爬虫,也称为网络爬虫或网络蜘蛛,是一种自动化程序,专门用于遍历互联网并收集数据。这种技术的起源、发展和未来都与互联网紧密相连,并在信息检索、数据挖掘等多个领域发挥着不可或缺的作用。
"免费IP池大放送!助力您的数据采集之旅,我们是您最佳的数据采集搭档。高质量、稳定、免费的IP资源等您来拿,让数据采集变得更加高效、轻松!赶快行动吧,与我们携手,共创数据采集新篇章!"赶紧行动起来吧!
目录

Python爬虫入门指南:从爬虫的由来到实战应用
🏆 学习重点提前知
- 理解爬虫的概念及其由来。
- 掌握网络传输协议(主要为HTTP协议和HTTPS协议)。
- 掌握爬虫的工作机制。
✨ 一. 爬虫的由来和编写语言
🌲 1. 何为爬虫
爬虫,即网络爬虫,是自动化抓取互联网信息的程序。它按照设定的规则,自动下载和分析网页,提取所需数据。爬虫广泛应用于搜索引擎、数据挖掘、自然语言处理等领域,但使用时需遵守法律和伦理规范。
爬虫,也称为网络爬虫或网络蜘蛛,是一种自动化程序,专门用于遍历互联网并收集数据。这种技术的起源、发展和未来都与互联网紧密相连,并在信息检索、数据挖掘等多个领域发挥着不可或缺的作用。
🌲 2. 爬虫的起源与早期应用
爬虫技术的起源可以追溯到互联网发展的早期,当时随着网页数量的激增,用户急需一种能够快速检索信息的方法。搜索引擎应运而生,它们的核心技术之一就是爬虫。从一个或多个初始网页的URL开始,爬虫能够获取这些网页的内容,并分析提取其中的链接,然后继续访问这些新链接,如此循环往复,从而实现对互联网信息的自动收集和索引。
🌲 3. 爬虫的发展与演进
随着互联网技术的不断进步,爬虫也在不断发展。最初的爬虫主要用于搜索引擎的网页索引,但很快就扩展到其他领域,如数据挖掘、价格监测和竞品分析。现代爬虫已经能够处理动态网页、解析JavaScript渲染的内容,甚至模拟用户行为以绕过反爬机制。
🌲 4. Python语言对爬虫的重要性
Python因其简单易学、丰富的库资源和跨平台特性,成为爬虫开发的首选语言。其简洁的语法和强大的爬虫生态系统大大降低了开发难度。
🌲 5. 爬虫的未来展望
展望未来,随着互联网和人工智能技术的不断发展,爬虫将继续发挥重要作用。预计爬虫将变得更加智能化和自适应化,能够自动识别和绕过各种反爬机制,提高数据抓取的效率和准确性。同时,爬虫将与自然语言处理、机器学习等技术相结合,实现更高级别的数据分析和处理功能,为各行各业提供更强大的数据支持。
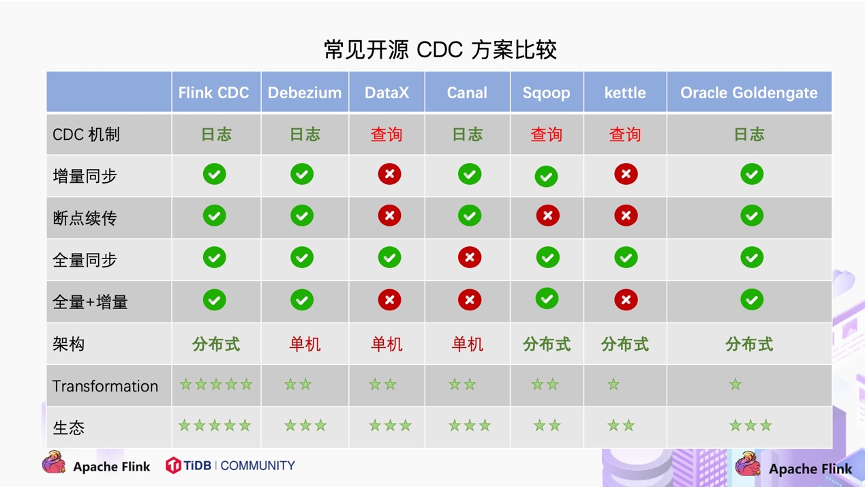
✨ 二. 网络传输协议
🌲 1. HTTP协议
HTTP是超文本传输协议,用于在互联网上传输超媒体信息。它基于客户端-服务端模型,请求由客户端发起,服务端响应。HTTP请求包含请求行、请求头和请求体;响应包含状态行、响应头和响应体。
🌲 2. HTTPS协议
HTTPS是HTTP的安全版本,通过SSL/TLS协议加密传输数据,保证数据的安全性和完整性。HTTPS广泛应用于需要安全传输信息的场景,如金融、电商等。
🌲 3. 返回的状态码意义
HTTP状态码表示服务器对客户端请求的响应状态。如200表示成功,404表示未找到,500表示服务器内部错误等。了解这些状态码有助于排查网络请求中的问题。
✨ 三. 学会使用抓包工具
