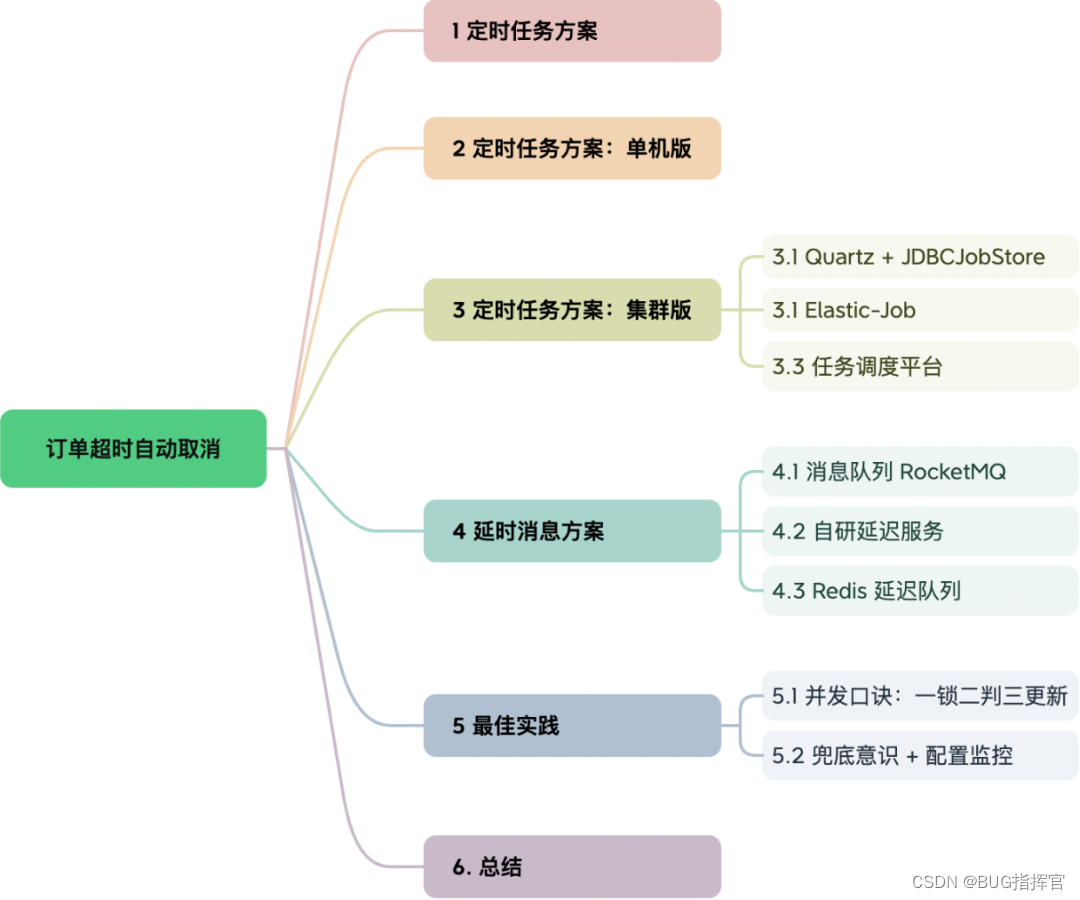
官网指引:
- facebookresearch SlowFast :https://github.com/facebookresearch/SlowFast
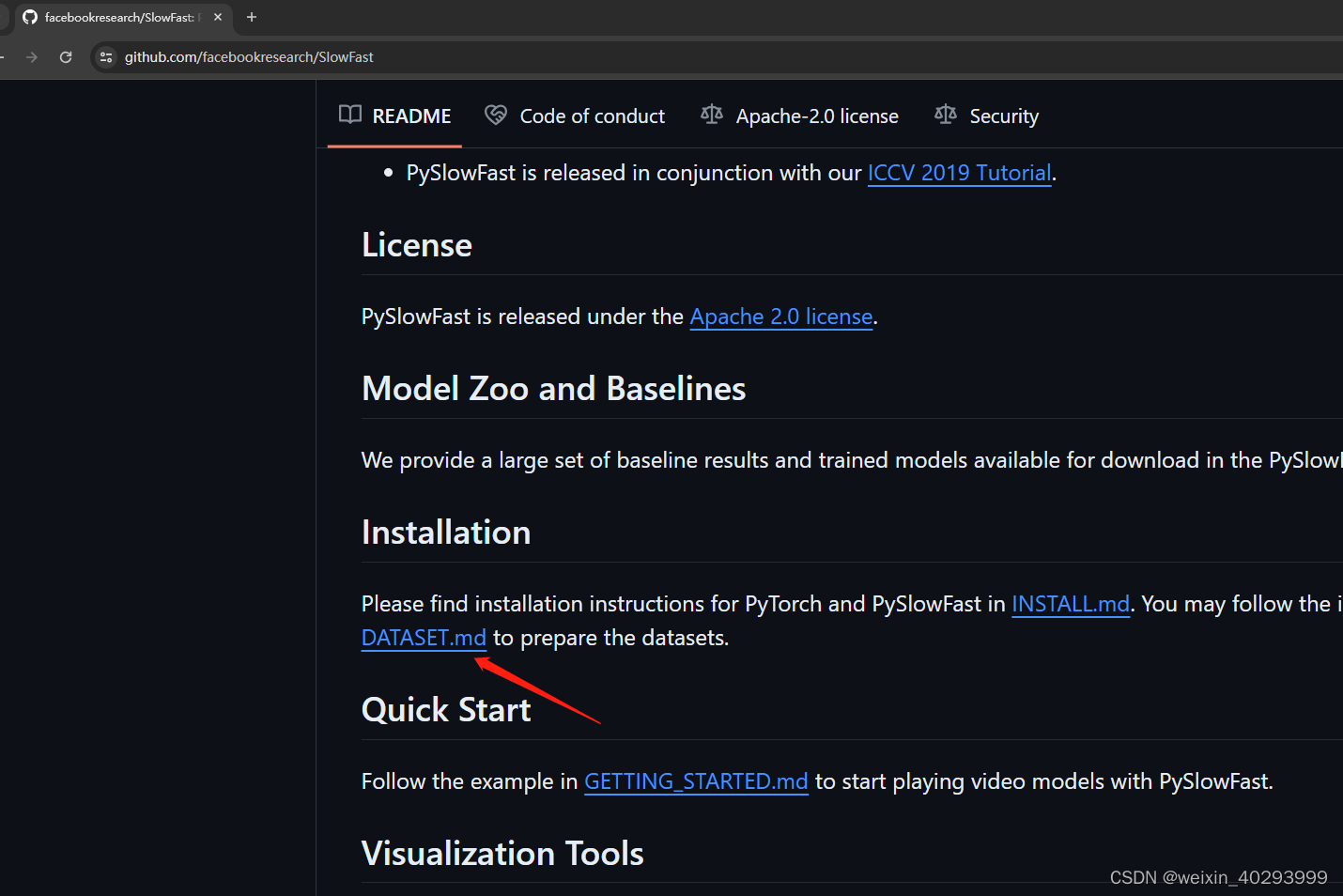
- 进入dataset:https://github.com/facebookresearch/SlowFast/blob/main/slowfast/datasets/DATASET.md
这里面的东西需要通读,但是不要过于认真,因为后面有大招!
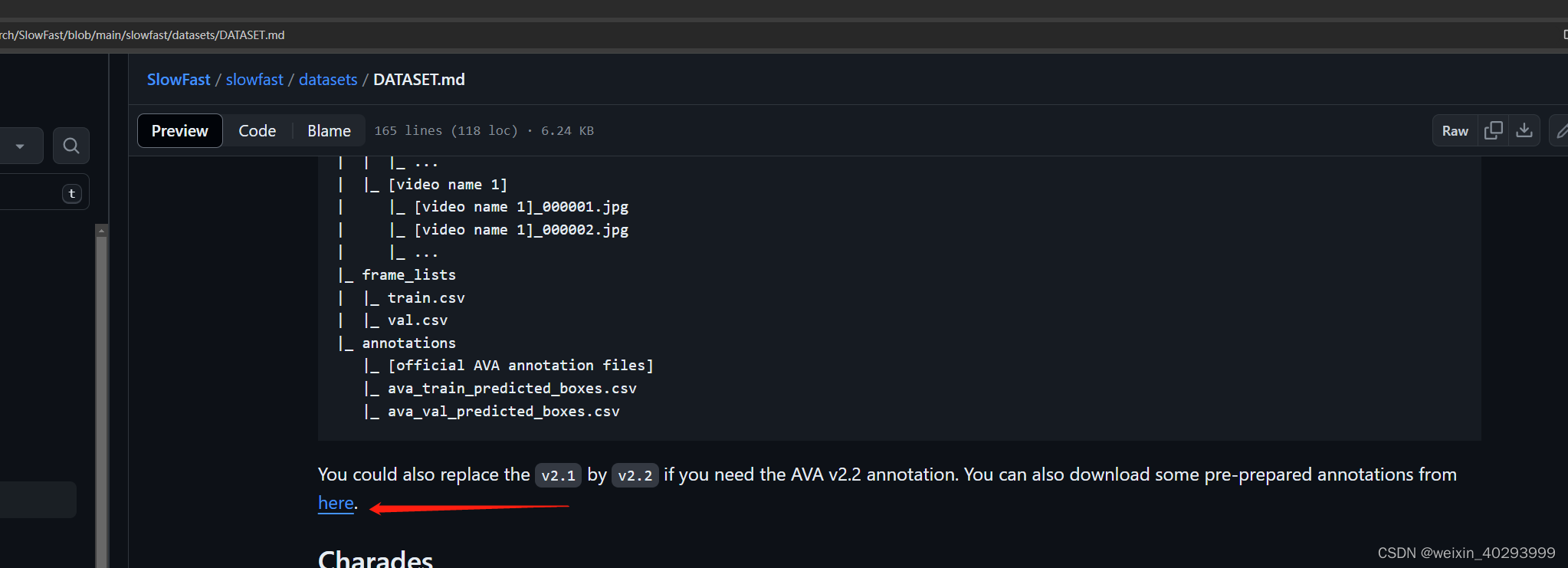
下载下来,在linux上打开,重要,因为在linux上打开是tree状的:
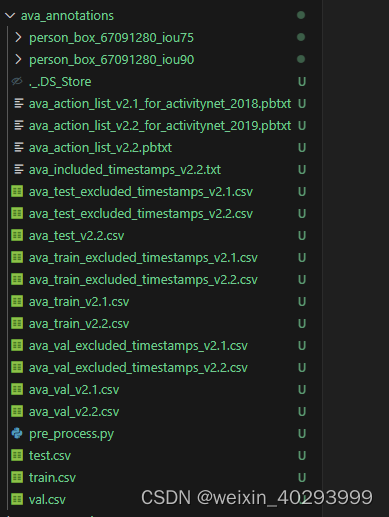
在windows上解压下来是:
!!!!!我要是现在linux上打开就好了,光挨个窜这几个文件窜了2天哎!!!!
视频在哪里,如何下载:
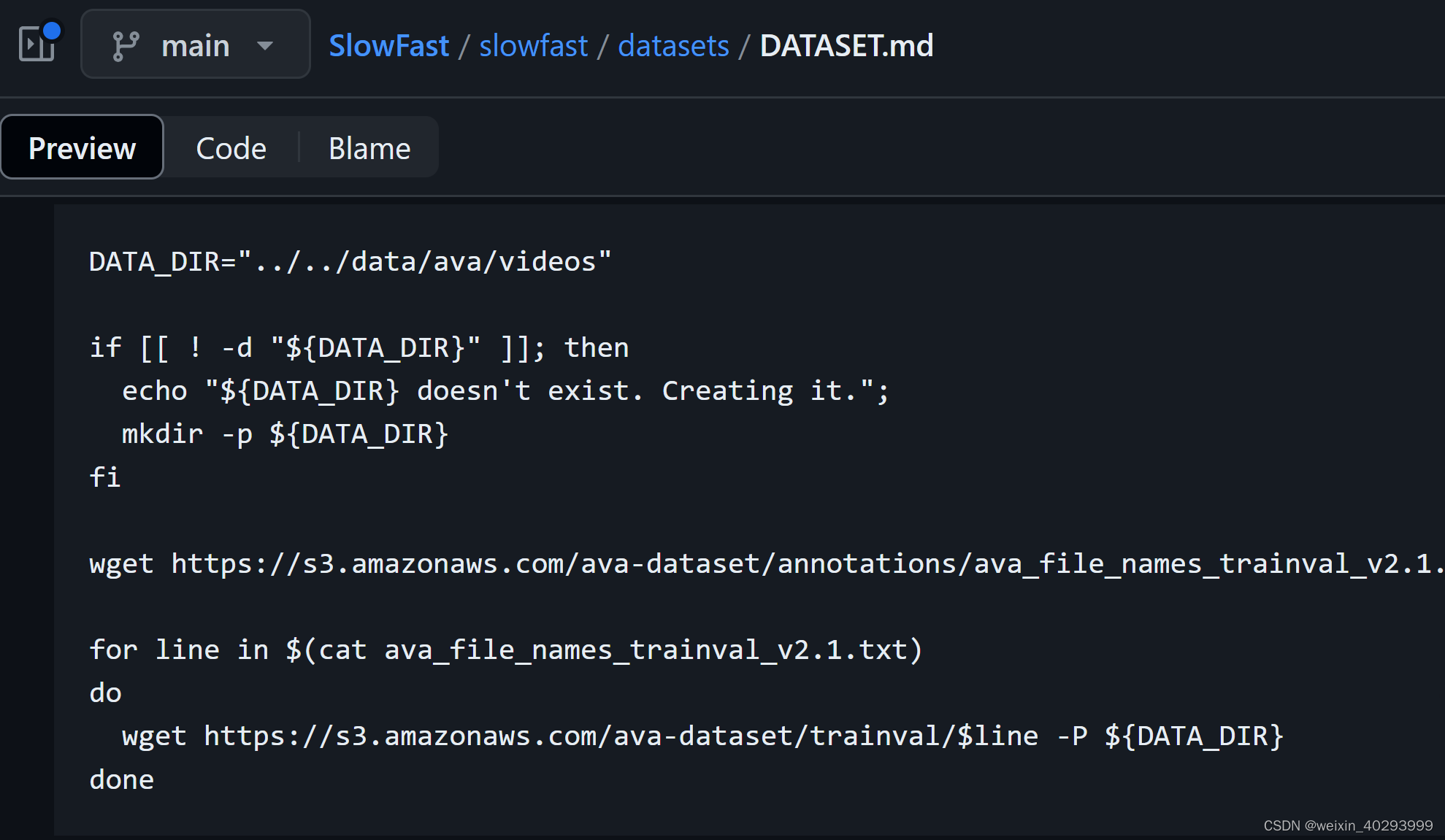
打开视频汇总的文件,挑两个下载。
我挑的是:
train:1ReZIMmD_8E
val:1j20qq1JyX4
