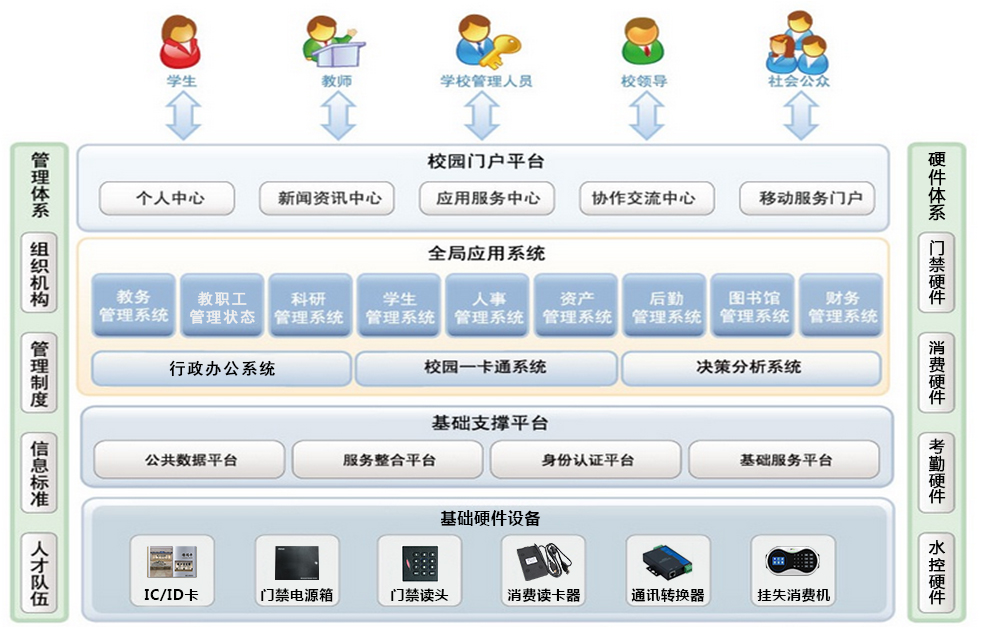
文章目录:
5.1 标量原子类型(整型int 浮点型float 字符串型str 布尔型bool)
参考:3小时快速入门Python、小飞有点东西(基础364集 进阶94集 高级182集)
绝大多数来源于书本知识点汇总
机器语言:这是计算机能直接识别和执行的指令系统,由二进制代码表示 机器语言具有灵活、直接执行和速度快等特点 汇编语言:这是一种面向处理器的程序设计语言,以人类的日常语言为基础 汇编语言使用助记符来代替机器语言的二进制代码,便于人们记忆和编写 高级语言:这类语言具有更好的抽象和封装能力,可以跨平台使用 高级语言包括很多种,如C、C++、Java、C#、Python、VB等编译性语言写的程序执行之前,需要一个专门的编译过程,把程序编译成为机器语言的文 比如exe文件,以后要运行的话就不用重新翻译,直接使用编译的结果即可。因为翻译只做了一次,运行时不需要翻译,所以编译型语言的程序执行效率高 常见的编译性语言有:C/C++、Pascal/Object Pascal(Delphi)等 解释性语言则不同,解释性语言的程序不需要编译,省了道工序,解释性语言在运行程序的时候才翻译 比如解释性Java语言,专门有一个解释器能够直接执行Java程序,每个语句都是执行的时候才翻译,所以效率比较低 常见的解释性语言有:Java、Python、Perl、C#、JavaScript、VBScript、Ruby、MATLAB等
一:软件环境安装
第一个软件:pycharm
第一步:环境Downloads_Windows installer (64-bit)(安装好后命令行输入Python查看是否安装成功)
第二步:软件PyCharm
第三步:长久使用、汉化(插件里面安装Chinese然后重启软件就是)
python解释器:把代码转换成字节码后再执行 代码编辑器:pycharm
新建工程
创建工程/新建项目 a 位置:选择自己需要保存工程的位置 b 基础解析器:选择上面环境安装的解释器 c 取消勾选“创建Main.py” 目录结构 venv:这个项目独立的python虚拟环境,不同的项目考研用不同的解释器版本和第三方库 写代码 选择最上面的文件夹——>右键——>新建——>python文件——>取名.py——>回车 取消将文件添加到git 运行 第一种:右键运行 第二种:点击上面的绿色播放按钮
第二个软件:thonny
注释代码 第一种:# 第二种:alt + 3 注释代码:ctrl + 3
第三个软件:IDIE(自带的集成开发环境)
在安装Python时,Python IDLE已经被一并安装
在Windows上:您可以通过开始菜单中的Python文件夹来启动Python IDLE 在Mac和Linux上:您可以打开终端并输入“idle3”来启动Python IDLE使用方法
第一步:搜索IDIE打开软件 第二步:点击File——>New File新建文件——>命名并保存文件——>编写代码 第三步:运行代码——>Run——>Run Module 运行代码——>F5
二:相关
1.规范
python有严格的缩进要求:1个tab键的距离 或 4个空格键的举例 在python中不管是变量还是常量还是函数:都是严格区分大小写的
2.关键字
Python中的关键字是一组具有特殊含义的预定义标识符,它们不能用作变量名、函数名或其它标识符(尝试使用它们作为标识符将导致语法错误)
#下面是Python 3中的关键字列表(注意,这个列表可能随着Python版本的更新而有所变化) import keyword print(keyword.kwlist) #可以打印出python里面所有的关键字这些关键字具有以下含义:
False 和 True:布尔逻辑值,分别表示假和真 None:表示空或无值 and、or、not:逻辑操作符 assert:用于调试目的的断言语句 async 和 await:用于异步编程的关键字 break:跳出循环 class:定义新类 continue:跳过当前循环的剩余部分,进入下一次迭代 def:定义函数 del:删除对象 elif 和 else:条件语句的一部分 except 和 finally:异常处理语句的一部分 for 和 in:循环语句 global:声明全局变量 if:条件语句 import:导入模块或库 is:身份运算符 lambda:定义匿名函数 nonlocal:声明非局部变量 pass:空操作语句,占位用 raise:引发异常 return:从函数返回值 try:异常处理语句的一部分 while:循环语句 with:简化异常处理的上下文管理语句 yield:用于生成器函数的关键字
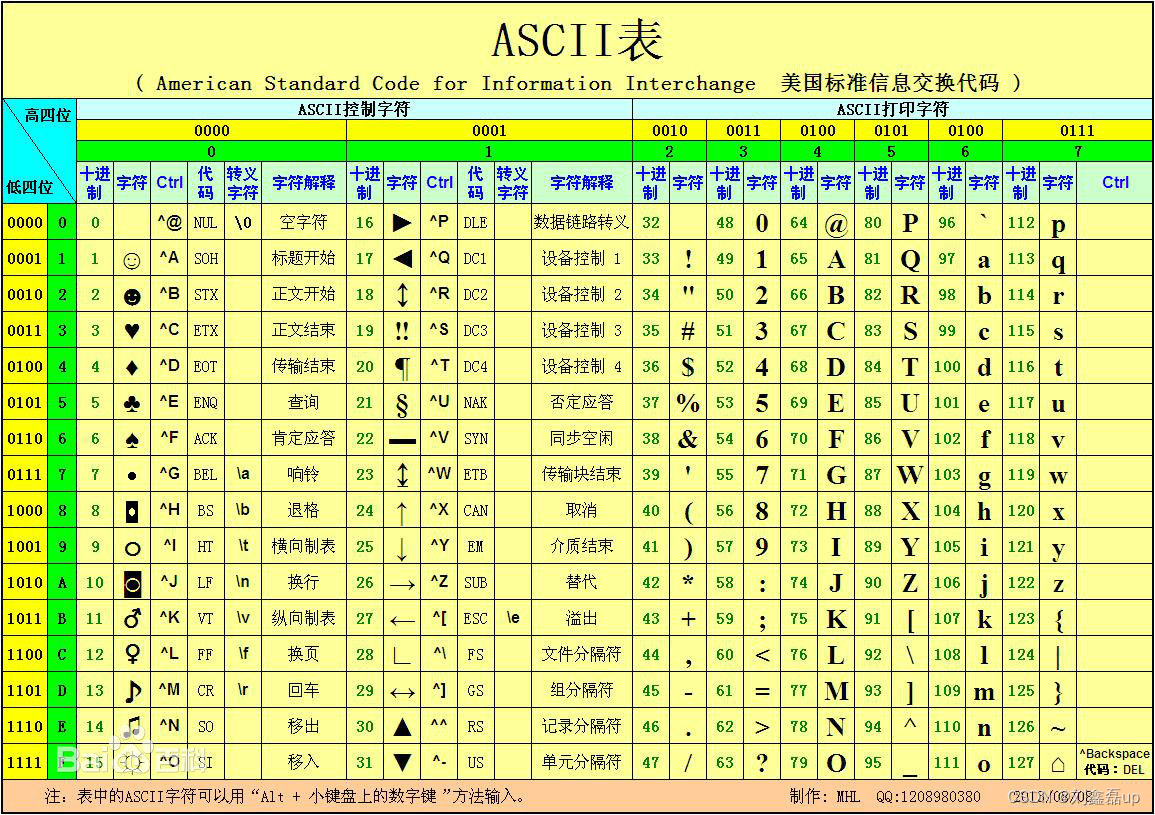
3.Ascll码表
是一种字符编码标准,它允许使用单个数字(称为码点)来表示世界上的任何字符
A~B:65~90 a~b:97~122 0~9:48~57 26个英文字母,大写和小写之间相差32 ord函数:接受一个字符,返回一个字符的 Unicode码点 print(ord('A')) chr函数:接受一个整数,并返回相应的字符 print(chr(65)) print(chr(ord('A') + 32)) #a print(chr(ord(chr(65)) + 32)) #a
三:语法基础
1.各种符号
1.1 注释
顶格:后面两种
第一种:#(一般在#号后面空两格) 快捷键:ctrl+/ 第二种:"""这里面的内容是会被注释的""" 第三种:'''这里面是注释'''
1.2 占位置的
pass for i in range(5): # 我们打算循环5次,但目前还没有决定每次循环要做什么 pass ... x = 10 if x > 5: # 当x大于5时,我们还没有决定要做什么 ... else: print("x不大于5")
1.3 回车换行
回车:\r 换行:\n
2.输入输出
2.1 输入input
必须赋值接收:输入名字并且按下enter时,才会执行下一个print()语句
a1=input("请输入:") print(a1) a2=input('请输入:') print(a2) b=input("请输入一个整数:") print(int(b)) c=input("请输入一个浮点数:") print(float(c)) d=input("请输入一个字符串:") print(str(d)) -------------------------------------------------------------------- # 强制类型转换 int() str() float() bool() name=int(input("请输入你的年龄:")) print(name,end="") print("岁") money=input("请输入你有多少零花钱:") print(int(money))
2.2 输出print
# 会换行 print('\n') print() print('') # 不会换行 print(,end='') # 制表符print('\t') -------------------------------------------------------------------- sep:这是一个字符串,用于指定在打印多个值时,它们之间的分隔符 默认情况下,sep 的值是 ' '(一个空格) 例如:print(1, 2, 3, sep='-') 输出:1-2-3 end:这是一个字符串,用于指定打印结束后要添加的字符或字符串 默认情况下,end 的值是 '\n'(一个换行符),这意味着每次调用 print() 函数后,都会有一个新行 例如:print(1, end='***') print(2) 输出:1***2 -------------------------------------------------------------------- #格式化输出:%d整数 %f浮点数 %s字符串 #整数 d a = 3 print('%d' %a) print('%03d' %2) # %03d:如果不足3位,左边用0补齐 print('%3d' %2) # %3d:如果不足3位,左边用空格补齐 print('%-3d' %2) # %-3d:如果不足3位,右边用空格补齐 #浮点数 f print('%.2f' %3.14159265) # 保留小数点后面2位 print('%.*f' %(5,3.14159265)) # 保留小数点后面5位 print('%6.2f' %3.14159265) # 保留小数点后面2位同时让结果占6个空格,左边用空格补齐 #字符串 s print('my name is %s' %'tom') print('my name is %s,and i am %s years old' %('tom',10))举例
print("hello world!") print('hello world!') print('hello world!'+"欢迎来到python"+'的编程世界') a=10 print('你今年多少岁',a,'岁',"了") print("你在\"干\'什么") print ("\n") print ("123\n456") print(""" 离离原上草,一岁一枯荣 野火烧不尽,春风吹又生""") print(''' 鹅鹅鹅,曲项向天歌 白毛浮绿水,红掌拨清波''') print(100) name="刘鑫磊" name='刘鑫磊' print(name) # print会默认分行:如果我们不想分行 print('粒子') print('编程') print('粒子',end='') print('编程',end='') #-------------------------------------------------------------------------# print('Hello') print('hello world!') print("刘鑫磊") print("打印矩形") print("****") print("* *") print("* *") print("****") print("打印飞机") print(" *") print(" ** ") print("* *** ") print("** **** ") print("*****************") print("** **** ") print("* *** ") print(" ** ") print(" *") print("自定义打印三角形:") #先打印空格,再打印星星* def print_pyramid(n): #当输入4 for i in range(n): #0 1 2 3 # 打印空格 print(' ' * (n - i - 1), end='') #3 2 1 0 # 打印星号 print('*' * (2 * i + 1)) #1 3 5 7 row=int(input("请输入行数:")) print_pyramid(row) print("定型打印三角形:") print(" * ") print(" *** ") print("*****") print("定形打印菱形:") print(" * ") print(" *** ") print(" ***** ") print("*******") print(" ***** ") print(" *** ") print(" * ") print(12345*54321) print('|' + '-' + '|') print(20 / 4) print("低碳环保,从我做起"*3,end="")
2.3 格式化输出
速度:f>format>%
2.3.1 百分号%
%s字符串:可以结束任意类型的值 %d整型:只能接收整型 #后面位置是一一对应的 a='my name is %s,I am from %s' % ('刘鑫磊','四川') print (a) #后面位置可以是不对应的 b='my name is %(name)s,I am from %(hometown)s' % {'hometown':'刘鑫磊','name':'四川'} print (b)
2.3.2 format
可以传任意类型的值
第一种:对应地方写入 样式1 name="刘鑫磊" fromhome="四川" a=""" 大家好,我叫{0} 来自{1}省 """.format(name,fromhome) #""".format(刘鑫磊,四川) print(a) def introduce(name, age): # 拼接name和age introduction = "{}, {} years old".format(name, age) # 使用print打印拼接后的字符串 print(introduction) # 调用introduce方法 introduce("Alice", 30) # 调用introduce方法 introduce("Alice", 30) 样式2:可以重复 a1=""" 大家好,我叫{0}{0}{0} 来自{1}{1}{1}省 """.format(刘鑫磊,四川) print(a1) 样式3:可以变化位置(键值对) a = """ 大家好,我叫{fromhome} 来自{name}省 """.format(name = "刘鑫磊", fromhome = "四川") print(a) 第二种:快速填充补充 d='{0:*^10}'.format('开始') print(d) #运行结果****开始**** #^居中 >左边 <右边 第三种:数字格式 e='{num:.2f}'.format(num=3.1415926) print(e)
2.3.3 字母f
shuiguo="西瓜" shucai="土豆" b=f""" #b=f'喜欢吃的水果是{shuiguo}喜欢的蔬菜是{shucai}' 喜欢吃的水果是{shuiguo} 喜欢的蔬菜是{shucai} """ print(b)
3.变量常量
规范 [会严格区分大小写]:变量(全小写)、常量(全大写) 变量 变量取名:文字、数字、下划线 变量名=值 先定义再引用 x = 5 y = "Hello, World!" a="吃饭了" print("刘鑫磊"+a) print("周星驰"+a) print("刘德华"+a) #给多个变量赋值 a=b=c=d print(a,b,c,d) a,b,c,d=4,8,9,6 print(a,b,c,d) 常量 PI = 3.14159 from const import Const PI = Const(3.14159) # 尝试更改常量的值将会引发错误# PI = 2.71828 # 这将引发错误 from enum import Enum class MathConstants(Enum): # 你可以通过枚举类来访问常量 PI = 3.14159 print(MathConstants.PI.value) # 输出: 3.14159 # 尝试更改枚举常量的值将会引发错误# MathConstants.PI = 2.71828 # 这将引发错误例题
#交换变量 a=666 b=888 temp=a a=b b=temp print(a,b) #取出一个三位数的个十百位 a1=int(input("请输入一个三位数:")) gewei=a1%10 #取出几十的个位(123 12) 几十的十位(123 23) shiwei=a1//10%10 #(al%100)//10 baiwei=a1//100%10 #a1//100 print(gewei+shiwei*10+baiwei*100) #取出一个四位数的个十百位 a2=int(input("请输入一个四位数:")) gewei=a2%10 shiwei=a2//10%10 baiwei=a2//100%10 qianwei=a2//1000%10 print(gewei+shiwei*10+baiwei*100+qianwei*1000)
4.运算符
4.1 数学运算符
| 运算符 | 描述 | 实例(a=10 b=20) |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 30 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 200 |
| / | 除 - x除以y | b / a 输出结果 2 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 0 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的20次方, 输出结果 100000000000000000000 |
| // | 取整除 - 返回商的整数部分(向下取整) | >>> 9//2 4 >>> -9//2 -5 |
import math #math.函数名(...) print(math.sin(1)) #一元二次方程:ax^2+bx+c=0 -x^2-2x+3=0 # -b±√(b^2-4ac) #x= ˉˉˉˉˉˉˉˉˉˉˉˉ # 2a a=-1 b=-2 c=3 print((-b+math.sqrt(b*b-4*a*c))/(2*a)) print((-b-math.sqrt(b*b-4*a*c))/(2*a))
4.2 比较运算符
| 运算符 | 描述 | 实例(a=10 b=20) |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False。 |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 True。 |
| <> | 不等于 - 比较两个对象是否不相等。python3 已废弃。 | (a <> b) 返回 True。这个运算符类似 != 。 |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False。 |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量 True 和 False 等价。 | (a < b) 返回 True。 |
| >= | 大于等于 - 返回x是否大于等于y。 | (a >= b) 返回 False。 |
| <= | 小于等于 - 返回x是否小于等于y。 | (a <= b) 返回 True。 |
4.3 赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
4.4 位运算符
| 运算符 | 描述 | 实例 a = 60 # 二进制:0011 1100 |
