概述
指令微调(Instruction Tuning)是指使用自然语言形式的数据对预训练后的大语言模型进行参数微调,22年谷歌ICLR论文中提出这个概念。在其它文献中,指令微调也被称为有监督微调(Supervised
Fine-tuning)或多任务提示训练(Multitask Prompted Training)。指令微调过程需要首先收集或构建指令化的实例,然后通过有监督的方式对大语言模型的参数进行微调。经过指令微调后,大语言模型能够展现出较强的指令遵循能力,可以通过零样本学习的方式解决多种下游任务。经过 NLP 指令数据微调后,大语言模型可以学习到指令遵循(Instruction Following)的能力,进而能够解决其他未见过的 NLP 任务。
指令数据构建
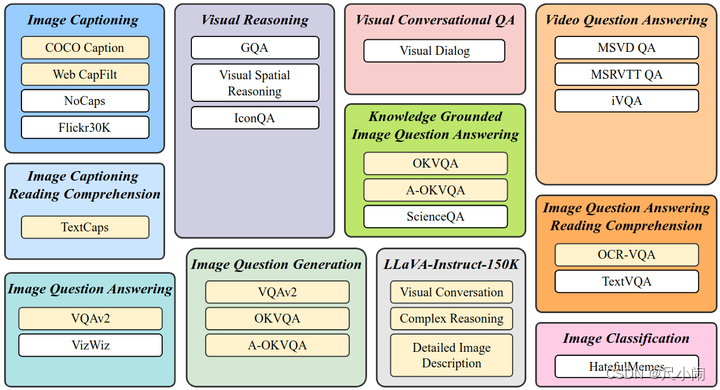
- 基于现有NLP任务数据集构建
- 基于日常对话数据构建
- 基于合成数据构建
以下是几种合成数据构建的方法。
Self-Instruct
代表性工作Self-Instruct:借助大语言模型(例如 ChatGPT)所具备的数据合成能力,通过迭代的方法高效地生成大量的指令微调数据。作为初始任务池,该方法首先构建了 175 条高质量且多样的指令数据,之后经由两个主要步骤生成指令微调数据。
(1)指令数据生成:从任务池中随机选取少量指令数据作为示例,并针对 ChatGPT 设计精细指令来提示模型生成新的微调数据。
你被要求提供 10 个多样化的任务指令。这些任务指令将被提供给 GPT 模型。
以下是你提供指令需要满足的要求:
1. 尽量不要在每个指令中重复动词,要最大化指令的多样性。
2. 使用指令的语气也应该多样化。例如,将问题与祈使句结合起来。
……(省略后续要求)
下面是 10 个任务指令的列表:
### 指令:将 85 华氏度转换为摄氏度。
### 输出:85 华氏度等于 29.44 摄氏度。
### 指令:是否有科学无法解释的事情?
### 输出:有很多科学无法解释的事情,比如生命的起源、意识的存在……
……(省略上下文示例)
(2)过滤与后处理:剔除低质量或者重复的生成实例,从而保证指令数据的多样性与有效性。常见的过滤方法包括:去除与任务池中指令相似度过高的指令、语言模型难以生成回复的指令、过长或过短的指令以及输入或输出存在重复的实例。
Evol-Instruct
Self-Instruct 生成的实例可能过于简单或缺乏多样性,提出一种改进的指令数据合成方法 Evol-Instruct。该方法通过基于深度和广度的演化来提高实例的复杂性和多样性。
(1)指令演化:分为深度演化和广度演化。深度演化通过五种特定类型的提示(添加约束、深化、具体化、增加推理步骤以及使输入复杂化)使得指令变得更加复杂与困难;而广度演化旨在扩充指令主题范围、指令涉及的能力范围以及整体数据集的多样性。
深度演化(添加约束)指令:
我希望您充当指令重写器。
您的目标是将给定的提示重写为更复杂的版本,使得著名的 AI 系统(例如 ChatGPT 和 GPT-4)更难处理。
但重写的提示必须是合理的,且必须是人类能够理解和响应的。
您的重写不能省略 # 给定提示 # 中表格和代码等非文本部分。
您应该使用以下方法使给定的提示复杂化:
请在 # 给定提示 # 中添加一项约束或要求。
你应该尽量不要让 # 重写提示 # 变得冗长,# 重写提示 # 只能在 # 给定提示 # 中
添加 10 到 20 个单词。
# 重写提示 # 中不允许出现“# 给定提示 #”、“# 重写提示 #”字段。
# 给定提示 #: {需要重写的指令}
# 重写提示 #
广度演化指令:
我希望你充当指令创造器。
您的目标是从 # 给定提示 # 中汲取灵感来创建全新的提示。
此新提示应与 # 给定提示 # 属于同一领域,但更为少见。
# 创造提示 # 的长度和复杂性应与 # 给定提示 # 类似。
# 创造提示 # 必须合理,并且必须能够被人类理解和响应。
# 创造提示 # 中不允许出现“# 给定提示 #”、“# 创造提示 #”字段。
# 给定提示 #: {需要重写的指令}
# 创造提示 #:
(2)数据后处理:主要使用了如下的规则进行处理:使用 ChatGPT 比较演化前后的指令,移除 ChatGPT 认为差异很小的指令;移除大模型难以响应的指令,如响应中包含“sorry”或响应长度过短;移除仅包含标点符号和连词的指令或回复。