缺点,这两个都没有 排除帧,所谓排除帧, 就是所有帧里面都是有目标的。这样的话,就会造成后面的配置文件有个别文件不起作用。谁知道哪两个文件有排除帧,欢迎评论区见。
这是之前蹿下载的代码,这是一个错误的示范,哎:
# step1 downloads 所需要的所有文件
base_path = os.path.dirname(os.path.abspath(__file__))
def download():
url_list = [
"https://research.google.com/ava/download/ava_train_v2.2.csv.zip",
"https://research.google.com/ava/download/ava_val_v2.2.csv.zip",
"https://research.google.com/ava/download/ava_test_v2.2.txt",
"https://research.google.com/ava/download/ava_action_list_v2.2_for_activitynet_2019.pbtxt",
"https://research.google.com/ava/download/ava_included_timestamps_v2.2.txt",
"https://research.google.com/ava/download/ava_train_excluded_timestamps_v2.2.csv",
"https://research.google.com/ava/download/ava_val_excluded_timestamps_v2.2.csv",
"https://research.google.com/ava/download/ava_test_excluded_timestamps_v2.2.csv",
"https://research.google.com/ava/download/ava_action_list_v2.2.pbtxt",
]
for url_path in url_list:
_,filename = os.path.split(url_path)
#response = requests.get(url_path)
temp_path = os.path.join(base_path,filename)
if os.path.exists(temp_path):
pass
else:
print(temp_path)