|---|---|---|
& 与 |
按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 【都1则1】 |
(a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| 或 |
按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 【一1则1】 |
(a | b) 输出结果 61 ,二进制解释: 0011 1101 |
^ 异或 |
按位异或运算符:当两对应的二进位相异时,结果为1 【相异则1】 |
(a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
~ 取反 |
按位取反运算符:将二进制表示中的每一位取反,0 变为 1,1 变为 0。~x 类似于 -x-1 【取反】 |
(~a ) 输出结果 -61 ,二进制解释: 1100 0011 (以补码形式表示),在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把">>"左边的运算数的各二进位全部右移若干位,>> 右边的数字指定了移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
4.5 逻辑运算符
| 运算符 | 逻辑表达式 | 描述 | 实例(a=10 b=20) |
|---|---|---|---|
and 与 |
x and y | 布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | a > 5 and b < 30 # True (a and b) 返回 20 (True或非零)(False零) 会返回两个操作数中的第一个 如果所有操作数都是 |
or 或 |
x or y | 布尔"或" - 如果 x 是非 0,它返回 x 的计算值, 否则它返回 y 的计算值。 |
c < 3 or d > 10 # True (a or b) 返回 10 返回两个操作数中的第一个 |
not 非 |
not x | 布尔"非" - 如果 x 为 True,返回 False 。 如果 x 为 False,它返回 True。 |
not(a and b) 返回 False |
| 优先级 | not > and >or | ||
4.6 成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
4.7 身份运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
4.8 字符串运算符
| 运算符 | 描述 |
|---|---|
| + | 串联运算符 |
| += | 串联赋值运算符 |
4.9 运算符优先级
| 运算符 | 描述 |
|---|---|
| () | 小括号 |
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
5.数据类型
分类
可变和不可变分:栈和堆区分 可变类型:值改变的情况下,id不变,说明改的是原值 列表、字典、集合 # 创建一个字符串 my_string = "Hello, World!" # 尝试修改字符串(这实际上会创建一个新的字符串对象) # 并不直接修改原始字符串,而是返回一个新的字符串 my_string = my_string.replace("World", "Python") # 输出修改后的字符串 print(my_string) # 输出: Hello, Python! # 尝试修改原始字符串(这是不可能的) my_string[0] = 'h' # 这将引发TypeError 不可变类型:值改变的情况下,id也变,说明改的不是原值 不允许变量的值发生变化,改变了变量的值,相当于新建了一个对象,地址也会发生变化 整型、浮点型、字符串、元组 # 创建一个列表 my_list = [1, 2, 3, 4, 5] # 修改列表中的一个元素 my_list[1] = 20 # 输出修改后的列表 print(my_list) # 输出: [1, 20, 3, 4, 5] # 添加一个新元素到列表末尾 my_list.append(6) # 输出修改后的列表 print(my_list) # 输出: [1, 20, 3, 4, 5, 6] 访问方式分 通过变量名访问:整型、浮点型 通过索引访问指定的值(序列类型):字符串、列表、元组 通过key访问指定的值(映射类型):字典 通过变量名访问整体(无法访问某一个值):集合共有操作
len函数:计算容器中元素的个数 del函数:删除容器中指定的数据元素 max函数:返回容器中元素最大值 min函数:返回容器中元素最小值 切片操作:从容器中抽取出想要的数据元素 可以使用的(有序的):字符串、列表、元组 集合和字典不可以:因为无序
共有运算符操作 运算符 例子 结果 描述 支持的数据类型 + [1,2]+[3,4] [1,2,3,4] 合并元素 字符串、列表、元组 * ['hi'] * 4 ['hi','hi','hi','hi'] 复制元素 字符串、列表、元组 in 3 in (1,2,3) True 元素是否存在于其中 字符串、列表、元组、字典 not in 4 not in (1,2,3) True 元素是否不存在于其中 字符串、列表、元组、字典 > >=
< <=
==
(1,2,3)<(2,2,3) True 元素比较 字符串、列表、元组
5.1 标量原子类型(整型int 浮点型float 字符串型str 布尔型bool)
| 标准原子类型 | |||||
| 类型 | 关键字 | 类型符% | 前缀 | 长度 | 取值范围 |
| 字节型 | Byte | byt | 1个字节 | 0~255 | |
| 整型 | Integer | d | int | 2个字节 | -32768~32767 |
| 浮点类型 | Float | f | float | 4个字节 | 绝对值在1.401298*10-45~3.402823× 1038之间 |
| 字符串类型 | String | s | str | 2个字节 | 字符串的长度取决于字符串中字符的数量 |
| 布尔类型 | Boolean | bool | 2个字节 | True -1 或 False 0 |
|
| 空值类型 | NoneType | None | None | ||
字符串:str "hello" 'world' string 'hello "world"' 'hello \'world\'' 整数:int 100 integer 取整的时候不会做四舍五入运算 浮点数:float 1.0 2.01 布尔类型:bool True False 空值类型:NoneType None 不同的数据类型做运算时:结果的数据类型为运算中精度较高的那一数据类型 返回数据类型:type(表达式) 得到字符串的长度:len("字符串信息") 布尔类型(必须大写):True False 空值类型(必须大写):None
5.1.1 字符串str
索引取值 可以取值,不可以改值 从前往后数(第一个字符的所在位置是0):0 1 2 3... 从后往前数(负向的索引):-1 -2 -3... a = 'how are you' a[0].print/print(a[0]) 切片:如果那边不写,就截取到对应的端点处 print(a[0:3]) print(a[:3]) #从哪里到哪里how print(a[0:3:2]) #步长hw print(a[3:0:-1]) #反向步长wo 照顾头不顾尾 #截取出生年月日 number = '350581199608121527' print(number[6:14]) 成员运算in和not in print(not 'are' in 'how are you') 内置函数 strip去除符号 strip去除字符串左右两端的符号 name=' hahaha ' #括号里面就是想要去除的符号 res=name.strip() #去除! res=name.strip(!) print(res) lstrip左边 rstrip右边 split拆分、rsplit names='李白-韩信-露娜-孙悟空' res=names.split('-') #从左往右第几个地方开始拆分 res=names.split('-',1) print(res) #//转义字符:/ 长度len len1=len(a) print(len1) lower小写 降低、upper大写 上 判断全部是否为大写:isupper 判断全部是否为小写:islower # 使用 lower() 方法将字符串转换为小写 original_string = "Hello, World!" lowercase_string = original_string.lower() print(lowercase_string) # 输出: "hello, world!" # 使用 upper() 方法将字符串转换为大写 original_string = "Hello, World!" uppercase_string = original_string.upper() print(uppercase_string) # 输出: "HELLO, WORLD!" startswith什么开头、endswith什么结束 s = "Hello, world!" print(s.startswith("Hello")) # 输出:True print(s.endswith("world!")) # 输出:True join:每个元素之间的连接 names=['李白','韩信','露娜','孙悟空'] print('-'.join(names)) #李白-韩信-露娜-孙悟空 replace替换/取代:并不直接修改原始字符串,而是返回一个新的字符串 names='李白-韩信-露娜-孙悟空' print(names.replace('-',':')) find查找 a="i am newbie in python.python rocks" #查找"newbit" print(a.find("newbie")) #如果重复就显示第一次出现的位置 print(a.find("python")) #r如果没有找到就返回-1 print(a.find("java")) isdigit判断是否是纯数字组成 a="111111" print(a.isdigit()) --------------------------------------------------------------遍历 #字符串的遍历 # 第一种方法 my_string = "Hello, Python!" # 使用for循环遍历字符串 for i in my_string: # 打印每个字符 print(i) # 第二种方法 my_string = "Hello, Python!" # 使用range和字符串的长度来遍历字符串的索引 for index in range(len(my_string)): #for index in range(0,len(my_string)): # 打印每个字符及其索引 print(my_string[index]) # 第三种方法 my_string = "Hello, Python!" # 初始化索引为0 index = 0 # 当索引小于字符串长度时,继续循环 while index < len(my_string): # 打印当前索引处的字符 print(my_string[index]) # 移动到下一个索引 index += 1
5.2 存储容器类型
列表和字典可以嵌套使用
5.2.1 列表list[数组]
# 方法:对象.方法名(...) a.append("橘子") # 函数:函数名(对象) len(a) 可以存放不同数据类型(包括列表);但是一般用来存同种类型的数据 a=["苹果","梨子","香蕉"] b=[100,10,1000,99,66,1,88] l=[73,3.5,'刘鑫磊',['aaa','bbb']] 嵌套取值 print(a[1]) print(l[3][1]) ----------------------------------------------------------- append是添加单个元素到列表末尾,而extend是添加多个元素和另一个列表的所有元素到当前列表的末尾 extend添加:列表 b=[1,2,3,4] a=[5,6,7] a.extend(b) print(a) append追加:元素 a.append("橘子") print(a) insert插入:索引号 和 值 a.insert(2,'李子') #插入的索引号 运算符追加:+= a=[1,2,3,4,5] b=[6,7,8,9] a+=b print(a) 删 删除del:删除指定的列表元素 del a[0] print(a) del在删除列表中的连续元素时,不会删除最大的索引的元素 比如[0:2]只删除第0个和第1个索引所对应的元素 移除remove:按照元素移除指定的值 a.remove("苹果") print(a) pop:删除指定位置的数据元素,没有指定默认删除最后一个元素 name=["小红","明明","可可"] name.pop(0) print(name) clear:清除列表中所有的数据 name.clear() 改 替换 a[2]="芒果" print(a) 列表元素的修改 list1=[1,2,3,4] for i in range(0,len(list1)): #for i in list1: list1[i]=list1[i]+1 print(list1) 查 #注意它们两个的序列标号都是从左到右的:0 1 2 3... index():方法从序列的开头开始搜索子序列或元素,并返回 第一次出现的位置索引,没有查到则报错 rindex():方法从序列的末尾开始搜索子序列或元素,并返回最后一次出现的位置索引,没有查到则报错 a=[1,2,3,4,5] print(a.index(3)) print(a.index(8)) a=[12,35,56,23] #值 print(a[0]) print(a[1]) #索引 print(a.index(56)) ----------------------------------------------------------- 最大最小 print(max(b)) print(min(b)) 求和 sum() rand:可以保留指定的小数位数(会自动进行四舍五入操作) #当传入1个参数:这个参数为具体的数值,默认保留0位小数 #当传入2个参数时:第1个参数位具体的数值,第2个为保留的小数位数 x=3.1415926 print(round(x,3)) 切片 #列表名=[起始下标:结束下标:步长] #步长默认为1可以省略不写 #范围两头可以省略不写 a=["苹果","梨子","香蕉","橘子","榴莲","李子","板栗"] print(a[0:7]) print(a[0:7:1]) print(a[::1]) print(a[::]) print(a[0:7:2]) #步长默认为1 可以省略 print(a[:7:2]) #起始下标为0可以省略 print(a[0::2]) #起始下标为0可以省略 print(a[-1]) print(a[-5:-1]) print(a[-1:-5:1]) #必须由小到大(范围出错就会为空):解决办法是步长也取反 print(a[-1:-5:-1]) print(a[0:-1]) #实际范围是0到-2 print(a[::-1]) #逆序取出 排序sort()没有返回值 sorted()有返回值 sort() name=[5,1,2,9,3,4] print(name.sort()) name.sort() print(name) sorted() my_list = [5, 1, 2, 9, 3, 4] # 原始列表 sorted_list = sorted(my_list) # 使用 sorted() 函数排序,并赋值给新变量 print(sorted_list) # 打印排序后的列表: [1, 2, 3, 4, 5, 9] print(my_list) # 原始列表保持不变输出: [5, 1, 2, 9, 3, 4] 降序排序reverse=True print(sort(name,revers=true) 升序排序(默认)reverse=False print(sort(name,revers=false) 统计长度 len() 统计出现的次数:count name=[1,5,3,2,9,"花花","心心","花花"] print(name.count("花花")) 反转:reverse() a=["苹果","梨子","香蕉","橘子","榴莲","李子","板栗"] print(a[::-1]) a=["苹果","梨子","香蕉","橘子","榴莲","李子","板栗"] a.reverse() print(a) 列表的运算 list1=[1,2,3,4] list2=[1,2,'a','b','c','d'] print(list1+list2) print(list1 * 2) split分割:常用于字符串转化为列表 str='hello world python' print(str.split()) #字符串转化为列表 str='hello,world,python' print(str.split(',')) #将输入分隔为多个字符串,存储在字符串列表a中 a = input().split() # 从后往前列举,相当于倒序列举 for x in a[::-1]: print(x, end = ' ') join:列表转化为字符串 #join要求传入列表的每一个数据都是字符串类型 li=['i','am','a','student'] s='' print(s.join(li)) #没有空格进行连接 map集合:通常用于对集合(set)或其他可迭代对象(如列表、元组等)中的每个元素应用某种转换 与列表相比,map 在处理大数据集时可能更加高效,因为它可以并行处理数据 str='11 22 33 44' li=str.split() #列表类型 print(li) x=map(int,li) #把列表类型转化为int类型,得到一个集合 print(map(int,li)) #map返回的是一个迭代器,如果你想看到结果,可以将其转换为列表 print(list(x)) #将map类型的集合强制转为列表类型,便于查看 列表转化为字符串:常用方法格式 li1 = ['I',2,'a','student'] s = '' m = map(str,li1) li2 = list(m) print(s.join(li2)) -----------------------------------------------------------遍历 # 第一种方法 my_string = ["苹果","梨子","香蕉","橘子","榴莲","李子","板栗"] # 使用for循环遍历字符串 for i in my_string: # 打印每个字符 print(i) # 第二种方法 my_string = ["苹果","梨子","香蕉","橘子","榴莲","李子","板栗"] # 使用range和字符串的长度来遍历字符串的索引 for index in range(len(my_string)): #for index in range(0,len(my_string)): # 打印每个字符及其索引 print(my_string[index]) # 第三种方法 my_string = ["苹果","梨子","香蕉","橘子","榴莲","李子","板栗"] # 初始化索引为0 index = 0 # 当索引小于字符串长度时,继续循环 while index < len(my_string): # 打印当前索引处的字符 print(my_string[index]) # 移动到下一个索引 index += 1
列表生成式
