张量
- 运算与操作
加减乘除
pytorch中tensor运算逐元素进行,或者一一对应计算常用操作
典型维度为N X C X H X W,N为图像张数,C为图像通道数,HW为图高宽。
- sum()
一般,指定维度,且keepdim=True该维度上元素相加,长度变为1。 - 升降维度
unsqueeze() 扩充维度
image = PIL.Image.open('lena.jpg').convert('RGB')
transform = torchvision.tranforms.Compose([torchvision.transforms.ToTensor()])
img = transform(image)
img = img.unsqueeze(0)
sequeeze()将长度为1的维度抹除,数据不会减少。
- 将输入(图像)转换为张量,
torchvision.transforms.ToTensor()
class ToTensor:
"""Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor. This transform does not support torchscript.
- tensor转换为cvMat
- 获得元素
- 反归一化
- 变换通道顺序
- 维度展开
# 除第1维,其他维展开
x = torch.flatten(x, 1)
Variable
view()方法
卷积输出N*C*H*W,输入全连接层,需要变形为N*size
torchvision
import torchvision as tv
# 查看网络的结构
features = tv.models.alexnet().features
# 在dim=1上求和,第1维度压缩为1
torch.sum(in_feat**2,dim=1,keepdim=True)
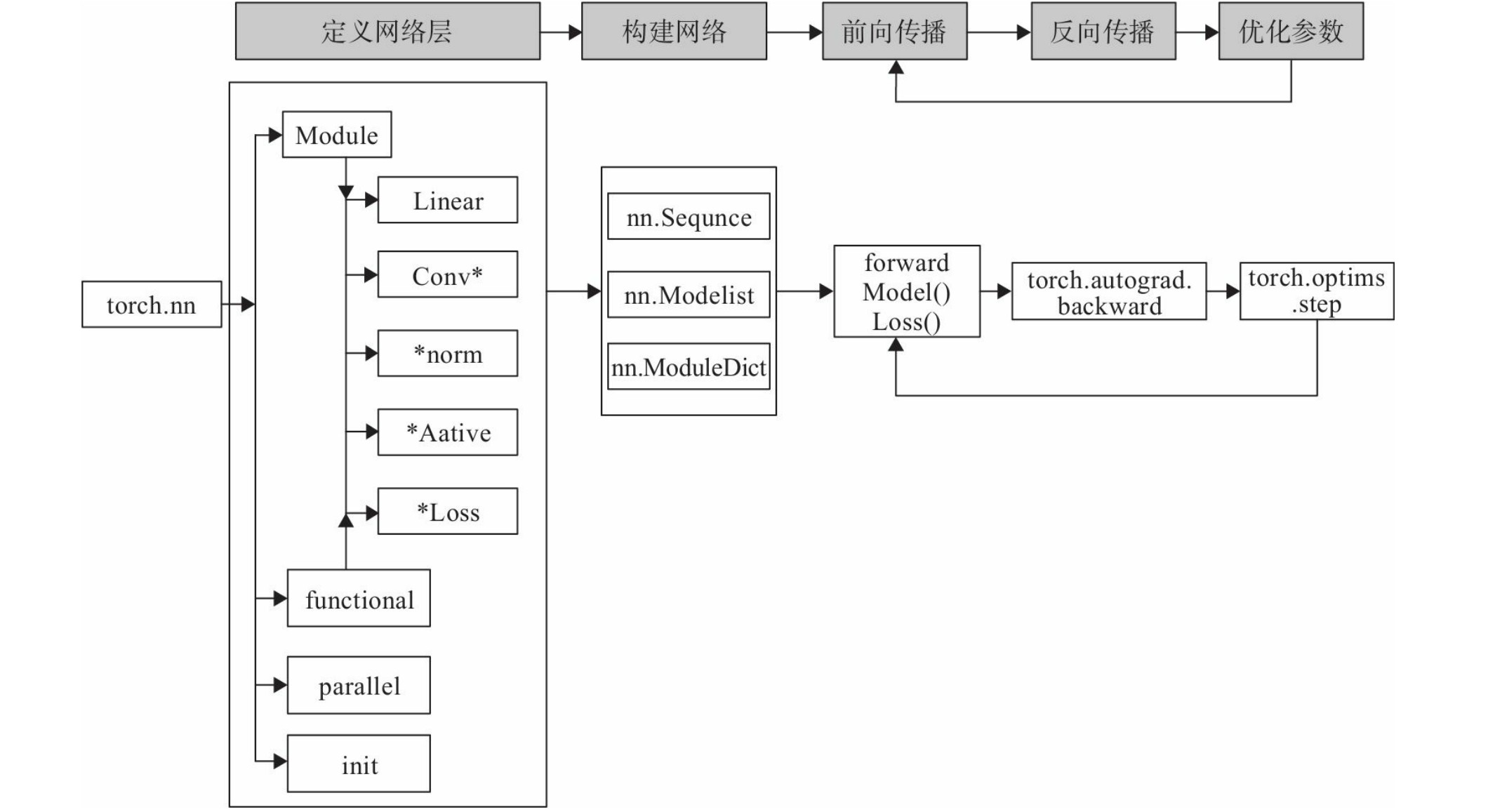
torch.nn
- Module
用于构建神经网络模型的基类,有方法
register_buffer,register_parameter,声明常量与模型参数。 - ModuleList
- train()与eval()
- ConvTranspose2d 图像反卷积,可实现上采样,如ConvTranspose2d(256, 128, 3, 2, 1, 1), 输入输出通道分别为256\128,反卷积核大小为3,反卷积的stride为2,即图像大小变为2倍,输出尺寸公式是卷积公式的逆运算;与卷积参数一致,形式即正逆。
H o u t = ( H i n − 1 ) × stride [ 0 ] − 2 × padding [ 0 ] + dilation [ 0 ] × ( kernel_size [ 0 ] − 1 ) + output_padding [ 0 ] + 1 H_{out} = (H_{in} - 1) \times \text{stride}[0] - 2 \times \text{padding}[0] + \text{dilation}[0] \times (\text{kernel\_size}[0] - 1) + \text{output\_padding}[0] + 1 Hout=(Hin−1)×stride[0]−2×padding[0]+dilation[0]×(kernel_size[0]−1)+output_padding[0]+1
- 模型参数
for key in list(para_task.keys()):
para_task[key.replace('module.', '')] = para_task.pop(key)
数据集的输入与处理
对图像预处理:https://pytorch.org/vision/stable/transforms.html
transforms.Compose()设置图像预处理模式组合,例如
train_transforms = transforms.Compose(
# [transforms.RandomCrop(args.patch_size), transforms.ToTensor()]
# [transforms.ToTensor(),]
# 图像中心裁剪边长为256像素
[transforms.CenterCrop(256), transforms.ToTensor(),]
)
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 含义为把PIL图像转换为tensor格式,
train_dataset = datasets.MNIST(root='data/',
train=True,
transform=transforms.Compose([
transforms.ToTensor(),
]),
download=True)
test_dataset = datasets.MNIST(root='data/',
train=False,
transform=transforms.Compose([
transforms.ToTensor(),
]),
download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=100, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=100, shuffle=True)
神经网络模型的构建与训练
import torch
import torchvision
from torch.autograd import Variable
# 构建网络
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv = torch.nn.Sequential(
torch.nn.Conv2d(1, 64, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.Conv2d(64, 128, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2, 2),
)