推荐使用Chrome浏览器的开发者工具进行抓包分析。它可以方便地查看网页源码、分析HTTP请求等,对于爬虫开发非常有用。此外,还可以利用Chrome插件和Selenium等自动化测试工具辅助爬虫开发,同时可以使用。

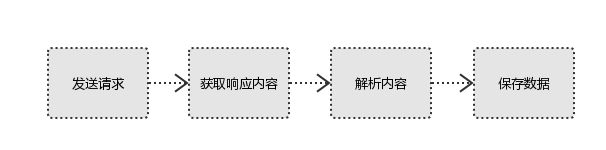
✨ 四. 爬虫的机制
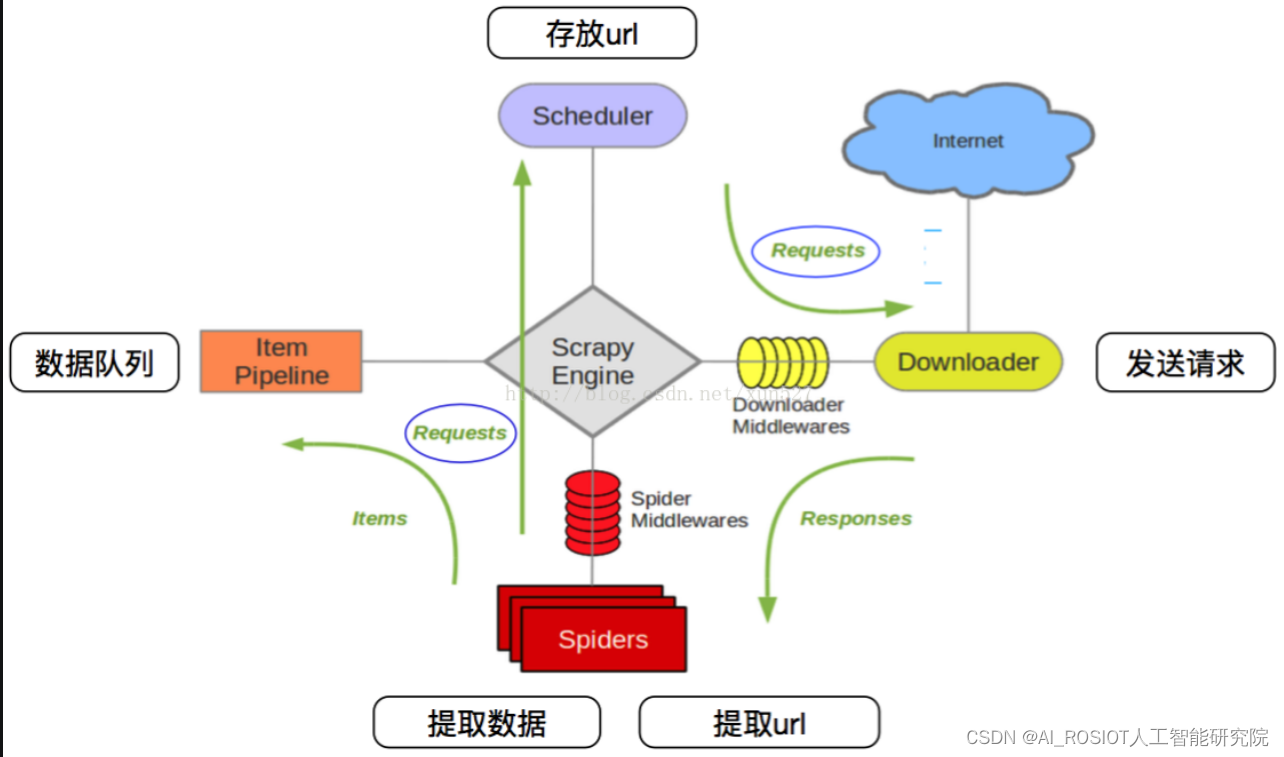
- 确定爬取目标:明确要爬取的网站、数据类型和数据范围。
- 发起请求:使用HTTP或HTTPS协议向目标网站发起请求,获取HTML文档。
- 解析HTML:利用解析库(如BeautifulSoup)提取所需数据。
- 处理数据:对数据进行清洗、转换和存储等操作。
- 应对反爬措施:设置合适的请求头、使用代理等方法规避反爬策略。
- 定时任务:定期监测和更新目标网站数据,确保数据的实时性和准确性。
如下图以爬取京东商品为例的爬虫设计流程:

✨ 五. 爬虫实战应用 (此部分可根据需要添加具体实例)
通过实际案例介绍如何使用Python和相关库进行爬虫开发,包括但不限于requests库发起请求、BeautifulSoup库解析HTML等。
🌲 1. 爬取豆瓣电影排行榜Top 250数据
爬取豆瓣电影排行榜Top 250并将数据存储到Excel文件是一个涉及网络爬虫和数据处理的任务。以下是一个基本的步骤指南,以及一个简化的Python代码示例,用于完成此任务。
步骤指南
- 分析豆瓣电影Top 250的网页结构:
- 打开豆瓣电影Top 250的网页,检查其HTML结构,特别是电影信息的定位。
- 确定需要爬取的信息,如电影名称、导演、主演、评分等。
- 编写爬虫代码:
- 使用Python的
requests库来发送HTTP请求获取网页内容。 - 使用
BeautifulSoup库来解析HTML并提取所需信息。 - 处理分页问题,因为豆瓣电影Top 250通常分布在多个页面上。
- 使用Python的
- 存储数据到Excel:
- 使用
pandas库来管理和处理数据。 - 创建一个DataFrame来存储爬取的电影信息。
- 使用
pandas的to_excel函数将数据保存到Excel文件中。
- 使用
- 处理反爬虫机制:
- 豆瓣可能有反爬虫机制,如请求频率限制、验证码等。
- 在代码中添加适当的延时、使用代理或调整请求头以模拟正常用户行为。
- 测试和优化:
- 在小规模数据上测试爬虫代码,确保其正常工作。
- 根据需要优化代码性能和稳定性。
代码编写
下面是一个简化的Python代码示例,用于爬取豆瓣电影Top 250的基本信息并存储到Excel文件中。请注意,这只是一个基础示例,可能需要根据豆瓣网站的当前结构和反爬虫策略进行调整。
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
# 初始化一个空的DataFrame来存储数据
movies_df = pd.DataFrame(columns=['排名', '电影名', '导演', '主演', '年份', '国家', '类型', '评分', '评价人数', '引言'])