# 列表生成式:[结果 for item in 可迭代对象 if 条件] 原始方法 l = ['康师傅_老坛酸菜', '统一_老坛酸菜', '大今野_老坛酸菜', '白象'] new_l = [] for name in l: if name.endswith('老坛酸菜'): new_l.append(name) print(new_l) 列表生成器 new_l = [name for name in l if name.endswith('老坛酸菜')] print(new_l)
5.2.2 元组tuple(不可变的列表)
比数组节约空间 :元组不可以增删改查
#将一系列的同类或不同类型的元素组合在一起,里面的数据元素不可以修改,访问比列表更快#作用:元组 #主要用于:存储不需要修改的数据集合 #元组被创建:不能修改、添加、删除、修改其中的元素 #当元组的元素只有一个数据的时候需要在数据的后面加上逗号 可以包含不同类型 a(1,1.2,'abc',[4,5,6],{'a':1,'b':2},(7,8,9)) 空列表:a[] 空元组:a() 访问方式:元组和列表相同(用的和列表的方法一样) 元组名[序号] 元组的嵌套性 a=(1,2,("hello","python")) print(a[2]) print(a[2][0]) ------------------------------------------------------------------ 扩展:创建新的元组对象 拼接 msg = ('木', '火', '土', '金', '水') new_msg = msg + ('雷',) # 注意这里是一个逗号,用来创建一个只包含一个元素的新元组 print(new_msg) # 输出: ('木', '火', '土', '金', '水', '雷') msg = ('木', '火', '土', '金', '水') # 假设我们想要将第二个元素('火')替换为'风' new_msg = msg[:1] + ('风',) + msg[2:] # 创建一个新的元组,其中第二个元素被替换为'风' print(new_msg) # 输出: ('木', '风', '土', '金', '水') 添加 a = (1,2,3,4,5,6,8,9) #不支持将元组与单个元素(如整数、字符串等)直接相加来扩展元组 b = a + (7,) #不能是(7):需要新建一个元组(添加一个包含 7 的新元组来实现) print(b) 复制 a = (1,2,3) print(a*3) 查询 利用索引下标查询元素中某个特点的数据元素 a=(22,33,44) print(a[2]) #这里利用的是列表查询的方法 利用index函数可以查询数据首次出现的索引位置 a=(22,33,44,22) b=a.index(22) print(b) 索引取值:正反 # 定义一个元组 t = (1, 2, 3, 4, 5) # 正向索引取值 print(t[0]) # 输出:1 print(t[2]) # 输出:3 # 反向索引取值 print(t[-1]) # 输出:5 print(t[-3]) # 输出:3 切片:步长、反向步长 统计出现的次数:count(元组名) 统计长度:len(元组名) 最大:max(元组名) 最小:min(元组名) 成员运算:in not in a=(1,2,3,4) print(1 in a) 类型转换 将其他转化为元组 list_data = [1, 2, 3, 4] #将列表转换为元组 list_data = {1, 2, 3, 4} #将集合转换为元组 list_data = "hello" #将字符串转换为元组 a=tuple(list_data) print(a) 将元组转换为字符串 Tuple_data = (1, 2, 3, 4) str_data = ''.join(map(str, Tuple_data)) print(str_data) # 输出: '1234' ------------------------------------------------------------------遍历 # 第一种方法 my_string = ("苹果","梨子","香蕉","橘子","榴莲","李子","板栗") # 使用for循环遍历字符串 for i in my_string: # 打印每个字符 print(i) # 第二种方法 my_string = ("苹果","梨子","香蕉","橘子","榴莲","李子","板栗") # 使用range和字符串的长度来遍历字符串的索引 for index in range(len(my_string)): #for index in range(0,len(my_string)): # 打印每个字符及其索引 print(my_string[index]) # 第三种方法 my_string = ("苹果","梨子","香蕉","橘子","榴莲","李子","板栗") # 初始化索引为0 index = 0 # 当索引小于字符串长度时,继续循环 while index < len(my_string): # 打印当前索引处的字符 print(my_string[index]) # 移动到下一个索引 index += 1举例
创建一个元组,存储1~10之间的所有整数,包含1和10遍历这个元组,把其中所有的奇数打印在控制台 # 创建一个元组,包含1到10之间的所有整数 numbers = tuple(range(1, 11)) # 遍历元组,打印出所有的奇数 for number in numbers: if number % 2 != 0: # 如果数字除以2的余数不为0,则它是奇数 print(number)创建一个元组,存入1~10之间的所有整数的字符串形式包含1和10 遍历这个元组,将里面的每个数字都转换成整数,然后存入一个集合中 # 1) 创建一个元组,存入1~10之间的所有整数的字符串形式 string_tuple = tuple(str(i) for i in range(1, 11)) # 2) 遍历这个元组,将里面的每个数字都转换成整数,然后存入一个集合中 integer_set = set(int(s) for s in string_Tuple) # 打印结果 print("String Tuple:", string_Tuple) print("Integer Set:", integer_set)
生成器表达式
# 生成器表达式 l = ['康师傅_老坛酸菜', '统一_老坛酸菜', '大今野_老坛酸菜', '白象'] res = (name for name in l) # print(res, type(res)) print(next(res)) print(res.send(None)) print(res.send(10)) print(res.send('张大仙')) print(res.send('张大仙'))
5.2.3 字典dict{}
必须是唯一的;必须是不可变的数据类型(整形 字符串 元组) ;可以是不同类型
#字典contacts 键key:值value key是唯一的不能重复 a={"1":"刘鑫磊","2":"刘德华","3":"刘亦菲","4":"刘诗诗"} print(a) #{'1': '刘鑫磊', '2': '刘德华', '3': '刘亦菲', '4': '刘诗诗'} 定义 第一种:原始方法直接写 b={'aaa':1,2:2,3.1:3,(4,54,6):4} 第二种:dict()创建 a=dict({'aaa':1,2:2,3.1:3,(4,54,6):4}) print(a) 第三种:赋值 print(dict(a=1,b=2,c=3)) 第四种:fromkeys用于创建一个新的字典 keys1 = ['name', 'gender', 'age'] keys2 = dict.fromkeys(keys1, None) #创建了一个新的字典 keys2 print(keys2) #输出{'name': None, 'gender': None, 'age': None} keys1 = ['name', 'ager', 'city'] keys2 = dict.fromkeys(keys1, 'default') #创建了一个新的字典 keys2 print(keys2) # 输出:{'name': 'default', 'age': 'default', 'city': 'default'} d = dict.fromkeys('abc') print(d) # 输出:{'a': None, 'b': None, 'c': None} d = dict.fromkeys('abc', 0) print(d) # 输出:{'a': 0, 'b': 0, 'c': 0} 第五种:循环遍历 keys = ['name', 'age', 'city'] values = ['Alice', 25, 'New York'] d = {k: v for k, v in zip(keys, values)} print(d) # 输出:{'name': 'Alice', 'age': 25, 'city': 'New York'} 取值 a={"1":"刘鑫磊", "2":"刘德华", "3":"刘亦菲", "4":"刘诗诗"} print(a.get('1')) #值 print("1" in a) #判断键是否存在 print(a["3"]) #值 msg=('张大仙',19) name,age=msg #键值 print(name,age) dict:必须成对的才可以(转化为字典类型) hao=[('name','张大仙'),['age',18]] print(dict(hao)) a={"1":"刘鑫磊","2":"刘德华","3":"刘亦菲","4":"刘诗诗"} for k in a: print(k,a[k]) #会取出键值对 设置默认值:setdefault info = {'name': '张大仙', 'age': 18} info.setdefault('age', 20) # 如果 'age' 键不存在,设置其值为 20 info.setdefault('gender', '男') # 如果 'gender' 键不存在,设置其值为 '男' print(info) #{'name': '张大仙', 'age': 18, 'gender': '男'} 成员运算:in not in 内置方法 len:长度 zip:可以将两个列表对应的数据元素组合成一个元组(拼接压缩) list1={"语文","数学","英语"} list2={80,90,100} print(list(zip(list1,list2))) ------------------------------------------------------------------- 增加 字典名[键]=值 a["5"]="刘能" 删除 del 字典名[键] 删除指定的键值对;没有返回值;找不到会报错 del a["2"] print(a) 字典名.pop(键) popitme() 删除指定的键值对;有返回值;找不到会报错,除非提供第二个值作为默认参数 value = my_dict.pop("d", "default_value") print(value) d={"语文":80,"数学":90,"英语":100} d.pop("英语") print(d) 字典名.clear() 清除字典中所有的键值对;有返回值 d={"语文":80,"数学":90,"英语":100} d.clear() print(d) #返回{} 修改 修改:字典名[键]=值 #对字典中已经存在的值进行修改 设置默认键值:字典名.setdefault(键,值) #键值对不存在(就添加键值对)、存在(不做处理) 更新:字典名1老的.update(字典名2新的) #取出字典2的键值对,不存在(就添加)、存在(则覆盖) # 创建一个旧的字典 old_dict = {'apple': 1,'banana': 2,'cherry': 3} # 创建一个新的字典 new_dict = { 'banana': 4, # 这个键在新字典和老字典中都存在 'orange': 5, # 这个键只存在于新字典中 'pear': 6 # 这个键也只存在于新字典中 } # 使用 update() 方法将新字典的键值对更新到旧字典中 old_dict.update(new_dict) # 打印更新后的旧字典 print(old_dict) #{'apple': 1, 'banana': 4, 'cherry': 3, 'orange': 5, 'pear': 6} -------------------------------------------------------------------遍历查询 #a.keys()键:dict_keys(['name', 'age']) 字典名.keys() dict={'name':'baby','age':7} for i in dict.keys(): print(i) #输出: #a.values()值:dict_values(['baby', 7]) 字典名.values() dict={'name':'baby','age':7} for j in dict.values(): print(j) #a.items()键值对:前面默认带有dict_items标识:dict_items([(),(),.....]) 字典名.items() #输出格式是元组:k变量被赋值为一个元组,该元组包含键和值 dict={'name':'baby','age':7} for k in dict.items(): print(k) #输出:('name', 'baby') 和 ('age', 7) #输出格式是键和值分别作为单独的字符串:使用了元组解包。k(键)v(值) dict={'name':'baby','age':7} for k,v in dict.items(): print(k,v) #输出:name baby 和 age 7 ------------------------------------------------------------------------- #get(键)查询 字典名.get(键):根据键取值,键值对如果不存在则 不会报错 dict={1:1,2:2,3:3,"语文":80,"数学":90,"英语":100} for i in dict.keys(): print(dict.get(i)) #键查找值 print(dict.get("语文")) #键查找值 print(dict.get("化学")) #键不存在不会报错,会返回None #dict[键]查询 字典名[键]: 根据键取值,键值对如果不存在则 会报错 dict={'name':'baby','age':7} for i in dict.keys(): print(dict[i]) #键查找值
举例
# 创建字典 grades_dict = { 90: 'A', 80: 'B', 70: 'C', 60: 'D', 50: 'E' } # 定义函数来根据分数输出等级 def get_grade(score): for key, value in grades_dict.items(): if score >= key: return value return "Invalid score" # 如果分数不在范围内,返回无效分数 # 从控制台接收整数输入 input_score = int(input("请输入一个整数分数: ")) # 调用函数并打印结果 grade = get_grade(input_score) print(f"您的等级是: {grade}")# 1) 创建一个字典,里面有5个键值对 grades_dict = { 90: 'A', 80: 'B', 70: 'C', 60: 'D', 50: 'E' } # 2) 使用input在控制台接收一个整数 score = int(input("请输入一个整数: ")) # 3) 根据整数的范围输出对应的等级 if score >= 90: grade = 'A' elif score >= 80: grade = 'B' elif score >= 70: grade = 'C' elif score >= 60: grade = 'D' else: grade = 'E' # 4) 输出对应的等级 print(f"您的等级是: {grade}")
字典生成式
# 字典生成式 l = ['康师傅_老坛酸菜', '统一_老坛酸菜', '大今野_老坛酸菜', '白象'] res = {name: 5 for name in l} print(res, type(res)) l = [('康师傅_老坛酸菜', 5), ('统一_老坛酸菜', 6), ('大今野_老坛酸菜', 7), ('白象', 8)] res = {k: v for k, v in l if not k.startswith('康师傅')} print(res, type(res))
5.2.4 集合set{}
