作者介绍:10年大厂数据\经营分析经验,现任大厂数据部门负责人。
会一些的技术:数据分析、算法、SQL、大数据相关、python
欢迎加入社区:码上找工作
作者专栏每日更新:
LeetCode解锁1000题: 打怪升级之旅
python数据分析可视化:企业实战案例
题目描述
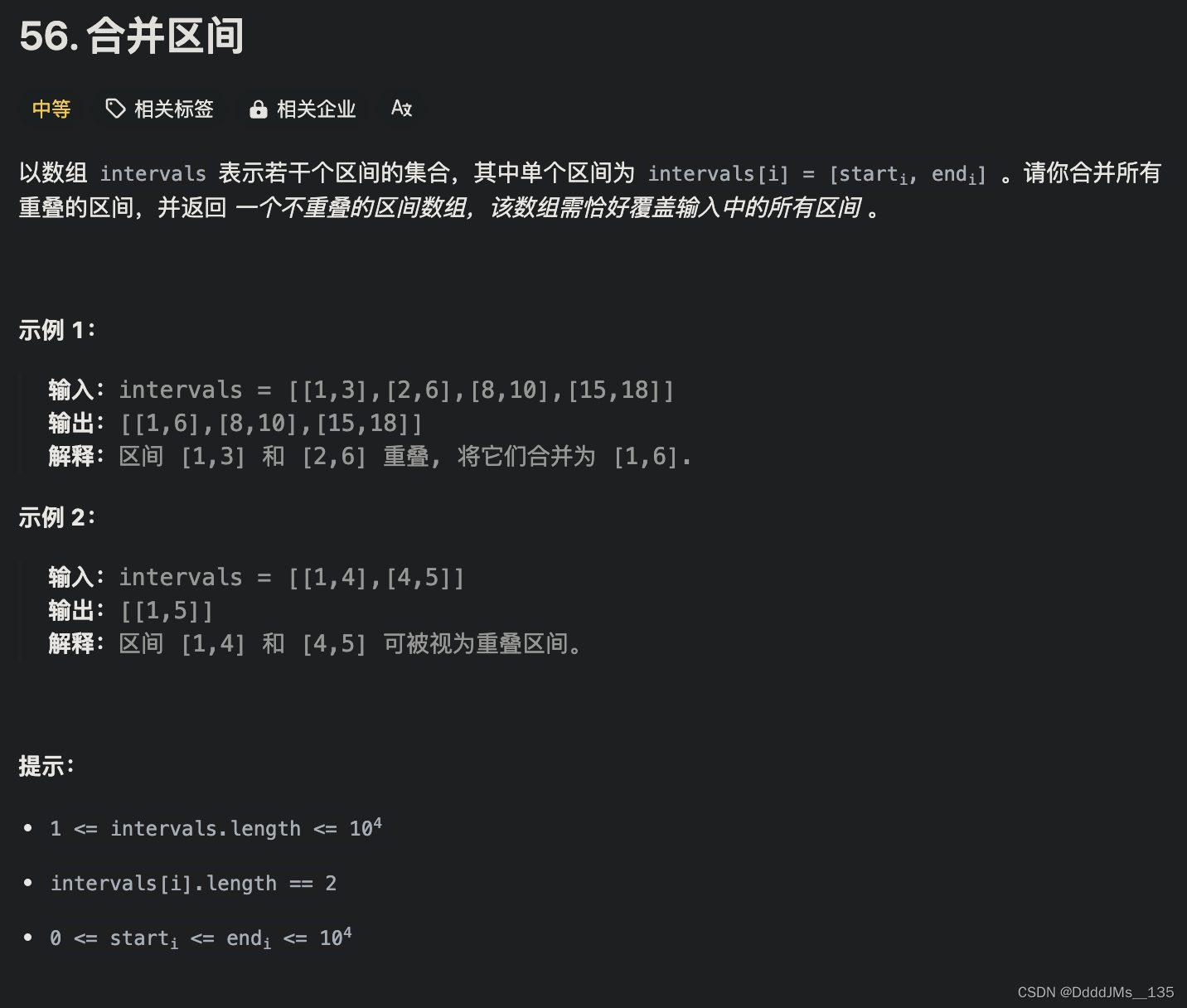
给出一个区间的集合,请合并所有重叠的区间。
输入格式
- intervals:一个二维整数数组,每个子数组包含两个整数,表示一个区间的起始和结束位置。
输出格式
- 返回一个二维整数数组,表示合并后的区间。
示例
示例 1
输入: intervals = [[1,3],[2,6],[8,10],[15,18]]
输出: [[1,6],[8,10],[15,18]]
解释: 区间 [1,3] 和 [2,6] 发生重叠,合并成 [1,6].