# 设置请求头以模拟浏览器行为
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
}
# 豆瓣电影Top 250的基础URL
base_url = 'https://movie.douban.com/top250?start={}&filter='
# 循环爬取每一页的数据
for start in range(0, 250, 25): # 豆瓣电影Top 250每页显示25部电影
url = base_url.format(start)
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取电影条目列表
movie_list = soup.find_all('div', class_='item')
for movie in movie_list:
# 提取电影的详细信息,这里只提取了部分信息作为示例
rank = movie.find('em').get_text() # 排名
title = movie.find('span', class_='title').get_text() # 电影名
info = movie.find('p').get_text().strip() # 其他信息(导演、主演等)
# ... 这里可以继续提取其他所需信息,如评分、评价人数等
# 将提取的信息添加到DataFrame中
movies_df = movies_df.append({'排名': rank, '电影名': title, '其他信息': info}, ignore_index=True)
# 设置延时以避免被豆瓣封锁IP或触发验证码等反爬虫机制
time.sleep(5)
# 将DataFrame保存到Excel文件中
movies_df.to_excel('douban_top250_movies.xlsx', index=False)
重要提示:在实际使用中,请确保遵守豆瓣的使用条款和政策,不要频繁或大量地发送请求,以免对豆瓣服务器造成不必要的负担或触发反爬虫机制。此外,随着豆瓣网站的更新,上述代码可能需要进行相应的调整。

🌲 2. 爬取斗鱼直播照片保存到本地目录
爬取斗鱼直播的照片并保存到本地目录涉及几个关键步骤。但首先,我必须强调,任何形式的网络爬虫活动都应该遵守目标网站的robots.txt文件规定,并尊重版权和隐私。在未经许可的情况下下载和使用他人的照片可能是违法的。
假设你已经获得了必要的权限,并且斗鱼直播的照片是公开可访问的,以下是一个基本的步骤指南和示例代码:
步骤指南
- 分析斗鱼直播的网页结构:
- 打开斗鱼直播的网页,检查其HTML结构,特别是照片或图片链接的定位。
- 确定照片或图片的URL格式。
- 编写爬虫代码:
- 使用Python的
requests库或类似的库来发送HTTP请求获取网页内容。 - 使用
BeautifulSoup库或类似的库来解析HTML并提取照片或图片的URL。
- 使用Python的
- 下载照片:
- 对提取出的每个照片URL,再次使用
requests库来下载照片内容。 - 确保将HTTP响应的内容保存为图片文件,如
.jpg或.png。
- 对提取出的每个照片URL,再次使用
- 保存到本地目录:
- 指定一个本地目录来保存下载的照片。