集合只能存取不可变类型,而且不可以重复(无序的不重复的序列)重复的会被抹除 作用:将一系列同类型或不同类型的不同元素放在一起 特点:数据在集合中是无序的,唯一的,集合类型用set表示 定义格式:集合用{}来定义的,元素之间用逗号隔开 注意点:因为集合无序,因此不允许使用下标访问元素 创建集合 集合1={1,2,3,4,5} tuple=(1,2,3,4,5) list=[1,2,3,4,5] 集合2=set(tuple) =set(list) 空集合 s={} s=set() print(type(s)) 集合的不可重复性 a = {'apple','banana','cherry ','apple','apple'} #会自动去重 print(a) 集合的无序性 a = {2,9,5,1} print(a) #每一次输出都可能都不相同 集合变列表 s={1,2,3} print(list(s)) #[1, 2, 3] 集合运算 交集运算:& intersection intersection_update set1={'A','B','c'} set2={'D','E','F'} set3=set1 & set2 #& print(set3) print(set1.intersection(set2)) #intersection s1.intersection(s2) print(set1.intersection_update(set2)) a={1,2,3,4} b={6,4,5,3} res= a & b print(res) 并集运算:| union update set1={'A','B','c'} set2={'D','E','F'} set3=set1 | set2 #| print(set3) print(set1.union(set2)) #union s1.union(s2) print(set1.update(set2)) a={1,2,3,4} b={6,4,5,3} res= a | b print(res) 差集运算:- difference difference_update set1={'A','B','c'} set2={'D','E','F'} set3=set1 - set2 #- print(set3) print(set1.difference(set2)) #difference s1.difference(s2) print(set1.difference_update(set2)) a={1,2,3,4} b={6,4,5,3} print(a-b) print(b-a) 对称差集:^ symmetric_difference symmetric_difference_update A△B=(A∪B)--(A∩B) A△B=(A--B)∪(B--A) print(set1.symmetric_difference(set2)) print(set1.difference_update(set2)) print((a-b)|(b-a)) 或 print(a^b) 父子集合:如果两者相等==,则互为父子,结果都是true 父集 >:s1.issuperset(s2) 子集 <:s1.issubset(s2) 内置函数 长度:len() 排序:sort() sorted() 成员运算:in not in --------------------------------------------------- 增加 add()方法:这个方法用于向集合中添加单个元素 my_set = {1, 2, 3} my_set.add(4) # 添加元素4 print(my_set) # 输出: {1, 2, 3, 4} 使用|=运算符来添加元素到集合中 my_set = {1, 2, 3} my_set |= {4, 5} # 等同于 my_set.update({4, 5}) print(my_set) # 输出: {1, 2, 3, 4, 5} update()方法:这个方法用于向集合中添加一个或多个元素 my_set = {1, 2, 3} my_set.update([4, 5]) # 添加元素4和5 (3,4) {4, 5} print(my_set) # 输出: {1, 2, 3, 4, 5} my_set = {1, 2, 3} another_set = {6, 7} my_set.update(another_set) # 添加元素6和7 print(my_set) # 输出: {1, 2, 3, 4, 5, 6, 7} 删除: discard():删除移除指定的元素;没有不会报错 s = {1,2,3,4} s.discard(3) print(s) remove():没有会报错 s = {1,2,3,4} s.remove(3) print(s) pop():随机删除一个元素 s = {1,2,3,4} s.pop() print(s) import random # 生成一个包含4个随机整数的集合 s = set(random.sample(range(10), 4)) s.pop() print(s) clear():清空集合中所有的元素 修改:通过转换修改 s = {1, 2, 3} list_s = list(s) # 将集合转换为列表 list_s[0] = 100 # 修改列表中的元素 s = set(list_s) # 将列表转回集合 print(s) # 输出: {100, 2, 3} 查询 # 创建一个集合 s = {1, 2, 3, 4, 5, 6} # 查询元素是否存在于集合中 print(3 in s) # 输出:True print(7 in s) # 输出:False ---------------------------------------------------遍历(集合是无序的) # 第一种方法 my_string = {"苹果","梨子","香蕉","橘子","榴莲","李子","板栗"} # 使用for循环遍历字符串 for i in my_string: # 打印每个字符 print(i) # 第二种方法 my_string = {"苹果","梨子","香蕉","橘子","榴莲","李子","板栗"} # 使用iter()函数获取集合的迭代器 set_iterator = iter(my_string) # 使用迭代器遍历集合中的元素 while True: try: item = next(set_iterator) print(item) except StopIteration: break
集合生成式
# 集合生成式 l = ['康师傅_老坛酸菜', '统一_老坛酸菜', '大今野_老坛酸菜', '白象'] res = {name for name in l} print(res, type(res))
6.程序控制结构
层级是空4个空格(在编译器里面Tab也可以)
代表false的
0
Null
空6.1 if选择结构
6.1.1 条件语句if 条件语句if else
if
if [条件]: [执行语句]if else
if [条件]: [执行语句] else: [执行语句]
举例
#判断是否是闰年 year=int(input("请输入年份:")) if year%400==0 or (year%100!=0 and year%4==0): print('该年分',year,"是闰年!") #print('%d' %year) else: print('该年分',year,"不是闰年!") #print('%d' %year)
6.1.2 嵌套语句
if [条件一]: if[条件二]: [语句A] else: [语句B] else: [语句C]
举例
#超过1000克的基本费用8元,= #超过的每多于500克 就收取4元超重费 #超过的不多于500克的部分,按照500克的收费来算 #如果加急就多收5元 s=8 k=int(input("请输入背包的重量:")) w=input("是否加急(加急y 不加急n):") if k>1000: #超过1000克,切剩下的部分可以被500整除 if (k-1000)%500==0: s+=(k-1000)//500*4 #超过1000克,但剩下的部分不可以被500整除 else: s+=((k-1000)//500+1)*4 #1表示不足500克的部分按照50克来计算 if w=='y': s+=5 #加急的费用 print("应该收取的费用为:",s,'元')
6.1.3 多条件判断if elif else
if [条件一]: [语句A] elif [条件二]: [语句B] elif [条件三]: [语句C] else: [语句D]
举例
# 三款笔记本:6元 5元 4元,一定的经费买最多的电脑 # 4 5 6 # 经费x y=x%4 # # 0 1 2 # k//4 n m #当前用户的钱数 x=int(input("请输入你的钱数:")) #k是购买笔记本总数 k=x//4 #是除法取下整操作,如果有余数代表没有达到买最多笔记本的要求 #y是剩余经费:所以可以取的值有(1 2 3) y=x%4 if y==0: m=n=0 elif y==1: m=0 n=1 k=k-1 elif y==2: m=1 n=0 k=k-1 elif y==3: m=1 n=1 k=k-2 print(m) #购买m本6元笔记本 print(n) #购买n本5元笔记本 print(k) #购买k本4元笔记本
6.2 循环结构
退出循环的方式
name = true/false
breake(本层): 立即退出本层循环,不会执行后面的循环
continue(本次):终止本次循环, 还会继续后面的循环6.2.1 for循环
in后面可以是:列表、字典(key)、字符串、元组、集合
num=[100,10,1000,99,66,1,88] for a in num: if a==max(num): print(a) print("它是最大的数") for b in range(1,10,2): #起 终 步长 print(b) 步长为负数 for b in range(1,10,-1): print(b) #不会有输出的 for b in range(10,1,-1): print(b) for...else:如果for循环中有break字段等,导致for循环没有正常执行完毕 那么else中的内容不会被执行 # 假设我们有一个列表,我们想要查找特定的元素 numbers = [1, 2, 3, 4, 5] # 我们想要查找数字3 for number in numbers: if number == 8: print("找到了数字3") break # 找到后退出循环 else: # 如果循环正常结束(即没有找到数字3),则执行这里的代码 print("没有在列表中找到数字3")
例题
1~10求和
sum = 0 for i in range(1, 11): sum += i print(sum)嵌套(九九乘法表)
# 会换行 print('\n') print() print('') # 不会换行 print(,end='') # 制表符print('\t') for i in range(1, 10): for j in range(1, i+1): print(f"{j}x{i}={j*i}", end="\t") print()水仙花数
#水仙花数 方法一:分别取出个十百位进行比较 for m in range(100,1000): a = m // 100 #b = (m % 100) // 10 #153 370 371 407 b=(m//10)%10 #153 370 371 407 c = m % 10 if a**3+b**3+c**3==m: print(m) #方法二:1~10之间的数进行遍历 for a in range(1,10): for b in range(10): for c in range(10): if a**3+b**3+c**3==a*100+b*10+c: print(a*100+b*10+c) #方法三:输入字符串 for i in range(100,1000): a = str(i) s = 0 for b in a: s += int(b)**3 if s == i: print(i)判断是否是质数
x = int(input('请输入您要判断的数字:')) s = 0 for i in range(1,x+1): if x%i==0: s+=1 if s==2: print('%d为质数' %x)x = int(input('请输入您要判断的数字:')) flag = True for i in range(2,x): if x%i==0: flag = False break if flag: print('%d为质数' %x)import math # 导入数学模块 x = int(input('请输入您要判断的数字:')) p = int(math.sqrt(x))+1 flag = True for i in range(2,p): if x%i==0: flag = False break if flag: print('%d为质数' %x)最大公约数
m = int(input()) n = int(input()) if m > n: i = n else: i = m for x in range(i,0,-1): #注意这里是(i,0) if m % x == 0 and n % x == 0: print(x) break#辗转相除法 # 36%24 12 # 24%12 0 m = int(input()) n = int(input()) while m%n!=0: c = m%n m = n n = c print(n) #这是最大公约数 print(m*n/n) #这是最小公倍数:两个数的乘积/最大公约数=最小公倍数最小公倍数
m = int(input()) n = int(input()) if m > n: j = m else: j = n while True: if j%m == 0 and j%n == 0: print(j) break j+=1龙腾数:各个位数之和等于5
for i in range(1000): a=str(i) s=0 for b in a: s+=int(b) if s==5: print(i)
6.2.2 while循环
while语句
while可以自己嵌套
a=input("请请输入你的成绩:") a=int(a) while a > 90: print("优秀")
例题
1~10求和
sum = 0 i = 1 while i <= 10: sum += i i += 1 print(sum)求n个1992的乘积的末两位
#求n个1992的乘积的末两位 # s i # 1 1 # s*1992 s%100 # 1992 92 2 # 183264 64 3 # 127488 88 4 #第一种方法:原始的 n=int(input("请输入n:")) i=1 s=1 while i<=n: s=s*1992 i=i+1 print(s%100) #第二种:更加精妙 n=int(input("请输入n:")) i=1 s=1 while i<=n: s=s*1992 #这样s始终只包含最后两位数字 s=s%100 #为了防止数过大,因为只有最后两位数会影响结果 i=i+1 print(s)把一个数倒序输出:输入726 输出627
# 把一个数倒序输出:输入726 输出627 # # r num # 6 72 # 60+2=62 7 # 620+7=627 0 num=int(input("请输入一个数:")) r=0 while num>0: #r * 10:在下一步将num的最后一个数字添加到r的末尾6*+2=62 62*10+7=627 #num % 10:使用模运算%来获取num的最后一个数字 #获取最后一个数6 2 7 r=r*10+num%10 #移除num的最后一个数字 #移除最后一个数6 2 7 num=num//10 print(r)1~100的奇数
#1~100的奇数 #第一种:传统方法 i=1 while i<=100: if(i%2!=0): print(i) i+=1 #第二种:算法 #1 2 3 4 5 #1 3 5 7 9 i=1 while i<=50: print(2*i-1) i+=1 #第三种:for方法 for i in range(1,101,2): print(i)求最大公约数
#求最大公约数 #方法一 m = int(input('请输入第1个数')) n = int(input('请输入第2个数')) if m > n: t = m m = n n = t x = m while True: if m%x==0 and n%x==0: print('%d和%d的最大公约数为%d' %(m,n,x)) break x -= 1 #方法二 m = int(input('请输入第1个数')) n = int(input('请输入第2个数')) if m > n: t = m m = n n = t x = m while m%x!=0 or n%x!=0: x -= 1 print('%d和%d的最大公约数为%d' %(m,n,x))m可以被19整除 且 m里面含有k个3
#m可以被19整除 且 m里面含有k个3 #方法一:个位截取判断 m = int(input('请输入第一个正整数')) k = int(input('请输入第二个正整数')) n = m s = 0 while n: t = n%10 if t==3: s+=1 n//=10 if m%19==0 and s==k: print("YES") else: print("NO") #方法二:字符串判断 str = input('请输入一个字符串') k = int(input('请输入需要的3的个数')) i = 0 cnt = 0 while i < len(str): if str[i] == '3': # 依次取出每个字符进行比较 cnt += 1 i += 1 if int(str)%19 == 0 and cnt == k: print('YES') else: print('NO')嵌套4位完全平方
#4位完全平方数 x=1 while True: n=x*x x=x+1 if n<1000: continue if n>9999: break high=n//100 low=n%100 #7744 # 7 7 4 4 if high//10==high%10 and low//10==low%10: print(n)
while else语句
while true: ... else: ...