self.dense = torch.nn.Sequential(
torch.nn.Linear(14 * 14 * 128, 1024),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(1024, 10),
)
def forward(self, x):
x = self.conv(x)
x = x.view(-1, 14 * 14 * 128)
x = self.dense(x)
return x
# device
device = torch.device("cuda")
# 声明待训练的模型和优化方法
model = Model().to(device)
cost = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
# N epoch 训练
for epoch in range(epochs):
sum_loss = 0.0
train_correct = 0
for data in train_loader:
inputs, labels = data
inputs, labels = Variable(inputs).cuda(), Variable(labels).cuda()
optimizer.zero_grad()
outputs = model(inputs)
loss = cost(outputs, labels)
loss.backward()
optimizer.step()
通过pytorch.nn.module、torchvision构建的网络模型是否训练
if requires_grad: #需要训练时,设为真
for para in <torch.nn.module 对象>.parameters():
para.requires_grad = True
torch.nn.module的子类对象,如下可添加网络层数
nn.layers = nn.ModuleList()
然后把网络模型参数作为训练的优化参数
class Trainer:
def __init__(self):
self.parameters = list(<net>.parameters())
self.lr = 1e-3
self.optimizer_net = torch.optim.Adam(self.parameters,lr = self.lr)
池化
# power-2 pool of square window of size=3, stride=2
nn.LPPool2d(2, 3, stride=2)
class L2pooling(nn.Module):
def __init__(self, filter_size=5, stride=2, channels=None, pad_off=0):
super(L2pooling, self).__init__()
self.padding = (filter_size - 2) // 2
self.stride = stride
self.channels = channels
a = np.hanning(filter_size)[1:-1]
g = torch.Tensor(a[:, None] * a[None, :])
g = g / torch.sum(g)
# pdb.set_trace()
self.register_buffer(
"filter", g[None, None, :, :].repeat((self.channels, 1, 1, 1))
)
def forward(self, input):
input = input ** 2
out = F.conv2d(
input,
self.filter,
stride=self.stride,
padding=self.padding,
groups=input.shape[1],
)
return (out + 1e-12).sqrt()
错误
- 分类标签有9类,在构建数据集的标签时写为1~9,运行时错误,将标签-1解错。
- 使用list错误,pytorch无法构造tensor。
TypeError: Variable data has to be a tensor, but got list
label = np.zeros(10, dtype=np.float32) - numpy中float是双精度,pytorch变量均为单精度。
- pytorch transform必须放在Dataset对象,且库为
torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
torchvision.transforms.RandomCrop((506, 606))])
File “/home/zpk/CompressAI/iqa_models.py”, line 220, in forward
dist_s += (self.alpha0 * self.structure(mu0a, mu0b)
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
程序参数 忘记加–cuda,导致训练数据是在cpu上。RuntimeError: grad can be implicitly created only for scalar outputs
模型输出取mean()。
COCO数据集训练
使用fiftyone库实现训练。
fiftyone下载数据集在/home//fiftyone,
fiftyone/coco-2017
├── info.json
├── raw
│ ├── captions_train2017.json
│ ├── captions_val2017.json
│ ├── instances_train2017.json
│ ├── instances_val2017.json
│ ├── person_keypoints_train2017.json
│ └── person_keypoints_val2017.json
├── train
│ ├── data -> /home/zpk/Data/coco_real/train2017
