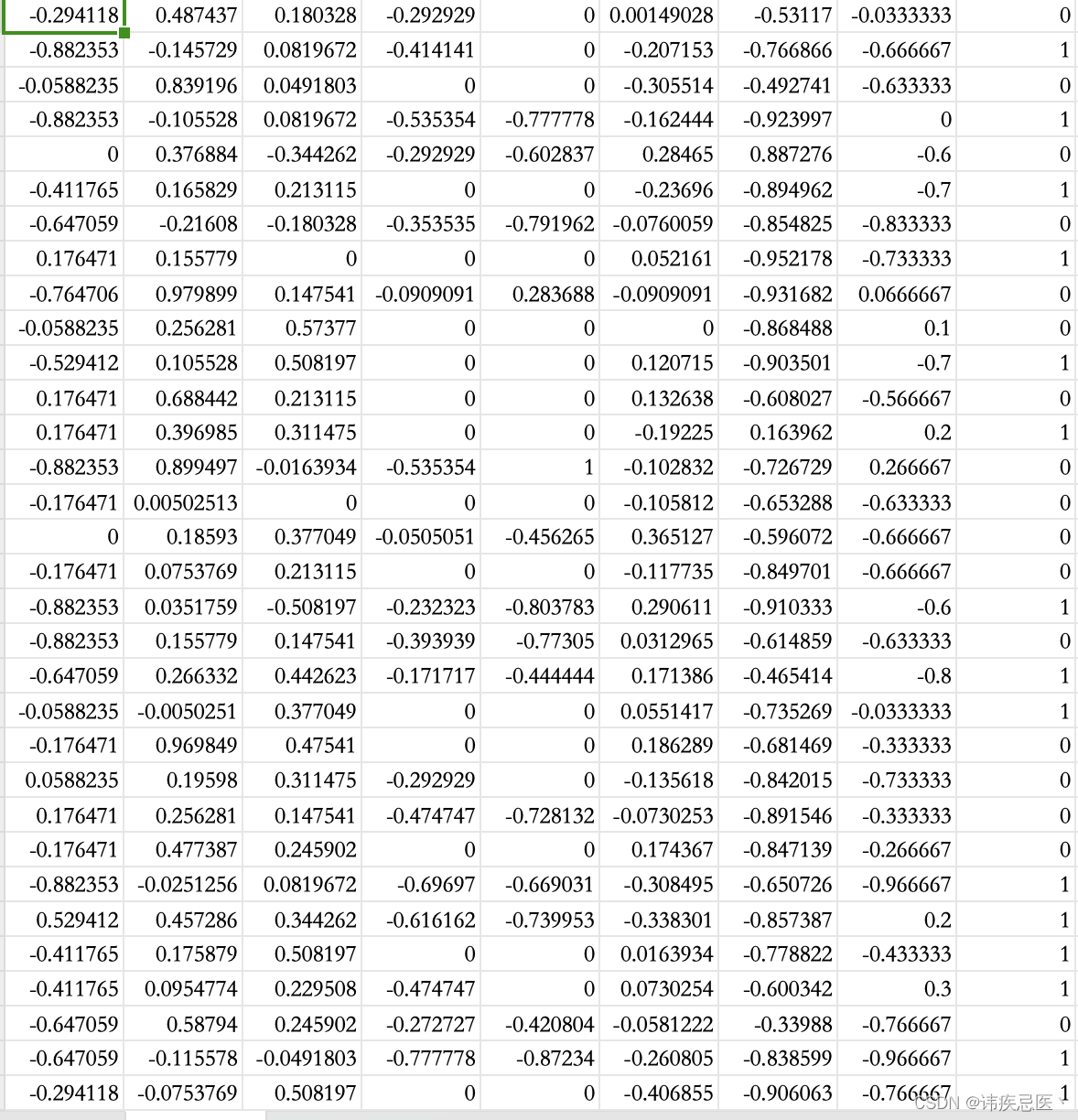
# 多维特征输入问题
import torch
import numpy as np
xy = np.loadtxt('diabetes.csv.gz',delimiter=',',dtype=np.float32)
# 创建tensor
x_data = torch.from_numpy(xy[:,:-1])
y_data = torch.from_numpy(xy[:,[-1]])
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
5.3、加载数据集类
# 数据加载类使用
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
def __getitem__(self, index):
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
if __name__ == '__main__':
for epoch in range(100):