6.3 三元表达式
之前的方法 def func(x, y): if x > y: return x else: return y 三元表达式: 条件成立时返回的值 if 条件 else 条件不成立时返回的值 res=x if x > y else y print(res)
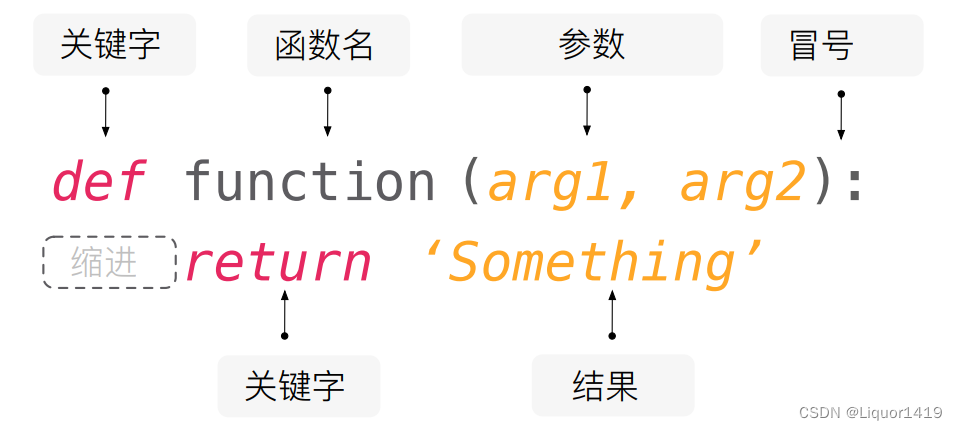
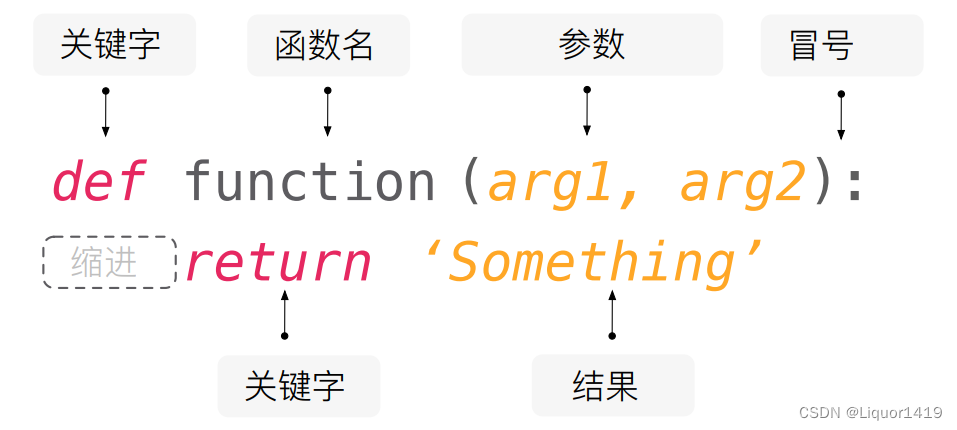
7.函数def
7.1 基本语法
函数def的全称是define/definition,意为“定义
封装函数 def 函数名(参数1,参数2,...): ''' 函数描述(可以不写) ''' 函数体 #不写就是没有返回值 return是函数结束的标志 return 值 -------------------------------------------------------------------- 调用函数 #无参 函数名() #有参 接收变量=函数名(参数1,参数2,...) print(接收变量) -------------------------------------------------------------------- 参数 形参(封装函数定义的数据): def sum(a,b,c) 形参没有实际的值,被赋值后才有意义 形参可以有0~n个,根据实际需求给 实参(当调用函数时的数据):sum(1,2,3) 实际参数可以是变量,也可以是常量 必选参数/位置参数:一定要传参的函数 可选参数/位置参数:是不定长的参数,加上“ * ” 这个形式参数里面存放了所有未命名的形式参数 这个形式参数的类型是一个元组() 里面传输的数据不一定全是一种类型的 def getComputer(*args): print(args) getComputer(2,3,4) getComputer(1,2,3,4,5,6) 关键字参数:是不定长的参数,用“ ** ”来声明 参数是一个字典类型(key=value) 参数的key值必须是一个字符串 def keyFunc(**kwargs): print(kwargs) dicta={"姓名":"小明","年龄":25} keyFunc(**dicta) keyFunc(name="zhangsan",age=66) 默认形参/缺省形参:def sum(a,b,c=3) 默认参数必须放在定义参数之后 如果给定了实际参数,那么会覆盖参数的默认值 可以混合使用:不一定非要用args和kwargs的名字 可选参数必须放在参数之前 def complexFunc(*args,**kwargs): print(args) print(kwargs) complexFunc() complexFunc(1,2,3) complexFunc(1,2,3,name="peter",age=35) 举例 接收溢出的参数:放在位置参数和默认参数之后 可变长度的位置参数:元组 def func(x,y,*z) def func(*z) def func(*args) 形参:def func(x,y,*args) func(1,2,3,4,5) 实参:def func(x,y,z) func(*[1,2,3]) 可变长度的关键字参数:字典 **形参名 **kwargs 形参:def func(x,y,**kwargs) func(1,2,3,4,5) 实参:def func(x,y,z) func(**{'x'=1,'y'=2,'z'=3}) 混用 def func(**args,**kwargs): print(args) #空元组 print(kwargs) #空字典 func(1,2,3,a=4,b=5,c=6) 运行结果(1,2,3) {'a'=4,'b'=5,'c'=6} 或者:def func(x,y=7,**args,**kwargs) 函数参数的类型提示(3.5以后) def func(name: str, age: int=88) -> int: print(name) print(age) return 10 -------------------------------------------------------------------- 返回值return 返回类型:取决于return后面的类型 在那个地方调用函数,返回值就返回到那个地方 在一个函数体内可以出现多个return值:但是肯定只能返回一个return 函数体内执行了return:意味着函数执行完成退出了,return后面的代码将不会执行 return可以返回多个值:多个值以元组的数据类型返回 如果函数内部没有return关键字:返回的结果是None #有return def sum(a,b): s=a+b return s sum(12,13) #含有return是有返回值的 t=sum(12,13) print(t) #25 #没有return def sum(a,b): s=a+b print(s) sum(12,13) #25:没有返回值 t=sum(12,13) #25 print(t) #None:函数返回值 -------------------------------------------------------------------- 全局变量:如果想修改局部变量为全局变量,前面加 global 局部变量 当全局变量和局部变量重名时:有先使用局部变量 age="今年18岁了" #全局变量 def printname1() name="liuxinlei" #局部变量 print(name,age) def printname2() name="yuhuashi" #局部变量 print(name,age) printname1() printname2()#定义函数 def changeme( mylist ): "修改传入的列表" mylist.append([1,2,3,4]) return #调用函数 mylist = [10,20,30] changeme( mylist ) print("函数外取值: ", mylist)
7.2 内置/内建函数
进制相关的函数 十进制转二进制:bin() 十进制转八进制:oct() 十进制转十六进制:hex() #不一定是int其他类型也可以 二进制转十进制:int(,2) 八进制转十进制:int(,8) 十六进制转十进制:int(,16) 相关函数 bool函数:得到的结果只有两种,要么是真True代表成立,要么是假False代表不成立 a=0 a=None a="" print(bool(a)) b-30 a='hello' print(bool(b)) float函数:能够把字符串或者数字转成浮点数 int函数:能够将传入的参数转换成整数类型 len函数:求字符串、列表、元组等的长度或元素个数 del函数:删除(没有返回值) sorted函数:用来排序,可以是升序(默认),也可以是降序 list1=[2,3,8,4,5,6] list2=sorted(list1,reverse=True) #reverse=True可以修改为降序 print(list2) choice函数:从一个列表中抽取一个元素 ord函数:接受一个字符,返回一个字符的 Unicode码点 print(ord('A')) chr函数:接受一个整数,并返回相应的字符 print(chr(65)) id()函数:返回对应的id号 type()函数:查看对应的类型 is()函数:判断id是否相同 数学函数 pow函数:求a的b次方 x=pow(2,3) print(x) #8 abs函数:绝对值 x=abs(-5) print(x) #5 divmod函数:同时取商和余数,返回的数据是元组类型 a=10 b=3 print(divmod(a,b)) #(3,1) sum函数:求和 li=[1,3,5,7,9] print(sum(li)) #25 round函数:可以四舍五入保留小数位数,第二个参数代表保留一位小数 x=70.268 print(round(x,1)) #输出的结果为70.3 max函数:最大值 li=[5,3,,99,2,0] print(max(li)) #99 min函数:最小值 li=[5,3,99,2,0] print(min(li)) #0
7.3 封装函数
def sum(a, b): return a + b a = int(input("请输入a:")) b = int(input("请输入b:")) he=sum(a, b) print(he)
7.4 闭包函数
# 闭函数:闭,封闭的意思,函数被封闭起来的 # 包函数:函数内部包含对外层函数作用域名字的引用 def outer_function(x): def inner_function(y): return x + y return inner_function closure = outer_function(10) print(closure(5)) # 输出 15
7.5 装饰器property
允许你修改或增强函数、方法或类的行为
# 装饰器:不修改被装饰对象的源代码,也不修改调用方式的前提下,给被装饰对象添加新的功能 import time def inside(group, s): print('欢迎来到王者荣耀') print(f'你出生在{group}方阵营') print(f'敌军还有{s}秒到大战场') time.sleep(s) print('全军出击') ... inside('红色', 5) inside('蓝色', s=3)使用装饰器之后(偷梁换柱)
import time #游戏 def inside(group, s, z): print('欢迎来到王者荣耀') print(f'你出生在{group}方阵营') print(f'敌军还有{s}秒到大战场') time.sleep(s) print(f'{z}出击') #电量 def recharge(num): for i in range(num, 101): time.sleep(0.05) print(f'\r当前电量:{"▉"*i} {i}%', end='') print('电量已充满!') return 100 #装饰器 def outer(func): # func = inside def wrapper(*args, **kwargs): start = time.time() response = func(*args, **kwargs) end = time.time() print(end-start) return response return wrapper recharge = outer(recharge) #外到内 res = recharge(20) print(res) inside = outer(inside) #外到内 inside('蓝色', s=3, z='炮车')
7.5.1 无参装饰器
模板
def outer(func): def wrapper(*args, **kwargs): res = func(*args, **kwargs) return res return wrapper举例
def auth(func): def wrapper(*args, **kwargs): name = input('请输入账号>>>').strip() pwd = input('请输入密码>>>').strip() if name == 'jack' and pwd == '123': res = func(*args, **kwargs) return res else: print('账号或密码错误!') return wrapper @auth def home(): """这是主页2""" time.sleep(2) print('welcome')
7.5.2 有参装饰器
模板
def g_outer(x): def outer(func): def wrapper(*args, **kwargs): res = func(*args, **kwargs) return res return wrapper return outer举例
import time def g_outer(name,age): def outer(func): def wrapper(*args, **kwargs): #比如 print(name,age) res = func(*args, **kwargs) return res return wrapper return outer @g_outer('张大仙', 18) # @outer home = outer(home) home = wrapper def home(): """这是主页2""" time.sleep(2) print('welcome') @g_outer('李白', 19) def index(): pass home() index()
7.5.3 装饰器叠加
当使用多个装饰器时,它们会按照从内到外(从下到上)的顺序应用,但执行时是从外到内(从上到下)
# 装饰器叠加使用 def outer1(func1): def wrapper1(*args, **kwargs): print('开始执行outer1.wrapper1') res1 = func1(*args, **kwargs) # func1 = 原home print('outer1.wrapper1执行完毕') return res1 return wrapper1 def outer2(x): def outer(func2): def wrapper2(*args, **kwargs): print('开始执行outer2.wrapper2') res2 = func2(*args, **kwargs) # func2 = outer1.wrapper1 print('outer2.wrapper2执行完毕') return res2 return wrapper2 return outer def outer3(func3): def wrapper3(*args, **kwargs): print('开始执行outer3.wrapper3') res3 = func3(*args, **kwargs) # func3 = outer2.wrapper2 print('outer3.wrapper3执行完毕') return res3 return wrapper3 #顺序结论:先被装饰对象头顶上的装饰器 1——>2——>3 @outer3 # home = outer3(home) # outer3.wrapper3 @outer2(10) # outer = outer2(10) => @outer => home = outer(home) # outer2.wrapper2 @outer1 # home = outer1(home) # outer1.wrapper1 def home(z): print('执行home功能', z) return '张大仙' res = home(0) print(res) # 执行运行结果 # 开始执行outer3.wrapper3 # 开始执行outer2.wrapper2 # 开始执行outer1.wrapper1 # 执行home功能 0 # outer1.wrapper1执行完毕 # outer2.wrapper2执行完毕 # outer3.wrapper3执行完毕 # 张大仙
7.6 语法糖@
import time def count_time(func): # func = inside def wrapper(*args, **kwargs): start = time.time() response = func(*args, **kwargs) end = time.time() print(end-start) return response return wrapper @count_time # inside = outer(inside) def inside(group, s, z): print('欢迎来到王者荣耀') print(f'你出生在{group}方阵营') print(f'敌军还有{s}秒到大战场') time.sleep(s) print(f'{z}出击') @count_time #recharge = outer(recharge) def recharge(num): for i in range(num, 101): time.sleep(0.05) print(f'\r当前电量:{"▉"*i} {i}%', end='') print('电量已充满!') return 100 # inside = outer(inside) # recharge = outer(recharge) inside('红色', 3, '炮车') recharge(50)完美伪装
from functools import wraps import time def outer(func): def wrapper(*args, **kwargs): res = func(*args, **kwargs) return res return wrapper def auth(func): @wraps(func) def wrapper(*args, **kwargs): name = input('请输入账号>>>').strip() pwd = input('请输入密码>>>').strip() if name == 'jack' and pwd == '123': res = func(*args, **kwargs) return res else: print('账号或密码错误!') # wrapper.__name__ = func.__name__ # wrapper.__doc__ = func.__doc__ return wrapper @auth def home(): """这是主页2""" time.sleep(2) print('welcome')
7.7 递归函数
在调用一个函数的过程中,又调用到了自己本身这个函数
