事务
数据库的事务是一种机制,一种操作序列,包含了一组数据库的操作命令
简单了解:如果一个包含多个步骤的业务操作,被业务管理,要么这些操作同时操作成功,要么同时操作失败
事务是一个不可分割的工作逻辑单元,可以在事务中写多种sql语句
MYSQL的事务机制
1.自动提交(默认)
每执行一行SQL语句,就开启一个事务,SQL提交完成,事务提交(一行SQL一个事务)
2.手动提交(自己写代码)
先开启事务,在执行多条SQL语句,提交事务(回滚)
事务的使用操作机制
1.开启事务
START TRANSACTION
2.执行多行sql语句
COMMIT
3.提交事务(成功) | 回滚事务(失败)
ROLLBACK
create table people
(
id int primary key auto_increment,
name varchar(10),
money int
);
insert into mysql_day2.people (id, name,money) VALUE (null,'小何',1000),(null,'小美',500);
-- 1.开启事务
start transaction;
-- 2.转账
update people set money=money-500 where name ='小何';
update people set money=money+500 where name ='小美';
-- 3.提交事务,不提交不改变
commit ;
-- 3.回滚事务(回到原来的情况)
rollback;
事务的四大特性(ACID)
1.持久性(Durability)
当事务提交或回滚后,数据库会持久化的保存数据
2.隔离性(Isolation)
多个用户并发的访问数据库时,一个用户的事务不能被其他用户的事务干扰,多个并发的事务之间相互隔离
3.原子性(Atomicity)
原子是不可分割的最小操作单位,事务要么同时成功,要么同时失败
4.一致性(Consistency)
事务操作前后,数据总量不变
事务的隔离级别
事务在操作时的理想状态,多个事务之间相互不影响,如果隔离级别设置不当就可能引发1并发访问问题,一个事务就相当与一个线程
| 并发访问的问题 | 含义 |
| 脏读 | 一个事务读取到了另一个事务尚未提交的数据 |
| 不可重复读 | 一个事务多次读取时数据是不一致的,这是其他事务update时引发的问题(已经commit) |
| 幻读(虚读) | 一个事务内读取到别的事务插入或删除的数据(别的事务commit后),导致前后读取记录行数不同,这是insert和delete时引发的问题 |
因此MYSQL数据库规范规定了4种隔离级别,用于解决上述出现的事务并发问题
| 级别 | 名字 | 隔离级别 | 脏读 | 不可重复读 | 幻读 | 数据库默认隔离级别 |
| 1 | 读未提交 | read uncommited | 是 | 是 | 是 | |
| 2 | 读已提交 | read commited | 否 | 是 | 是 | Oracle,SQL server |
| 3 | 可重复读 | repeatable read | 否 | 否 | 是 | MySQL |
| 4 | 串行化(相当与单线程) | serializable | 否 | 否 | 否 |
函数
日期函数
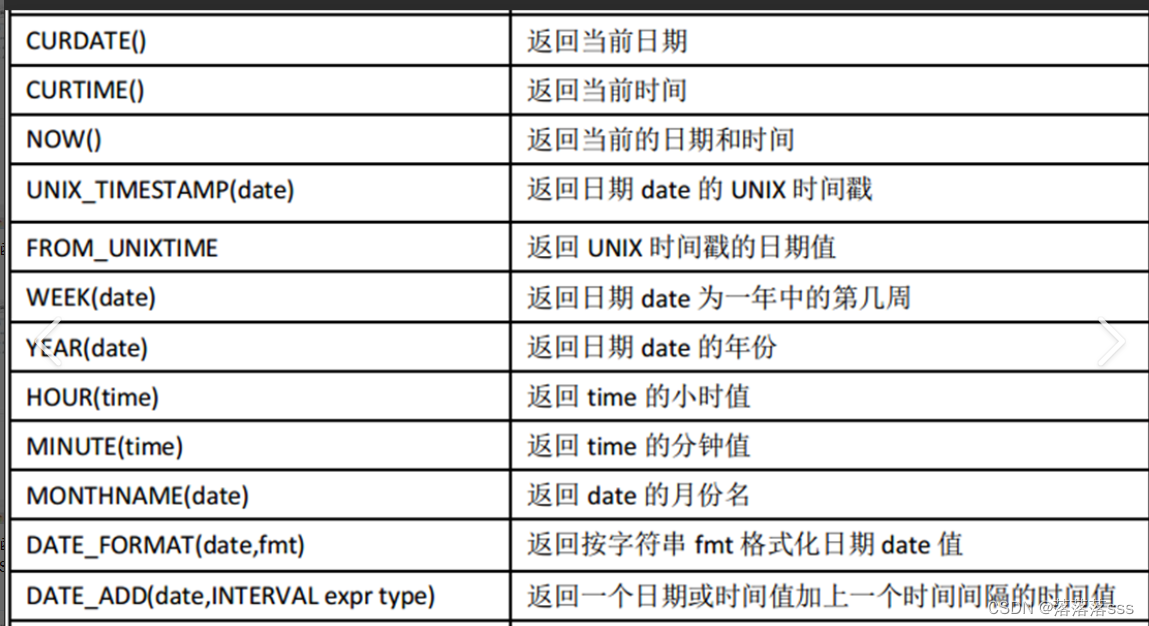
-- 获得系统当前的日期和时间
select now();
-- 获取系统当前的日期
select curdate();
-- 获取系统当前的时间
select curtime();
create table people
(
id int primary key auto_increment,
name varchar(10),
birthday date
);
insert into people (id, name, birthday) VALUE (null,'aaa',curdate());
-- 获取年月日
select year(curdate());
select month(curdate());
select day(curdate());
-- 获取一年的第几周
select week(curdate());
-- 获取学生的生日日期(不包括年)
select name,month(birthday),day(birthday) from people;
-- 把月日连在一起,使用函数concat()
select name,concat(month(birthday),'月',day(birthday),'日') from people;select name,month(birthday),day(birthday) from people;的结果

select name,concat(month(birthday),'月',day(birthday),'日') from people;的结果

判断函数:casewhen
语法
case 列
when 条件一 then 结果一
when 条件二 then 结果二
....