# if response.status_code == 200:
# with open(temp_path, "wb") as file:
# file.write(response.content)
# print("文件已成功下载到{}".format(temp_path))
# else:
# print("下载文件失败")
print("done!!!\n")
后面就是代码
将配置文件需要的文件都裁切成只包含后面这两个文件,这里面坑很多,我是试出来的,所以记录一下。
主要是采样目标后还要还原,还原的不对当下不知道,得训练的时候才知道,而且没法和原来的数据做对比。因为数据太大。直观上看不了!!!
我的预期是
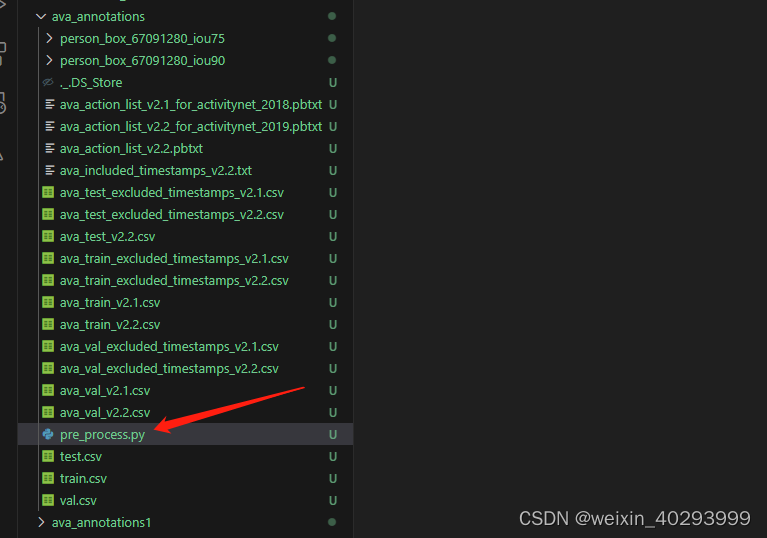
我的这个文件,能够一键生成目标数据集的配套内容。

























![[Cmake Qt]找不到文件ui_xx.h的问题?有关Qt工程的问题,看这篇文章就行了。](https://img-blog.csdnimg.cn/direct/4d470e5051ee4aa4918a1c7adee44b25.png)

![[优选算法]------滑动窗⼝——209. 长度最小的子数组](https://img-blog.csdnimg.cn/direct/93639f8c7e944aeeb463c88f768728ab.gif)