# 计算1到10的和 原始方法 i = 100 total=0 while i>0: total+=i i-=1 print(total) 递归1 def recursive_sum(i, total=0): if i == 0: return total #出口 else: return recursive_sum(i - 1, total + i) res = recursive_sum(100) print(res) 递归2 i = 100 def my_sum(i): if i == 0: #出口 return i return i + my_sum(i - 1) res = my_sum(i) # 10 + 9 + 8 + .....+1 + None print(res)举例
要求:把下面列表的每一个值单独打印出来 l = [1, 2, [3, [4, [5, [6, [7, [8, [9, [10, [11, 12]]]]]]]]]] l = [1, 2, [3, 4]] def func(li): for i in li: if type(i) is list: func(i) else: print(i) func(l)
7.8 匿名函数lambda
不用def关键字创建的函数,可以使用lambda(λ)关键字创建匿名函数
基本格式:lambda 参数1,参数2,参数3:执行代码语句 参数不一定只有3个,可以是1-n个 匿名函数冒号后面的表达式有且仅有一个 只能是单个表达式,不是一个代码块 设计出来是为了满足简单函数的场景,仅能封装有限的逻辑(复杂的用def) # 有名函数(需要重复调用) def func(x, y): return x + y # 匿名函数(临时调用一次) res = (lambda x, y=1: x + y)(1) print(res) #x=1 y=1 # func = lambda x, y=1: x + y # res = func(1) # print(res) ------------------------三元表达式 if...else.... if a: b else: c b if a else c ------------------------lambda函数和三元结合 greater=lambda x,y:x if x>y else y print(greater(3,5)) print((lambda x,y:x if x>y else y)(3,5))
举例
一个简单的加法函数
add = lambda x, y: x + y print(add(3, 5)) # 输出 8一个判断数字是否为偶数的函数
is_even = lambda x: x % 2 == 0 print(is_even(4)) # 输出 True print(is_even(5)) # 输出 False在
sorted函数中使用lambda函数进行排序words = ['apple', 'banana', 'cherry', 'date'] sorted_words = sorted(words, key=lambda x: len(x)) print(sorted_words) # 输出 ['date', 'apple', 'cherry', 'banana']利用 jieba 库进行词频统计,输出出现 次数前三的词汇
import jieba txt=input("请输入文本:") #天气晴朗,我很开心,弟弟也很开心,妹妹也很开心,妹妹平常很爱哭 words=jieba.lcut(txt) counts={} for word in words: if len(word)==1: #如果当前词的长度为1,则跳过当前循环,继续下一个循环 continue else: counts[word]=counts.get(word,0)+1 #获取word在counts字典中的值(如果有的话),如果没有则默认为0 items=list(counts.items()) #指定一个 key 函数,这个函数接收一个参数 x,并返回 x 的第二个元素 items.sort(key=lambda x:x[1],reverse=True) #排序的关键是元组的第二个元素(即词频),且是降序排序 #在这里,x 是 counts.items() 返回的元组,每个元组包含一个词和它的词频 for i in range(3): #遍历列表items的前三个元素 word,count=items[i] #解构元组,将词和其词频分别存储在word和count变量中 print(word,count)
8.引入模块Module
是什么?模块就是一系列功能的结合体 它类似于生活中的工具箱,模块封装了很多的函数,这些函数我们可以直接拿来使用 模块的分类 内置模块:用家里现有的工具箱,维修东西 第三方模块:去买一些工具箱回来,方便使用(需要自己安装 pip install 库名) 自定义模块:自己做一些工具,然和把工具都放到工具箱里面去 安装库 在终端里面输入(视图——>工具窗口——>终端):pip install 库名 导入 import 模块名 from 模块名 import 模块中的函数或者属性 引用 import statistics print(statistics.median([111,125,134,129])) #统计数组元素的中位数 print(statistics.mean([111,125,134,129])) #对所有元素求均值 from statistics import median,mean print(median([111,125,134,129])) print(mean([111,125,134,129])) from statistics import* print(median([111,125,134,129])) print(mean([111,125,134,129])) 注意事项 模块名.名字:是指名道姓的问某一个模块中名字对应的值,不会与当前名称空间中的名字发生冲突 导入多个模块的时候,可以合并在一起写:import a,b,c,d 可以对导入模块起别名,但原来的模块名就不能用了:import mk as haha 自定义的模块名:纯小写+下划线的风格 在自定义函数内导入模块:只不过模块的功能只能在函数内部使用
常用模块
import math math.gcd(12,8) 求两个数的最大公约数 math.sqrt(64) 求某个数的平方根 math.pi 圆周率pi math.ceil(5.2) 返回大于或等于x的最小整数 math.floor(5.2) 返回小于或等于x的最大整数 math.pow(x,y) 返回x的y次方 import time time() 返回从1970年1月1日0点整到现在过了多少秒 time.localtime() 返回的时间格式有点奇怪 time.asctime() 获取字符串格式类型的时间 sleep(数字) 暂停的秒数 import calendar #日历 calendar.month(2023,2) 可以打印某月的字符日历 import fractions #分数 fractions.Fraction(分子,分母) 分数运算,还可以自动约分 fractions.Fraction(小数) 将小数转化为分数 import datetime #封装了和日期、时间有关的函数和类 datetime.date.today() 生成当前日期 datetime.date.fromtimestamp(time.time()) 时间戳换成具体日期 datetime.date.min 最小日期 datetime.date.max 最大日期 datetime.date.resolution 表示日期的最小单位,这里是1天 d=datetime.date.today() d.year 年 d.month 月 d.day 日 d.weekday() 0代表周一、6代表周日 d.isoweekday() 1代表周一、7代表周日 d.isoformat() 输出标准的日期格式:xxxx-xx-xx d.strftime("%Y年%m月%d日") 自定义日期格式 d.toordinal() 计算从0001-01-01到现在的天数 d.timetuple 将date对象转换为结构化时间对象 d.replace(2024) 替换年份 d.replace(d.year,3) 替换月份 d.replace(day=20) 将日期修改为20号 d.replace(second=57,day=20) 修改秒和日期 t.datetime.time(10:10:10:666) t.type(t) 输出指定的时间 t.ispfromat() 输出标准的时间格式 t.strftime("%H时%s秒%f微妙") 自定义时间输出格式 t.hour t.minute t.second t.microsecond datetime.min 最小 datetime.max 最大 datetime.time.resolution 时间最小单位为1微妙 dt=datetime.datetime(2024,4,23,0,16,29,29) print(dt,type(dt)) 生成日期时间 dt=datetime.datetime.today() print(dt,type(dt)) 获取当前时间 dt=datetime.datetime.now(tz=None) None默认就是你当前所在的时区 print(dt,type(dt)) 指定时区的当前时间 dt=datetime.datetime.utcnow() 获取utc(时间协调时间)的时间 print(dt,type(dt)) 北京时间=UTC+8:00 import datetime 时间戳换成时间对象 import time dt=datetime.datetime.fromtimestamp(time.time()) print(dt,type(dt)) import datetime 当前时间戳生产utc时间 import time dt=datetime.datetime.utcfromtimestamp(time.time()) print(dt,type(dt)) import datetime 字符串生成日期对象 dt=datetime.datetime.strptime("2024-04-23 13:12:56","%Y-%m-%d %H:%M:%S") print(dt,type(dt)) impport datetime date,time对象结合在一起生产datetime对象 d=datetime.date.today() t=datetime.time(15,10,45,666) dt=datetime.datetime.combine(d,t) print(dt,type(dt))随机数: import random 随机数范围(包括 a 和 b 在内的随机整数):random.randrange(a,b,step) 生成区间之内的整数:random.randint(a,b) 随机小数个数:import numpy as np库 生成5个随机小数:np.random.randn(5) 0~1随机小数:random.random() 括号中不传参 random.sample(population, k) 作用:用于从 population(一个序列或集合)中随机选择 k 个不重复的元素 返回:返回的是一个包含这 k 个随机选择元素的列表 population:一个可迭代对象,表示你要从中抽取元素的总体 可迭代对象(如列表、元组等)中随机抽取指定数量的不重复元素(需要自己提供不重复的) k:一个整数,表示你想要抽取的元素数量 random.choice():从一个序列中随机选择一个元素 这个序列可以是字符串、列表、元组等等,但是不能是集合和字典 random.shuffle(列表名):随机打乱列表的顺序,原列表发生变化pip install jieba #分词工具 pip list #查看已经安装了的模块 分词模式 精确模式(默认cut):试图将句子最精确的切开,适合文本分析 全模式(cut_all=True):把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适用于搜索引擎分词 paddle模式:使用飞桨(PaddlePaddle)深度学习框架加速分词的一种模式 举例 import jieba x=jieba.cut("我是小明") #返回值:可迭代的generator生成器 print(list(x)) x=jieba.lcut("我是小明") #返回值:以list的形式返回分词后的结果 print(x)
四:语法进阶
1.OOP面向对象
面向过程:把程序流程化 OOP面向对象:对象就是“容器”,用来存储数据和功能 主要内容:封装、继承、多态 类是创建对象的模板,对象是类的实例 类是抽象的,对象是具体的 对象:万物皆可对象 类class:由属性和行为构成;现有对象,对象的共有特点被抽象成类的概念 具有相同属性和方法的对象归为类 类的作用:存放对象共有的数据和功能 --------------------------------------------------------------------------- __init__:这个功能在类被调用的时候自动执行 隐藏:其实根本没有做到真正的隐藏就是改名字,就是在对象名的前面加了一个“_”;对外不对内就是访问权限 隐藏属性:__x=10 #注意这里是两个下划线 隐藏函数:def __f1(self) 对象输出函数__str__ class Person: def __init__(self,name,age): self.__name = name self.__age = age def __str__(self): #对象输出函数 return self.__name + ' ' + str(self.__age) p1 = Person("小红",17) print(p1)
1.1 创建类class
class CuteCat: def __init__(self,cat_name,cat_age,cat_color): #构造属性 self.name=cat_name self.age=cat_age self.color=cat_color def speak(self): #构造方法 print("喵"*self.age) def think(self,context): print(f"小猫{self.name}在考虑吃{context}") cat1=CuteCat("花花",3,"橘色") #创建对象 cat1.think("吃鱼") print(f"小猫名{cat1.name}的年龄是{cat1.age}它的颜色为{cat1.color}") #获取对象的属性 cat1.speak()class Student(): def __init__(self,name,age,grade,score): self.name = name self.age = age self.grade = grade self.score = score def study(self): print('我是%s 我正在学习……' %self.name) s1 = Student("大毛",12,"六年级",90) s2 = Student("二毛",9,"三年级",93) s3 = Student("小明",7,"一年级",100) # s1.study() # print(s1.name) # print(s1.age) print(s1.name,s1.grade) print(s2.name,s2.grade) print(s3.name,s3.grade)class Monster: def __init__(self, name, hp, lv): # 姓名 self.name = name # 血量 health point self.hp = hp # 等级 level self.lv = lv def get_info(self): s = self.name + ' ' + str(self.hp) + ' ' + self.lv return s def set_hp(self,hp): #self.hp = hp if hp>=0: self.hp = hp def modify_hp(self,hp): self.hp += hp if self.hp<0: self.hp = 0 m1 = Monster("小蓝", 95, "1级") # 输出m1对象的name属性 print(m1.name) # 输出m1对象的hp属性 print(m1.hp) # 输出m1对象的lv属性 print(m1.lv) m1 = Monster("小蓝", 95, "1级") #对象 # 输出m1对象的相关描述信息 print(m1.get_info()) m1.lv = '2级' #属性 print(m1.get_info()) m1.lv = '3级' #属性 # 小怪兽的血量减少 m1.set_hp(90) #方法 print(m1.get_info()) m1 = Monster("小蓝", 95, "1级") print(m1.get_info()) m1.modify_hp(10) #通过方法增加/减少特定的值 print(m1.get_info()) m1.modify_hp(-5) print(m1.get_info())
1.2 封装性
将对象的属性和行为封装起来,不需要让外界知道具体的实现细节
class Monster: def __init__(self,name,hp,lv): # 姓名 self.name = name # 血量 health point self.__hp = hp #私有属性 # 等级level self.lv = lv def get_info(self): s = self.name + ' ' + str(self.__hp) + ' ' + self.lv return s # get方法(获取属性值) def get_hp(self): return self.__hp #在类的内部可以访问到私有属性 # set方法(设置属性值) def set_hp(self,hp): self.__hp = hp m1 = Monster('小蓝',95,"1级") #print(m1.__hp) #因为hp是私有属性,在类的内部,无法访问 # get_hp获取m1对象的血量值 print(m1.get_hp()) #通过et_hp方法,访问了对象的私有属性 # 修改m1对象的血量值 m1.set_hp(90) print(m1.get_hp())
1.3 继承性