│ └── labels.json
└── validation
├── data -> /home/zpk/Data/coco_real/val2017
└── labels.json
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
class FiftyOneTorchDataset(torch.utils.data.Dataset):
"""A class to construct a PyTorch dataset from a FiftyOne dataset.
Args:
fiftyone_dataset: a FiftyOne dataset or view that will be used for training or testing
transforms (None): a list of PyTorch transforms to apply to images and targets when loading
gt_field ("ground_truth"): the name of the field in fiftyone_dataset that contains the
desired labels to load
classes (None): a list of class strings that are used to define the mapping between
class names and indices. If None, it will use all classes present in the given fiftyone_dataset.
"""
def __init__(
self,
fiftyone_dataset,
transforms=None,
gt_field="ground_truth",
classes=None,
):
self.samples = fiftyone_dataset
self.transforms = transforms
self.gt_field = gt_field
self.img_paths = self.samples.values("filepath")
self.classes = classes
if not self.classes:
# Get list of distinct labels that exist in the view
self.classes = self.samples.distinct(
"%s.detections.label" % gt_field
)
if self.classes[0] != "background":
self.classes = ["background"] + self.classes
self.labels_map_rev = {c: i for i, c in enumerate(self.classes)}
def __getitem__(self, idx):
img_path = self.img_paths[idx]
sample = self.samples[img_path]
metadata = sample.metadata
img = Image.open(img_path).convert("RGB")
boxes = []
labels = []
area = []
iscrowd = []
detections = sample[self.gt_field].detections
for det in detections:
category_id = self.labels_map_rev[det.label]
coco_obj = fouc.COCOObject.from_label(
det, metadata, category_id=category_id,
)
x, y, w, h = coco_obj.bbox
boxes.append([x, y, x + w, y + h])
labels.append(coco_obj.category_id)
area.append(coco_obj.area)
iscrowd.append(coco_obj.iscrowd)
target = {}
target["boxes"] = torch.as_tensor(boxes, dtype=torch.float32)
target["labels"] = torch.as_tensor(labels, dtype=torch.int64)
target["image_id"] = torch.as_tensor([idx])
target["area"] = torch.as_tensor(area, dtype=torch.float32)
target["iscrowd"] = torch.as_tensor(iscrowd, dtype=torch.int64)
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.img_paths)
def get_classes(self):
return self.classes
fo_dataset = foz.load_zoo_dataset("coco-2017", split = "train")
dataset_dir = "/path/to/coco-2017"
# The type of the dataset being imported
dataset_type = fo.types.COCODetectionDataset # for example
dataset = fo.Dataset.from_dir(
dataset_dir=dataset_dir,
dataset_type=dataset_type,
name=name,
)
valid_view = fo_dataset.match(F("ground_truth.detections").length() > 1)
torch_dataset = FiftyOneTorchDataset(valid_view)