for i,data in enumerate(train_loader,0):
# (x,y)
inputs,labels = data
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
5.4、多分类问题(使用线性模型)
手写字识别
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
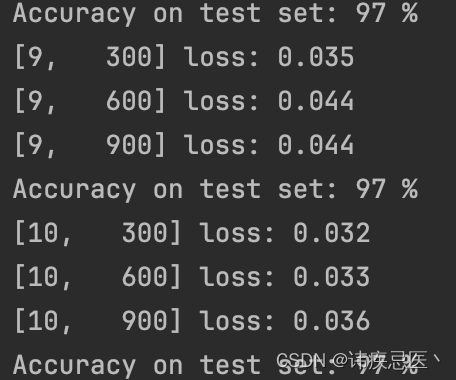
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
5.5、多分类问题(使用卷积神经网络)
卷积神经网络(Convolutional Neural Network,CNN)是一种常用于处理具有网格结构数据的深度学习模型。它在计算机视觉领域取得了巨大成功,并被广泛应用于图像分类、目标检测、图像生成等任务。
CNN的设计灵感来源于生物视觉系统中神经元的工作原理。它通过多层的卷积层、池化层和全连接层构成,每一层都包含一些可学习的参数(权重和偏置),用于从原始输入数据中提取和学习特征。
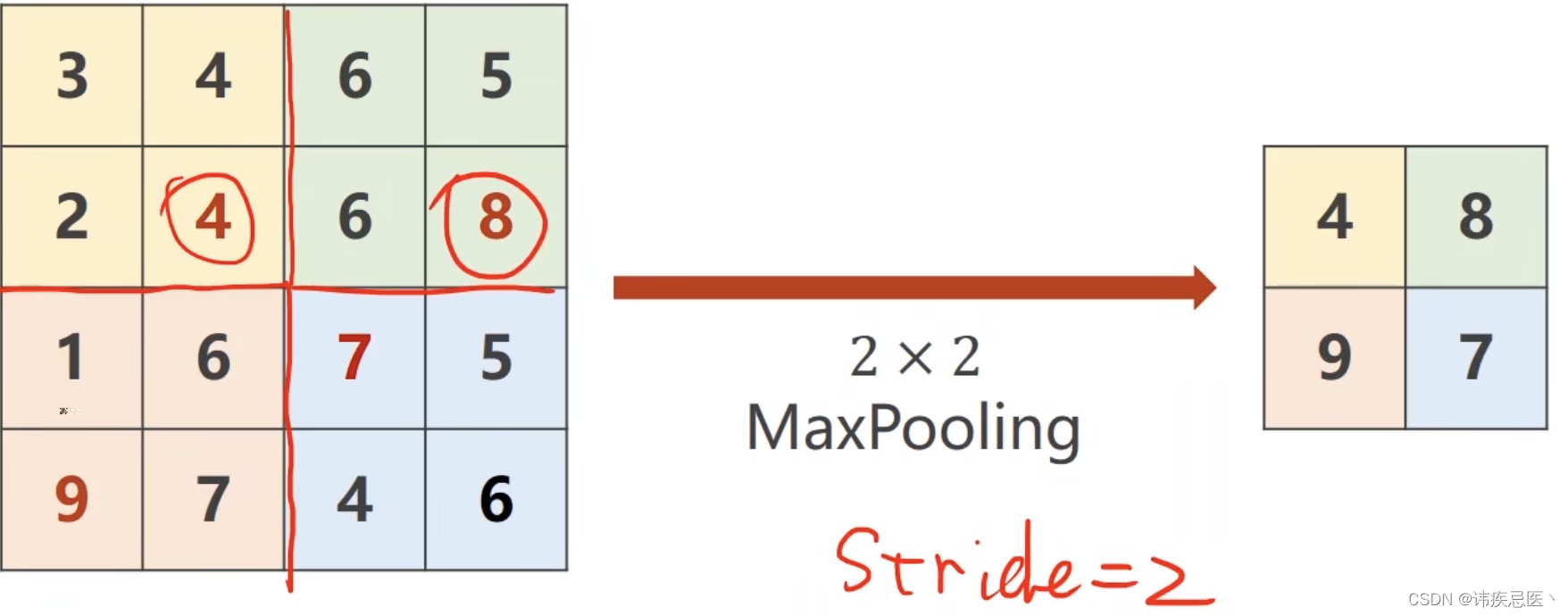
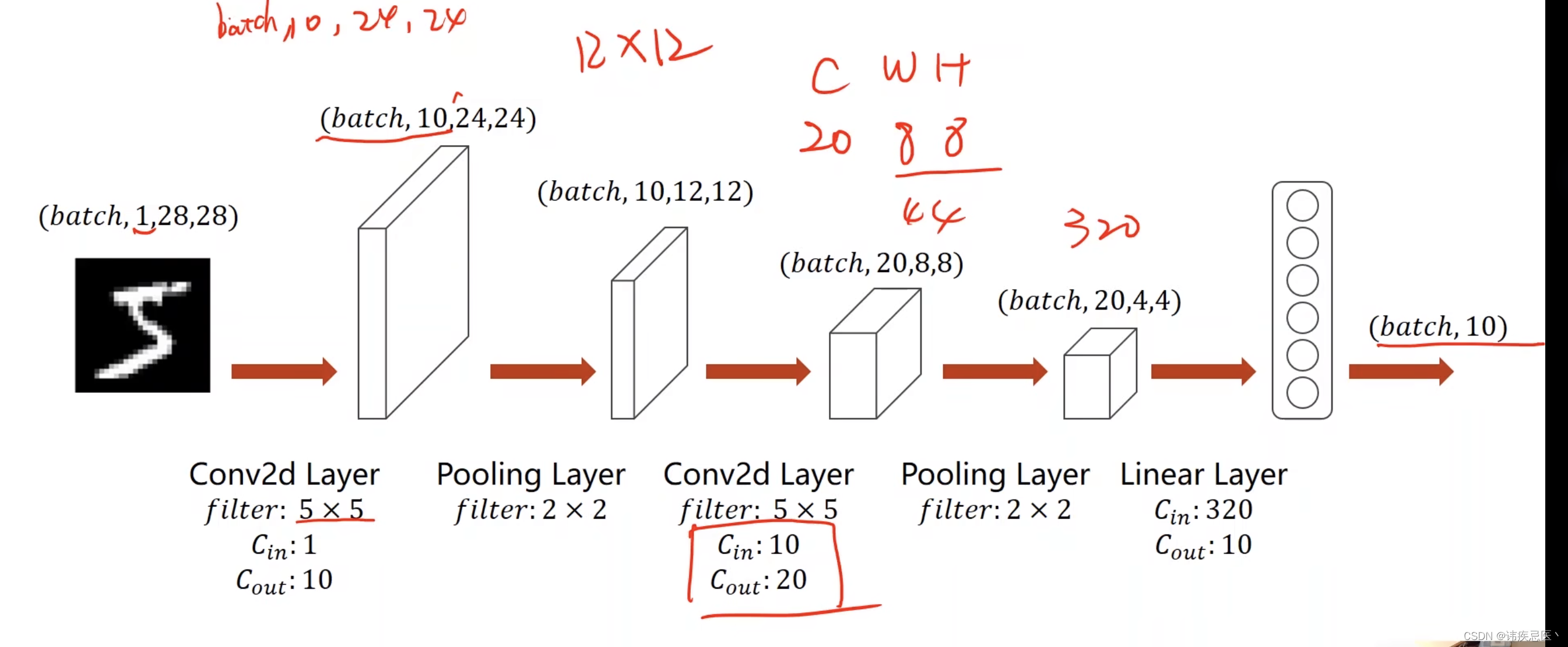
下面是CNN的主要组成部分和工作原理:
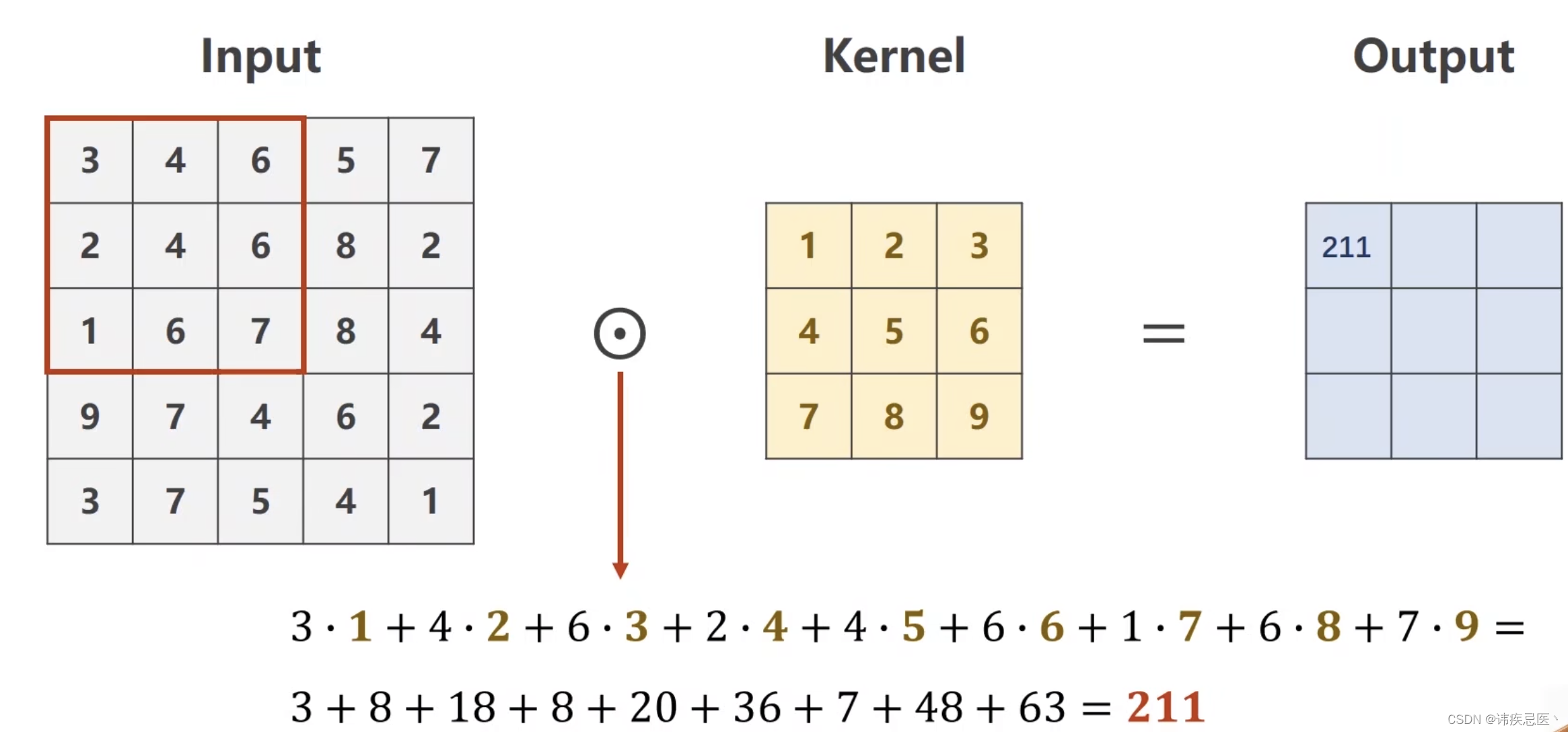
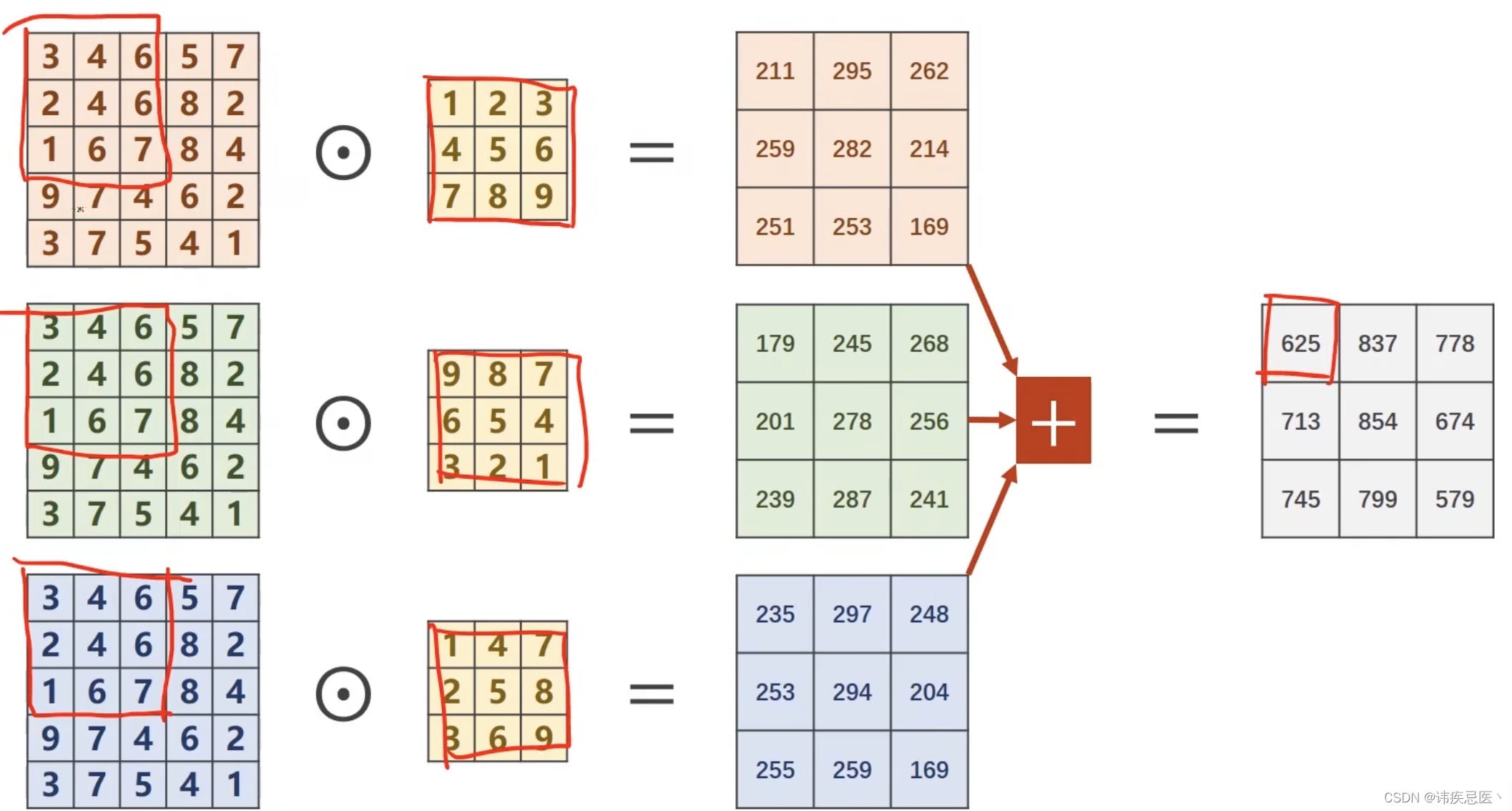
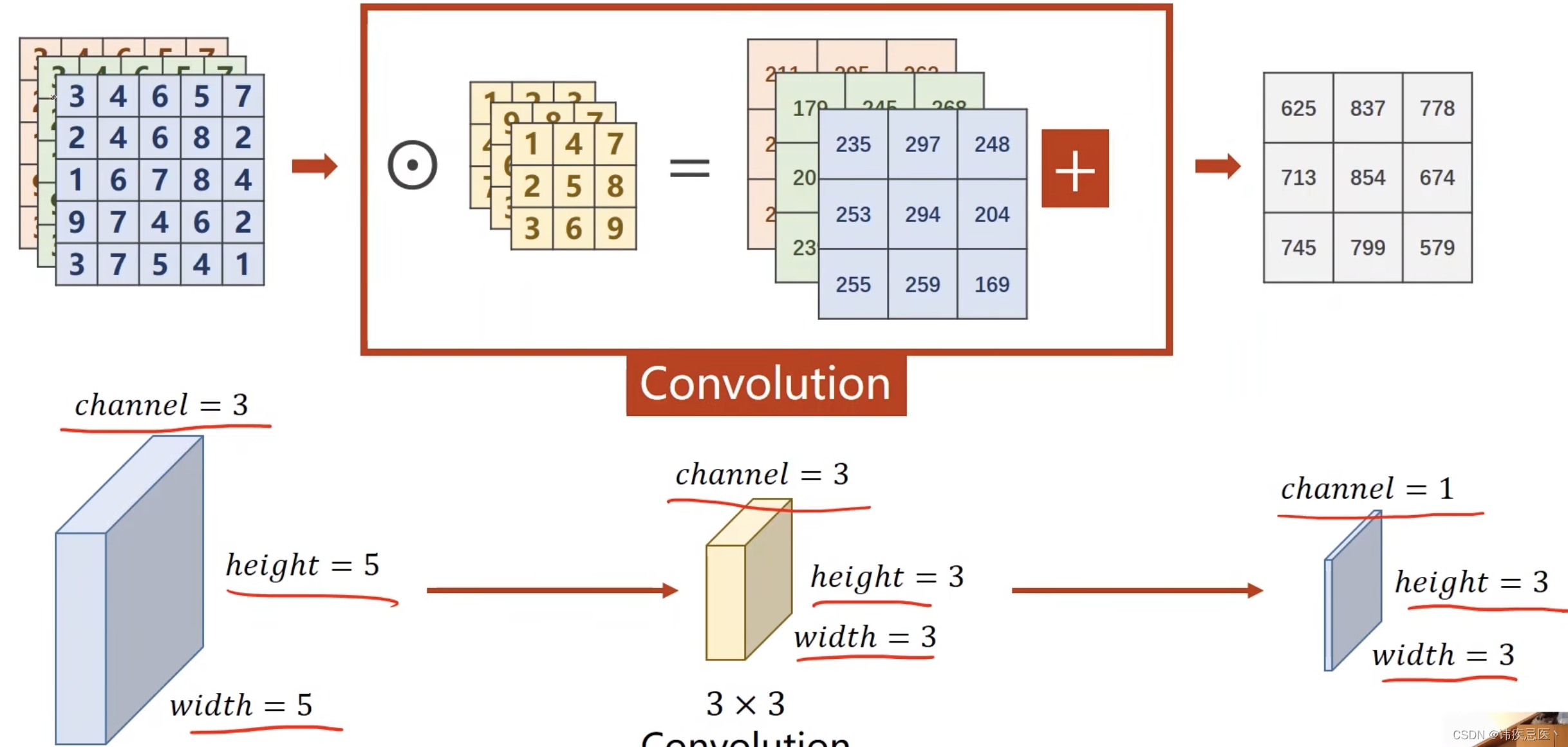
1、卷积层(Convolutional Layer):卷积层是CNN的核心组成部分。它通过卷积操作对输入数据进行特征提取。卷积操作使用一个可学习的滤波器(或称为卷积核)对输入数据进行局部感知,并生成特征图(Feature Map)。卷积层的参数包括滤波器的大小、步长(stride)和填充(padding)等。
2、激活函数(Activation Function):卷积层之后通常会使用激活函数对特征图进行非线性变换,以增加网络的表达能力。常用的激活函数包括ReLU(Rectified Linear Unit)、Sigmoid和Tanh等。