主要描述的是类与类之间的关系,通过继承,可以在无需重新编写原有类的情况下,对原有类的功能进行扩展
class Person: def __init__(self, name, age): self.__name = name self.__age = age def get_info(self): print('我是父类,姓名:%s,年龄:%s' %(self.__name,self.__age)) def get_name(self): return self.__name def set_name(self, name): self.__name = name def get_age(self): return self.__age def set_age(self, age): self.__age = age class Teacher(Person): #继承父类 def __init__(self,name,age,position): # super()用于调用父类的方法 super().__init__(name,age) #利用父类的方法初始化子类对象的属性:实现了代码复用的功能 self.__position = position class Student(Person): #继承父类 def __init__(self,name,age,major): # super()用于调用父类的方法 super().__init__(name,age) self.__major = major t1 = Teacher('陈玲',35,'班主任') t1.get_info() s1 = Student('小明',20,'软件工程') s1.get_info()class employee: #父类(职工) def __init__(self,name,id): self.name=name self.id=id def print_info(self): print(f"员工的名字:{self.name},工号:{self.id}") class fullTimeEmployee(employee): #继承(全职员工) def __init__(self, name, id,monthly_salary): super().__init__(name, id) self.monthly_salary=monthly_salary def monthly_pay(self): return self.monthly_salary class partTimeEmployee(employee): #继承(兼职员工) def __init__(self, name, id,daily_salary,work_days): super().__init__(name,id) self.daily_salary=daily_salary self.work_days=work_days def monthly_pay(self): return self.daily_salary*self.work_days #创建对象 zhangsan=fullTimeEmployee("张三","001",6000) lisi=partTimeEmployee("李四","002",4000,15) #调用输出 zhangsan.print_info() lisi.print_info() print(zhangsan.monthly_pay()) print(lisi.monthly_pay())
1.4 多态性
在程序中允许出现重名的现象,它指在一个类中的属性和方法被其它类继承后,它们可以具有不同的数据类型或表现出不同的行为
这使得同一个属性和方法在不同的类中具有不同的语义
class Person: def __init__(self, name, age): self.__name = name self.__age = age def get_info(self): print('我是父类,姓名:%s,年龄:%s' %(self.__name,self.__age)) def get_name(self): return self.__name def set_name(self, name): self.__name = name def get_age(self): return self.__age def set_age(self, age): self.__age = age class Teacher(Person): def __init__(self,name,age,position): # super()用于调用父类的方法 super().__init__(name,age) self.__position = position def get_info(self): print('我是一名教师,名字:%s,年龄:%s,职位:%s' %(super().get_name(),super().get_age(),self.__position)) class Student(Person): def __init__(self,name,age,major): # super()用于调用父类的方法 super().__init__(name,age) self.__major = major def get_info(self): print('我是一名学生,名字:%s,年龄:%s,专业:%s' %(super().get_name(),super().get_age(),self.__major)) t1 = Teacher('陈玲',35,'班主任') t1.get_info() s1 = Student('小明',20,'软件工程') s1.get_info()
2.文件
磁盘目录:cd cd~ cd- cd. cd.. cd/ cd./ cd../.. cd!$ cd /home的区别
计算机文件:就是存储在某种长期存储设备上的一段数据
2.1 操作模式 和 内容模式
控制文件读写操作的模式:默认r读模式 a=open("./data.txt","r",encoding="utf-8") #相对路径 r:读(默认) b=open("/usr/demo/data.txt","w") #绝对路径 w:写(没有会创建,有会覆盖) a:附加追加到内容最后 +:r+ w+ a+ x:只写模式,不可读 文件不存在就创建,存在就报错 控制文件读写内容的模式:默认t模式 t(文字):读写都是以字符串为单位的 b(图片 视频 文字):bytes/二进制模式 可以不定义编码模式encoding="utf-8" 但它本身是utf-8的二进制形式 读 with open('data/a.txt' mode='rb') as f res=f.read() #print(res,type(res)) print(res.decode('utf-8')) 写 with open('data/h.txt' mode='wb') as f f.write('哈哈哈'.encode('utf-8'))
2.2 文件操作基本流程步骤
文件的基本操作:打开文件——> 读/写文件——> 关闭文件
第一步:打开文件open f=open('data/a.txt',mode='rt',encoding="utf-8") print(f) 第二步:操作文件(读read 写write) res=f.read() print(res) 第三步:关闭文件 close f.close() with open('data/a.txt',mode='rt',encoding="utf-8") as a: print(a.read())
2.3 内置函数
f.readable()判断文件是否可读 f.writable()判断文件是否可续 f.closed判断文件是否关闭 f.encoding获取当前编码方式,如果文件打开模式为b,则没有改属性 f.name获取当前文件名 文件指针:用于改变文件指针的位置,来读取或写入文件的特定部分 文件指针读取:f.seek(n偏移量,参照位置) 0 或 os.SEEK_SET:头位置 1 或 os.SEEK_CUR:当前位置 2 或 os.SEEK_END:末尾位置 2和1只能在b模式下使用 获取指针当前位置:f.tell()
2.4 文件操作
2.4.1 read读文件r操作
print(a.read(10)) #读取多少字节 print(b.readline()) #读取一行的内容 print(b.readlines()) #读取全部文件内容 #关闭文件 a.close() #第一种方法 with语法:上下文管理器(后面可以些多个文件语法) with open("./data.txt") as a: #第二种方法:执行完就会自动关闭 print(a.read())举例
#read file = open('C:/test/test1.txt',encoding="utf-8") text = file.read() print(text) file.close() with open('C:/test/test1.txt',encoding="utf-8") as file: text = file.read() print(text) #逐行读取 with open('C:/test/test1.txt',encoding="utf-8") as file: for every_line in file: print(every_line) --------------------------------------------------------------- #逐行读取 #正常读取逻辑readline c=open("./data.txt","r",encoding="utf-8") line=c.readline() #读取第一行 while line !="": #判断当前行是否为空 print(line) #不为空则打印当前行 line=c.readline() #继续读取下一行 c.close() #关闭文件,释放资源 #多行读取 #正常读取逻辑readlines d=open("./data.txt","r",encoding="utf-8") lines=d.readlines() #把每行内容存储到列表里 for line in lines: #遍历每行内容 print(line) #打印当前行 c.close()
2.4.2 write写文件w操作
空文件写入数据 追加写入数据 #若文件不存在/空文件写入:就会自动创建这个文件 #若文件存在:会把里面的东西清空覆盖 with open("./data.txt","w",encoding="utf-8") as a: a.write("hello world!\n") 写入多行:不能够自己换行 with open('C:/test/test1.txt',mode='wt',encoding='utf-8') as f: f.write("111\n") f.write("222\n") f.write("333\n") f.write("444\n") with open('C:/test/test1.txt',mode='wt',encoding='utf-8') as f: f.writelines(['111\n','222\n','333\n',f'{str(444)}\n'])
2.4.3 删除文件操作
import os os.remove('文件路径') 修改文件名字 import os os.rename('以前','现在')
2.4.4 拷贝文件操作
old_path = input('请输入原文件路径>>').strip() new_path = input('请输入新文件路径>>').strip() #不希望字符串中的反斜杠被解释为转义字符 #在字符串前加一个 r 来表示 with open(fr'{old_path},mode=rb')as f1,\ open(fr'{new_path},mode=wb')as f2: #短数据 for line in f1: f2.write(line) #长数据 while 1: res=f1.read(1024) if not res: break f2.write(res)
2.4.5 修改文件内容操作
第一种修改文件内容的方式(文件编辑器修改文件的方式) with open('data/k.txt',mode='rt',encoding='utf-8')as f res=f.read() #间接的操作 #字符串转换为列表 l=list(res) l.insert(3.'不') #列表转换成字符串 new_res=''.join(l) #print(new_res) #直接的操作 new_res=res.replace('我喜欢你','我不喜欢你') #print(new_res) open ('data/.k.txt.swap',mode=wt,encoding='utf-8')as f1 f1.writw(new_res) 第二种修改文件内容的方式 import os with open('data/k.txt',mode='rt',encoding='utf-8')as f,\ open ('data/.k.txt.swap',mode=wt,encoding='utf-8')as f1: for line in f: res=line.replace('一天','一年') f1.write(res) os.remove('data/k.txt') os.rename('data/k.txt','data/.k.txt.swap')
2.4.6 监控文件数据操作
import time with open('data/user.log',mode='rb')as f: #控制文件指针跳到末尾 f.seek(0,2) while true: res = d.readline() if res: print(res.decode('utf-8'),end='') time.sleep(0.2) #等待延迟
2.4.7 统计文件字数操作
with open('data/user.log', mode='rt', encoding='utf-8')as f: #以前的方法 # size = 0 # for line in f: # size += len(line) # print(size) #从列表生成式——>列表生成器 #列表生成式 # print([len(line) for line in f]) #列表生成器方法 size = sum(len(line) for line in f) print(size)
3.异常
3.1 常见错误
一旦某条语句出现异常,那么这条语句后面的所有语句都无法执行,因为程序已经提前终止了 NameError:变量未定义 ZeroDivisionError:分母为零错误 IndexError:序列下标越界/索引错误 IndentationError:缩进错误 ImportError:导入模块错误 ArithmeticError:计算错误 ZeroDivisionError:分母为零错误 SyntaxError:语法错误 AttributeError:属性错误 ValueError:值错误 KeyError:键错误 AssertionError:断言错误 异常处理机制的完整格式 try: 可能出现错误(逻辑上)的代码块 except: 出错之后执行的代码 else: 没有出错的代码块 finally: 不管有没有出错都会执行的代码块
3.2 异常处理
--------------------------------------------- try: print(b) except NameError as msg: print(msg) print('到这里了') --------------------------------------------- try: print(1/0) except ZeroDivisionError as msg: print(msg) print('到这里了') --------------------------------------------- try: li=[1,2,34] print(li[10]) except IndexError as msg: print(msg) print('到这里了') --------------------------------------------- try: print(b) except IndexError as msg: print(msg) except NameError as msg: print(msg) print('到这里了')try: a=float(input("请输入1——100:")) b=float(input("请输入100——200:")) c=a/b except ValueError: print("你输入的数据不合理,无法转换成数字的字符串") except ZeroDivisionError: print("分母不能为零") except: print("程序发生错位,请检查后重新运行") else: #没有错误时运行 print("除法的结果为:"+str(c)) finally: #都会执行的程序 print("程序执行结束")
4.测试库unittest
#断言 assert 表达式 #单元测试库 import unittest #测试代码和写的功能分文件写来进行测试 import unittest from filename1 import sum class TestMyclass(unittest.TestCase): def setUp(self): self.renyi=renyi("hello world") #都会执行的 def test_x(self): assert sum(1,2)==3 def test_y(self): self.assertEqual(sum(2,8),10) #assert a=b assertNotEqual def test_z(self): self.assertTrue(a) #assert a is true assertFalse def test_n(self): self.assertIn(a,b) #assert a in b assertNoIn #终端运行(视图——>工具窗口——>终端):python -m unittest #会返回运行了几个测试、每一个点代表一个测试通过(没有通过有一个点就会变成F)