else
结果N
end;
如果没有写else且不满足上述条件返回null
create table people2
(
id int primary key auto_increment,
name varchar(10) not null unique,
sex int default 0
);
insert into people2 values(null,'aaa',1),(null,'bbb',1),(null,'ccc',2),(null,'ddd',1);
select id, name,
case sex
when 1 then '男'
when 2 then '女'
else '保密'
end AS gender
from people2; 
字符函数
-- 获取字符串长度
select char_length('iamyou');
select char_length(name) from people2; 
-- 拼接字符串
select concat('i','love','you');
select concat(id,'号',name) from people2;
-- 转大小写
select lower('IAM');
select upper('yyy');
select concat(id,'号',upper(name)) from people2;
-- 截取字符串
select substr('iamhhhh',4,4);-- 索引从1开始,从四位置开始截取长度为4的字符串,结果是hhhh
-- 去除字符串的前后空格,中间空格不会去除
select trim(' iam y ');-- iam y数学函数
-- 从0到1取一个随机数
select rand();
-- 四舍五入保留几位小数
select round(3.123445,3);
-- 不四舍五入保留几位小数
select truncate(3.12342,2);
-- 获取最小值
select least(1,2,3);-- 1
-- 获取最大值
select greatest(1,2,3);-- 3索引
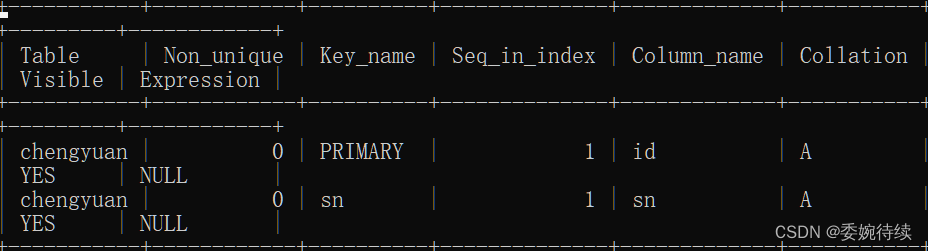
索引是帮助MySQL高效获取数据的数据结构(B+树)
索引是创建在表中的某些列种
创建索引语法
1)创建索引
1.创建普通索引
create index 索引名 on 表名(字段);
2.创建唯一索引
create unique index 索引名 on 表名(字段);
3.创建普通组合索引
create index 索引名 on 表名(字段1,字段名2...);
4.创建唯一组合索引
create unique index 索引吗 on 表名(字段名1,字段名2...);
注意:
1.如果在一张表中创建多个索引,要保证索引名是不能重复的
2.主键索引 primary key 无法通过此方式创建
主键索引,默认在创建表时指定主键列(primary key),就自动添加了
2)在已有表的字段上修改表时指定
1.添加一个主键,这意味着索引值必须是唯一的,且不为null
alter table 表名 primary key(字段)--默认索引名:primary
2.添加唯一索引(除了null可以出现多次)
alter table add unique (字段);--默认索引名:字段名
3.添加普通索引,索引值可以出现多次
alter table 表名 add index(字段);-- 默认索引吗:字段名
create table people3
(
id int primary key auto_increment,-- 主键索引
tel varchar(20) unique,-- 唯一索引
name varchar(10)
);
-- 给名字字段添加普通索引
create index idx_people3_name on people3(name);索引的数据结构
B+Tree:
B+Tree将树分为叶子节点和非叶子节点,其中非叶子节点只存储索引+指针,而叶子节点存储索引+数据。
创建索引的原则
1.字段内容的可识别度不能低于70%,字段内数据唯一值的个数不能低于70%,如age字段,不同的内容就有很多,而sex(性别)的内容就只有两种,不适合创建索引
2.经常使用where条件搜索的字段,例如id,name字段
3.经常使用表连接的字段(内连接,外连接),可以加快连接的速度
4.经常排序的字段 order by ,因为索引已经排序过。
索引失效
- 模糊查询(like)走的是表查询(一个一个查),索引失效
- 在索引列上进行运算操作(函数),索引失效
- 范围查询右边的列,不能使用索引
- 字符串不加单引号,索引失效
- 用or分割开的条件,如果or前的条件的列有索引,or后面的列没有索引,那么涉及的索引都不会用到
- is null,is not null有时索引失效
- in走索引,not in 索引失效