3、池化层(Pooling Layer):池化层用于减小特征图的空间尺寸,并降低模型对位置的敏感性。常用的池化操作为最大池化(Max Pooling),它在每个池化窗口中选择最大值作为输出。
4、全连接层(Fully Connected Layer):全连接层将前一层的所有特征图连接到当前层的每个神经元,用于进行分类或回归等任务。全连接层通常位于网络的最后几层,用于将特征整合为最终的输出。
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5)
self.conv2 = torch.nn.Conv2d(10,20,kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320,160)
self.fc2 = torch.nn.Linear(160,64)
self.fc3 = torch.nn.Linear(64,10)
def forward(self,x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size,-1)
x = self.fc(x)
x = self.fc2(x)
x = self.fc3(x)
return x
5.6、多分类问题(使用InceptionA模块)
Inception是一个流行的卷积神经网络模型系列,被广泛用于图像分类和目标识别等计算机视觉任务。它的设计目标是在保持计算效率的同时增加网络的表示能力。该模块通过在不同尺度上进行卷积操作,并将它们的输出进行拼接,以捕捉输入数据的多尺度特征。
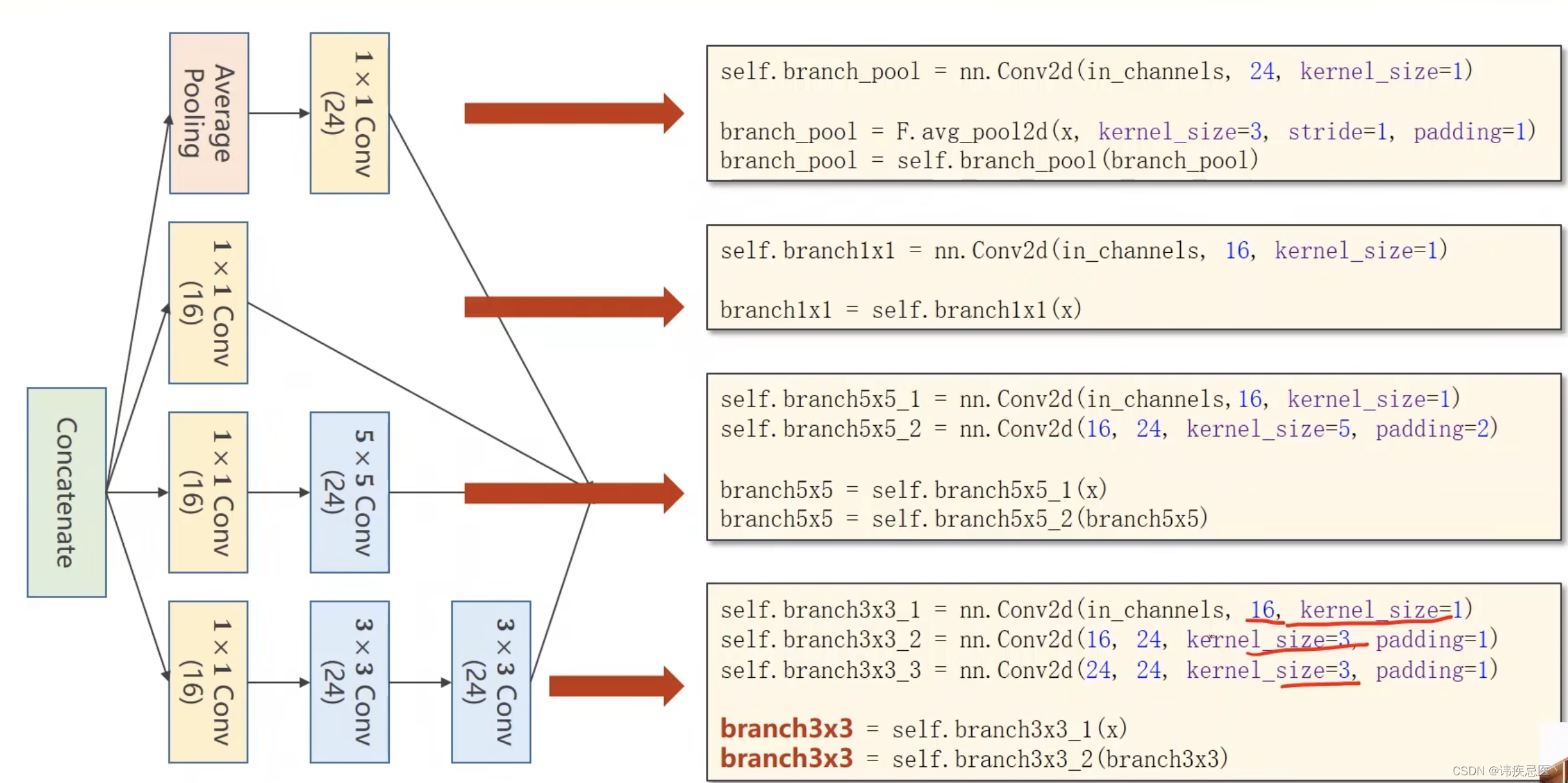
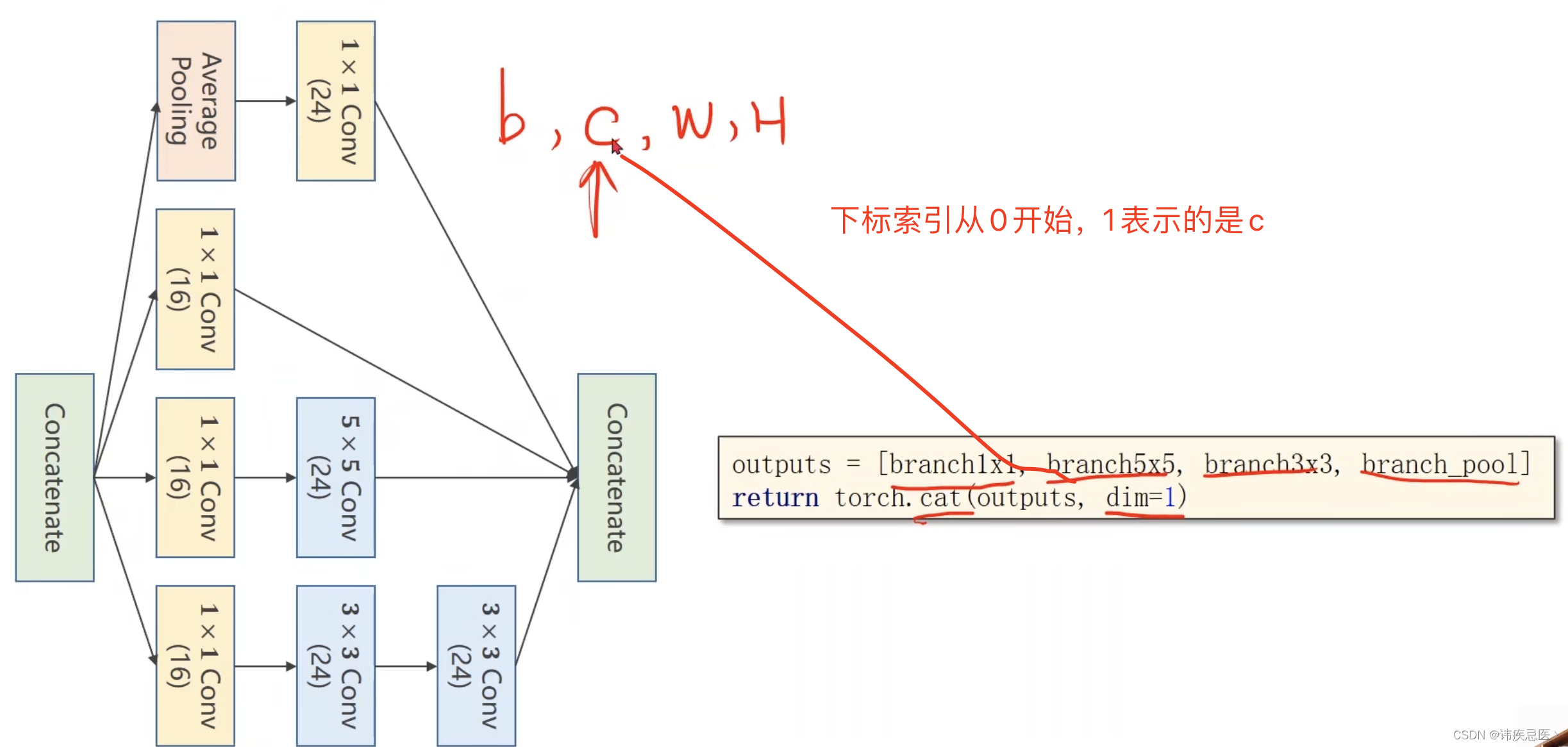
1、1x1卷积:InceptionA模块的第一个分支是一个1x1卷积层,用于减少输入特征图的通道数。这有助于减少计算量,并引入非线性变换。
2、3x3卷积:InceptionA模块的第二个分支是一个3x3卷积层,用于捕捉输入特征图的空间信息。
3、5x5卷积:InceptionA模块的第三个分支是一个5x5卷积层,用于捕捉更大感受野的特征。