五:图形化GUI库
1.Easygui
easygui 是一个用于 Python 的简单图形用户界面(GUI)模块 它提供了一个简单的方式来创建对话框,而不需要深入了解复杂的 GUI 编程 easygui 特别适合快速原型设计、简单的脚本和工具,或者当你不希望花费大量时间学习复杂的 GUI 库时 需要安装 easygui:pip install easyguiimport easygui as eg # 显示一个简单的消息框 eg.msgbox("Hello, World!", "Greeting") # 显示一个输入框,并获取用户输入 user_input = eg.enterbox("Enter your name:", "User Input") print(f"Hello, {user_input}!") # 显示一个密码输入框 password = eg.passwordbox("Enter your password:", "Password Input") print(f"Your password is: {password}") # 注意:实际中不要这样做,因为这样会暴露密码 # 显示一个文件选择对话框,并返回选择的文件路径 file_path = eg.fileopenbox(msg="Choose a file", title="File Selector", default="*.txt") print(f"You chose the file: {file_path}") # 显示一个保存文件对话框,并返回选择的文件路径 save_path = eg.filesavebox(msg="Save file as", title="Save File", default="newfile.txt", filetypes=["*.txt", "*.py"]) print(f"You chose to save the file as: {save_path}") # 显示一个选择框,返回用户选择的按钮:它通常用于显示消息或确认框,而不是用于选择列表 choice = eg.buttonbox("Do you like Python?", choices=["Yes", "No"]) print(f"You chose: {choice}") #显示对话框并让用户从一组选项中选择一个 choices = ["选项1", "选项2", "选项3"] selected_choice = eg.choicebox("请选择一个选项:", "标题", choices=choices) if selected_choice is not None: print(f"您选择了: {selected_choice}") else: print("您取消了选择") #显示对话框并让用户从一组选项中选择多个 choices = ["选项1", "选项2", "选项3"] selected_choices = eg.multchoicebox("请选择一些选项:", "标题", choices=choices) if selected_choices: print(f"您选择了: {', '.join(selected_choices)}") else: print("您没有选择任何选项或取消了选择")
通过python的easygui实现电子商城 火锅店 午餐选择器
import easygui as eg # 定义午餐选项及其价格 lunch_options = [ {"name": "麻辣牛肉火锅", "price": 38.0}, {"name": "金汤肥牛火锅", "price": 42.0}, {"name": "酸菜鱼火锅", "price": 45.0}, {"name": "番茄牛肉火锅", "price": 40.0}, ] # 显示菜单并获取用户选择 title = "欢迎光临火锅店午餐选择器" msg = "请选择您想要点的火锅午餐:" # 从一个已有的列表(或其他可迭代对象)中创建一个新的列表 choices = [option["name"] for option in lunch_options] selected_choice = eg.choicebox(msg, title, choices) # 检查用户选择 if selected_choice: # 根据用户选择找到相应的午餐及其价格 for option in lunch_options: if option["name"] == selected_choice: selected_lunch = option break else: # 如果没有找到匹配项,则重置选择 selected_choice = None # 显示用户的选择和价格 if selected_choice: eg.msgbox(f"您选择了:{selected_lunch['name']}\n价格:{selected_lunch['price']}元", "确认选择") else: # 用户取消选择或关闭对话框 eg.msgbox("您取消了选择", "选择已取消")如果想选择多个
import easygui as eg # 定义午餐选项及其价格 lunch_options = [ {"name": "麻辣牛肉火锅", "price": 38.0}, {"name": "金汤肥牛火锅", "price": 42.0}, {"name": "酸菜鱼火锅", "price": 45.0}, {"name": "番茄牛肉火锅", "price": 40.0}, ] # 显示菜单并获取用户选择 title = "欢迎光临火锅店午餐选择器" msg = "请选择您想要点的火锅午餐(可多选):" choices = [option["name"] for option in lunch_options] selected_names = eg.multchoicebox(msg, title, choices=choices) # 检查用户选择 if selected_names: # 根据用户选择的午餐名称找到相应的午餐选项 selected_lunches = [ option for option in lunch_options if option["name"] in selected_names ] # 计算总价 total_price = sum(lunch["price"] for lunch in selected_lunches) # 显示用户的选择和总价 eg.msgbox(f"您选择了以下火锅午餐:\n{', '.join(lunch['name'] for lunch in selected_lunches)}\n总价:{total_price}元", "确认选择") else: # 用户取消选择或未选择任何选项 eg.msgbox("您未选择任何午餐", "选择已取消")
2.Tkinter
上课抽选学生回答问题的程序:点一次换一次
import tkinter as tk import random # 学生名单列表 students = ["学生A", "学生B", "学生C", "学生D", "学生E"] # 选择学生的函数 def select_student(): # 从学生列表中随机选择一个学生 selected_student = random.choice(students) # 在界面上显示被选中的学生 label.config(text=f"真幸运,被选中学生的学生是:{selected_student}") # 创建主窗口 root = tk.Tk() root.title("抽选学生回答问题") # 设置窗口的大小,格式为'宽度x高度' root.geometry("300x150") # 例如,设置为400像素宽和300像素高 # 设置窗口的背景颜色,格式为'#RRGGBB' root.configure(background='green') # 例如,设置为浅灰色 # 创建标签来显示被选中的学生 label = tk.Label(root, text="按下按钮来抽选学生", bg='#e0e0e0') # 设置标签的背景颜色 label.pack(pady=20) # 创建按钮来触发抽选学生的操作 select_button = tk.Button(root, text="抽选学生", command=select_student) select_button.pack() # 运行主循环 root.mainloop()上课抽选学生回答问题的程序:不停滚动,点击就暂停
import tkinter as tk import random import time # 学生名单列表 students = ["学生A", "学生B", "学生C", "学生D", "学生E"] # 标记是否应该滚动名字 should_scroll = True # 最后一次被选中的学生名字 last_selected_student = None # 滚动名字的函数 def scroll_student(): global should_scroll, last_selected_student if should_scroll: # 从学生列表中随机选择一个学生 selected_student = random.choice(students) # 更新最后一次被选中的学生名字 last_selected_student = selected_student # 在界面上显示被选中的学生 label.config(text=f"被选中的学生是:{selected_student}") # 每秒更新一次1000 root.after(10, scroll_student) # 选择学生的函数 def select_student(): global should_scroll should_scroll = not should_scroll if should_scroll: # 重新开始滚动名字 scroll_student() else: # 暂停滚动时,显示暂停时的名字 label.config(text=f"真幸运,选中的学生是:{last_selected_student}") # 创建主窗口 root = tk.Tk() root.title("抽选学生回答问题") # 设置窗口的大小 root.geometry("300x150") # 设置窗口的背景颜色 root.configure(background='green') # 创建标签来显示被选中的学生 label = tk.Label(root, text="点击按钮开始滚动", bg='#e0e0e0') label.pack(pady=20) # 创建按钮来触发抽选学生的操作 select_button = tk.Button(root, text="抽选学生", command=select_student) select_button.pack() # 开始滚动名字 scroll_student() # 运行主循环 root.mainloop()
3.Pygame
4.Turtle
六:算法
分治算法
分治算法:各个击破,分而治之 是什么?将原问题分解成若干个相互独立的与原问题性质相同的子问题 用同样的方法解决这些子问题并将这些子问题的解组合起来得到问题的解 原理?子问题还用相同的分治方法解,分治过程一直进行下去 直至问题的规模充分小,可直接解为止,一般用递归方式实现 三大步骤:——>分(Divide)递归解决小的问题 ——>治(Conquer)递归求解,如果问题够小直接求解 ——>合并(Combine)将子问题的解构成父类问题
二分查找/折半查找
#二分查找:low mid=(low+high)//2 high arr = [1, 3, 5, 7, 9, 11, 13, 15, 17] #有序的 def binary_search(key, left, right): print('数据查找下标范围:%d~%d' %(left,right)) if left > right: return None mid = (left + right) // 2 if key == arr[mid]: return 1 elif key > arr[mid]: return binary_search(key, mid + 1, right) #缩小问题规模 elif key < arr[mid]: return binary_search(key, left, mid - 1) #缩小问题规模 ans = binary_search(1, 0, len(arr)) #查找1 print(ans)
快速排序
#快速排序:通过元素之间的比较和交换来达到排序的目的 #左i(基准数) 右j #i向右边(>基准数) j向左边(<基准数) #【然后相互交换】 i=j结束完一轮 #在i=j的值与最开始的基准数进行交换 以此为分界点:左(<)右(>) a = [6,1,2,7,9,3,4,5,8,10] #无序 def quickSort(left, right): #left 和 right,分别表示要排序的数组区间的左右索引 if left >= right: #说明区间内没有元素或只有一个元素,无需排序,直接返回 return temp = a[left] #取区间最左边的元素作为临时值 temp #初始化两个指针 i 和 j,分别指向区间的最左边和最右边 i = left j = right #找到两个数交换 while i!=j: while a[j]>=temp and i<j: #从右向左找,找到第一个小于 temp 的元素 j-=1 while a[i]<=temp and i<j: #从左向右找,找到第一个大于 temp 的元素 i+=1 if i<j: #如果 i 仍然小于 j,则交换 a[i] 和 a[j] 【然后相互交换】 t = a[i] a[i] = a[j] a[j] = t #基准数归位:i=j相遇结束完一轮 a[left] = a[i] #将 temp(即原区间的最左边元素)放到正确的位置上(即 i 的位置) a[i] = temp #分治算法:对基准数两边的子序列进行排序 quickSort(left,i-1) quickSort(i+1,right) quickSort(0,9) #调用函数:左右索引 #遍历排序后的列表 a,并打印每个元素 for i in a: print(i,end=' ')
求列表中的最大值
def get_max(max_list): return max(max_list) # 当问题规模小于等于2时,直接使用max函数得出2个数的最大值 # list=[12, 6, 5956, 7, 8, 98, 46, 46, 4, 451, 9684, 4] # 分治算法 def solve(init_list): list_length = len(init_list) # 递归出口,若问题规模小于等于2,可以明显得出两者之间的最大值 if list_length <= 2: return get_max(init_list) # 通过切片截取下标为0~list_length//2(不包含list_length//2)的数据元素 left_list = init_list[:list_length//2] # 通过切片截取下标为list_length//2~list_length(不包含list_length)的数据元素 right_list = init_list[list_length//2:] # 找出下标0~list_length//2(不包含list_length//2)中的最大值 left_max = solve(left_list) # 找出下标包含list_length//2~list_length(不包含list_length)中的最大值 right_max = solve(right_list) # 比较left_max(左边序列最大值)和right_max(右边序列最大值)元素,找出两者的最大值 return get_max([left_max,right_max]) test_list = [12, 6, 5956, 7, 8, 98, 46, 46, 4, 451, 9684, 4] print(solve(test_list))
判断元素是否在列表中
def is_in_list(init_list, el): if init_list[0] == el: return True else: return False # list=[12, 6, 5956, 7, 8, 98, 46, 46, 4, 451, 9684, 4] # 寻找列表init_list中是否存在元素el def solve(init_list,el): # 求出init_list的长度 list_length = len(init_list) # 递归出口条件,当规模缩小到只有一个元素时, if list_length == 1: return is_in_list(init_list,el) # 通过切片截取下标为0~list_length//2(不包含list_length//2)的数据元素 left_list = init_list[:list_length//2] # 通过切片截取下标为list_length//2~list_length(不包含list_length)的数据元素 right_list = init_list[list_length//2:] # 在 init_list 的左边序列 和 右边序列分别寻找是否存在el res = solve(left_list,el) or solve(right_list,el) return res test_list = [12, 6, 5956, 7, 8, 98, 46, 46, 4, 451, 9684, 4] print(solve(test_list,45)) print(solve(test_list,4))
爬楼梯
# 爬楼梯 def climb(n): if n <= 2: return n # 第n层楼梯的方式总数 = 第n-1层楼梯的方式总数+第n-2层楼梯的方式总数 return climb(n-1) + climb(n-2) for i in range(1,6): print('爬到第%d层楼梯有%d种方式' %(i,climb(i)))