- 使用Python的文件操作功能将下载的照片写入到该目录中。
- 处理异常和错误:
- 添加适当的异常处理来确保代码的健壮性,例如处理网络请求失败、文件写入错误等。
示例代码
以下是一个简化的Python代码示例,用于从斗鱼直播网页中提取照片URL并下载保存到本地目录。请注意,这个示例是假设性的,并且可能需要根据斗鱼直播网站的实际结构进行调整。
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
# 设置请求头以模拟浏览器行为
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
}
# 斗鱼直播的URL(示例)
url = 'https://www.douyu.com/some_channel' # 请替换为实际的斗鱼直播URL
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取图片URL(这取决于斗鱼直播的实际HTML结构)
img_elements = soup.find_all('img') # 根据实际情况调整选择器
image_urls = [urljoin(url, img['src']) for img in img_elements]
# 设置保存照片的本地目录
save_dir = 'douyu_photos'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 下载并保存照片
for idx, image_url in enumerate(image_urls):
response = requests.get(image_url, headers=headers)
if response.status_code == 200:
# 构建保存的文件名,这里简单使用索引作为文件名,可以根据需要调整
file_path = os.path.join(save_dir, f'photo_{idx}.jpg')
with open(file_path, 'wb') as file:
file.write(response.content)
print(f'Saved {file_path}')
else:
print(f'Failed to download {image_url}')
重要提示:请确保你有权下载和使用这些照片,并且你的爬虫活动符合斗鱼直播的使用条款和政策。此外,斗鱼直播的网页结构可能会发生变化,因此上述代码可能需要根据实际情况进行调整。如果你不确定是否合法或如何合法地进行爬虫活动,请咨询法律专业人士。


✨ 六. 总结
本文介绍了Python爬虫的由来、基本原理和实战应用。通过学习本文内容,读者可以掌握爬虫的基本概念和工作机制,了解网络传输协议和状态码的意义,并学会使用抓包工具和Python进行爬虫开发。在实际应用中,需遵守法律法规和伦理规范,确保合法合规地进行数据抓取和处理。
"免费IP池大放送!助力您的数据采集之旅,我们是您最佳的数据采集搭档。高质量、稳定、免费的IP资源等您来拿,让数据采集变得更加高效、轻松!赶快行动吧,与我们携手,共创数据采集新篇章!"赶紧行动起来吧!