4、1x1卷积(降维):为了减少计算复杂度,InceptionA模块在3x3和5x5卷积之前引入了1x1卷积层,用于减少通道数。
最大池化:InceptionA模块的最后一个分支是一个最大池化层,用于捕捉输入特征图的空间信息,并减小尺寸。
class InceptionA(torch.nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = torch.nn.Conv2d(in_channels,16, kernel_size=1)
self.branch5x5_2 = torch.nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = torch.nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = torch.nn.Conv2d(24, 24, kernel_size=3, padding=1)
self.branch_pool = torch.nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
5.7、多分类问题(使用Residual模块)
Residual指的是残差(residual)连接或残差块(residual block),它是一种用于构建深层神经网络的技术,旨在解决梯度消失和网络退化的问题。Residual连接的核心思想是引入跨层的直接连接,使得网络可以学习残差函数,从而更容易地训练深层网络。
在传统的神经网络中,网络的每一层都是通过将前一层的输出作为输入来构建的。然而,当网络变得很深时,信息在经过多个层传播时可能会逐渐衰减,导致梯度消失的问题。这使得深层网络的训练变得困难,同时也限制了网络的性能。
Residual连接通过在网络中引入跳跃连接,允许信息在网络中直接跨层传播。具体地,Residual连接将前一层的输出与当前层的输入相加,从而形成了一个"残差"。这个残差函数表示当前层需要学习的部分,而网络只需要学习如何调整残差,而不是完全重建特征。
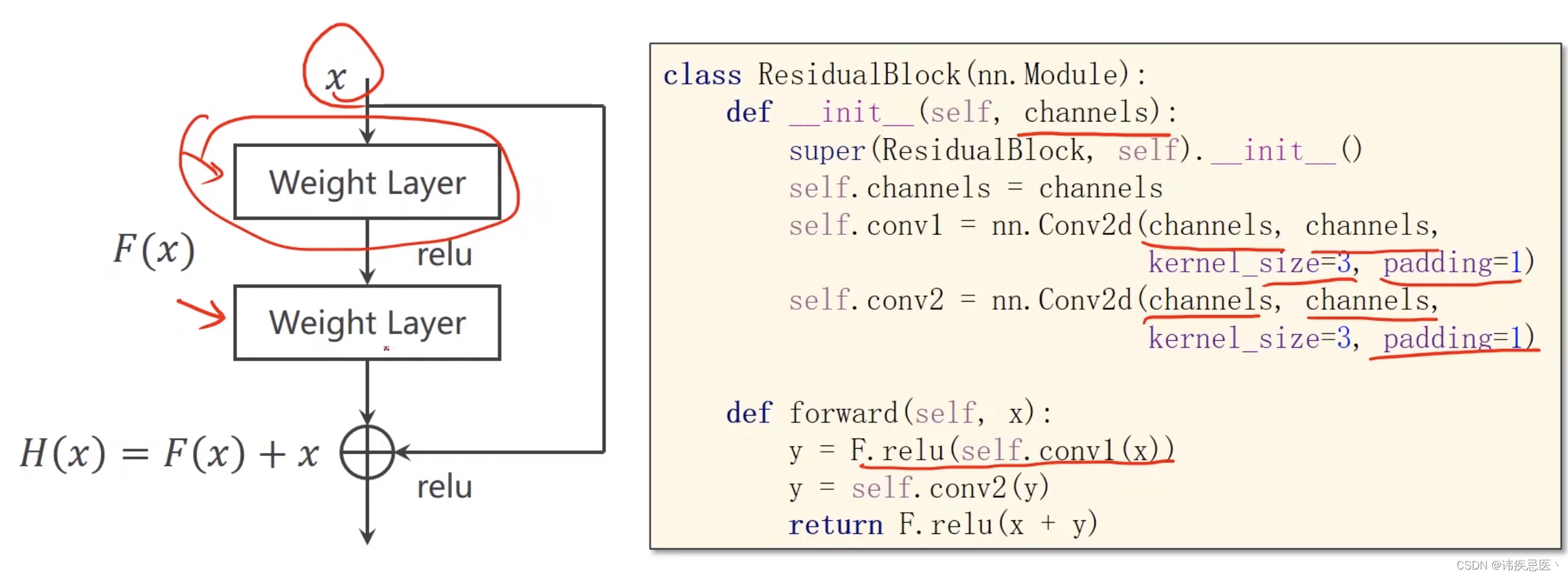
class ResidualBlock(torch.nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = torch.nn.Conv2d(channels, channels,
kernel_size=3, padding=1)
self.conv2 = torch.nn.Conv2d(channels, channels,
kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = torch.nn.Conv2d(16, 32, kernel_size=5)
self.mp = torch.nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = torch.nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x


















![[ZJCTF 2019]NiZhuanSiWei](https://img-blog.csdnimg.cn/direct/1977ec31463745039afaaab229c6f5c0.png)