示例 2
输入: intervals = [[1,4],[4,5]]
输出: [[1,5]]
解释: 区间 [1,4] 和 [4,5] 可被视为重叠区间。
方法一:排序后合并
解题步骤
- 排序:先按每个区间的起始位置进行排序。
- 初始化:用一个新列表
merged来存储最终合并后的区间。 - 合并区间:遍历排序后的区间列表,如果
merged为空或者当前区间与merged中最后一个区间不重叠,直接添加到merged;否则,将当前区间与merged中最后一个区间进行合并。
完整的规范代码
def merge(intervals):
"""
使用排序后合并的方法合并区间
:param intervals: List[List[int]], 输入的区间列表
:return: List[List[int]], 合并后的区间列表
"""
intervals.sort(key=lambda x: x[0]) # 按区间起点进行排序
merged = []
for interval in intervals:
# 如果列表为空,或当前区间与上一区间不重叠,直接添加
if not merged or merged[-1][1] < interval[0]:
merged.append(interval)
else:
# 否则,有重叠,进行合并
merged[-1][1] = max(merged[-1][1], interval[1])
return merged
# 示例调用
print(merge([[1,3],[2,6],[8,10],[15,18]])) # 输出: [[1,6],[8,10],[15,18]]
print(merge([[1,4],[4,5]])) # 输出: [[1,5]]
算法分析
- 时间复杂度:(O(n log n)),其中
n是区间的数量。主要耗时操作是排序。 - 空间复杂度:(O(log n)) 或 (O(n)),取决于所使用的排序算法。
方法二:扫描线算法
解题步骤
- 创建事件:对于每个区间 [a, b],创建两个事件:(a, ‘start’) 和 (b, ‘end’)。
- 排序事件:按照时间点排序这些事件,如果时间点相同,则 ‘end’ 事件在 ‘start’ 事件之前。
- 扫描处理:扫描排序后的事件列表,使用计数器记录开启的区间数量,根据区间的开启和结束更新合并区间的列表。
完整的规范代码
def merge(intervals):
"""
使用扫描线算法合并区间
:param intervals: List[List[int]], 输入的区间列表
:return: List[List[int]], 合并后的区间列表
"""
events = [] # 事件列表
for start, end in intervals:
events.append((start, 'start'))
events.append((end, 'end'))
# 事件排序,结束事件优先于开始事件
events.sort(key=lambda x: (x[0], x[1] == 'start'))
merged = []
ongoing = 0 # 当前开启的区间数
for time, typ in events:
if typ == 'start':
if ongoing == 0: # 新的区间开始
start = time
ongoing += 1
elif typ == 'end':
ongoing -= 1
if ongoing == 0: # 区间结束
merged.append([start, time])
return merged
# 示例调用
print(merge([[1,3],[2,6],[8,10],[15,18]])) # 输出: [[1,6],[8,10],[15,18]]
print(merge([[1,4],[4,5]])) # 输出: [[1,5]]
算法分析
- 时间复杂度:(O(n log n)),主要耗时在于事件排序。
- 空间复杂度:(O(n)),用于存储事件。
方法三:动态规划
动态规划方法不是本问题的最优解法,而且实现复杂度高,故不推荐使用。在实际应用中,方法一和方法二已足够解决大多数情况。
不同算法的优劣势对比
| 特征 | 方法一: 排序后合并 | 方法二: 扫描线算法 |
|---|---|---|
| 时间复杂度 | (O(n \log n)) | (O(n \log n)) |
| 空间复杂度 | (O(\log n)) 或 (O(n)) | (O(n)) |
| 优势 | 简单直观,易于实现 | 处理复杂情况更高效,适用于区间边界频繁变动的场景 |
| 劣势 | 空间复杂度依赖排序算法 | 实现相对复杂,需要处理多种事件排序逻辑 |
确保会议室的使用时间不冲突。以下是如何将区间合并算法应用于会议室预订系统的详细解析:
应用场景:会议室预订系统
场景描述:
- 一个公司有多个会议室,员工需要预订会议室进行会议。
- 员工通过系统输入会议的开始和结束时间,系统需要自动显示可用的会议室或者提示时间冲突。
技术实现:
- 当员工提交一次会议室预订请求时,系统将这个新的时间区间与已存在的预订记录进行比对。
- 使用区间合并算法来确定是否存在时间上的重叠,从而判断是否可以接受新的预订。
代码示例:
假设我们已经有一些预定记录,现在需要处理新的预定请求。
def merge(intervals):
intervals.sort(key=lambda x: x[0]) # 按区间起点进行排序
merged = []
for interval in intervals:
if not merged or merged[-1][1] < interval[0]:
merged.append(interval)
else:
merged[-1][1] = max(merged[-1][1], interval[1])
return merged
# 已存在的会议预订记录
existing_bookings = [[9, 12], [14, 17], [21, 23]]
# 新的会议请求
new_meeting = [13, 15]
# 检查新的会议是否可以安排
combined_bookings = existing_bookings + [new_meeting]
merged_bookings = merge(combined_bookings)
if len(merged_bookings) != len(existing_bookings) + 1:
print("新会议请求与现有会议时间冲突,无法预订。")
else:
print("新会议请求成功预订。")
existing_bookings = merged_bookings # 更新现有预订记录
print("当前会议室预订情况:", merged_bookings)
输出解析:
- 程序首先将新的会议请求加入到已有的会议记录中。
- 通过
merge函数处理合并后的区间。 - 如果合并前后的记录数量不变,说明新会议未与现有会议重叠,预订成功;否则,表示时间冲突。
应用二:动态时间表的优化管理
场景描述:
- 在动态时间表管理,如交通工具的时刻表调整或电视节目的排版中,需要不断调整活动时间以优化整体使用效率或观看率。
技术实现:
- 利用区间合并算法可以实时调整和优化时间表,合并重叠的或连续的活动区间,减少空闲时间,增加资源使用效率。
代码示例:
假设有一个初步的活动时间表,需要进行优化合并。
activities = [[10, 12], [11, 13], [12, 15], [17, 19]]
# 使用区间合并算法优化活动时间表
optimized_activities = merge(activities)
print("优化后的活动时间表:", optimized_activities)
输出解析:
- 此示例中,活动时间表通过合并重叠的时间区间来优化,减少了时间段的碎片化,提高了时间资源的利用率。
总结
通过上述应用示例,我们可以看到区间合并算法不仅限于理论问题,而是可以广泛应用于实际项目中,如会议室预订系统和时间表管理等,帮助开发者和组织有效地管理和优化时间资源。这种算法的实际应用突出了它在现代编程中的实用价值和广泛适用性。