其它方法:
Self-Align设计了多种基于人类对齐原则的合成数据过滤技术,该方法通过上下文提示让 ChatGPT 能够筛选出高质量的实例数据来训练新的模型,并进一步让新训练的模型产生更多与人类对齐的指令微调数据。
指令回译技术:直接使用现有的文本(例如维基网页数据)作为输出,然后利用上下文学习来逆向合成相应的输入指令。由于输出内容都是人工撰写的,该方法能够让模型学习生成准确且流畅的文本。
指令数据构建的提升方法
- 指令格式设计
训练过程中同时使用了带示例的指令数据(即少样本)和不带示例的指令数据(即零样本)、在指令微调数据集中引入思维链数据、在指令微调时同时引入了包含 CoT 和不包含 CoT 的实例,使用混合指令数据
指令数据并不是包含信息越多越好,添加某些看似有用的信息(例如需要避免的事项、原因或建议)到指令中,可能不会带来明显的效果提升,甚至可能产生不利影响 - 扩展指令数量
对于NLP任务,FLAN-T5通过逐步将指令数量扩展至 0.18M、5.55M、7.2M 以及17.26M,模型性能呈持续上升的趋势。然而,当指令数量达到 7.2M后,模型性能的提升变得非常缓慢。FLAN-T5 中采用的指令可能仅对传统 NLP 任务适用,而对于日常对话这一至关重要的能力并未带来明显的提升。
对于一个较好的预训练基座模型,越来越多的研究工作表明一定数
量的高质量指令就可以激活大语言模型的对话能力。Alpaca [42] 使用了 52K 条合成数据来指令微调 LLaMA (7B),在 179 条日常对话数据的评测中到达了接近text-davinci-003 的效果。进一步,LIMA [203] 仅使用了一千条人工标注的高质量指令数据来微调 LLaMA (65B),就在 300 条日常对话测试中取得了较好的模型表现。
但是,仅依靠少量指令数据难以兼顾 NLP 任务和对话场景任务。 - 指令重写与筛选
YuLan-Chat-3提出了“主题多样性”增强方法,预先从知乎收集了 293 种常见主题标签(例如,“教育”,“体育”),然后随机选择一种并使用 ChatGPT 对指令进行重写来适配到相应的主题(例如使用提示:“请帮我把以下指令重写为教育主题”),最后进行质量筛选来获取高质量的多样性指令数据。它提出了“平衡指令难度”策略,其用大模型的困
惑度分数来估算指令数据的难度水平,删除过于简单或过于困难的指令数据,从而缓解大模型训练不稳定或者过拟合的现象。
指令微调的训练策略
在训练方式上,指令微调与预训练较为相似,很多设置包括数据组织形式都可以预训练阶段所采用的技术。指令微调中的优化器设置(AdamW 或 Adafactor)、稳定训练技巧(权重衰减
和梯度裁剪)和训练技术(3D 并行、ZeRO 和混合精度训练)都与预训练保持阶段一致,可以完全沿用。以下是指令微调与预训练的不同之处。
优化设置
- 目标函数。预训练阶段通常采用语言建模损失(详见第 6.1.1 节),优化模型在每一个词元上的损失。而指令微调可以被视为一个有监督的训练过程,通常采用的目标函数为序列到序列损失,仅在输出部分计算损失,而不计算输入部分的损失。
- 批次大小和学习率。指令微调阶段通常只需要使用较小的批次大小和学习率对模型进行小幅度的调整。
- 多轮对话数据的高效训练。对于一个多轮对话数据,通常的训练算法是将其拆分成多个不同的对话数据进行单独训练。为了提升训练效率,可以采用特殊的掩码机制来实现多轮对话数据的高效训练。在因果解码器架构中,由于输入输出没有明显的分界,可以将所有一个对话的多轮内容一次性输入模型,通过设计损失掩码来实现仅针对每轮对话的模型输出部分进行损失计算,从而显著减少重复前缀计算的开销。多轮对话涉及多次用户输入和模型的输出,但是训练中仅需要在模型的输出上计算损失。
数据组织策略
- 平衡数据分布
混合使用现有的多个指令数据集,以此来实现模型能力的综合改进。最常用方法:样本比例混合策略,即把所有数据集进行合并,然后从混合数据集中等概率采样每个实例。研究者建议混合使用 NLP 任务数据(如 FLAN v2)、对话数据(如ShareGPT)和合成数据(如 GPT4-Alpaca),来进行大模型的指令微调。 - 多阶段指令数据微调
YuLan-Chat-3 采用了“多阶段指令微调”策略:首先使用大规模 NLP 任务指令数据对模型进行微调,然后再使用相对多样的日常对话指令和合成指令进一步微调。为了避免能力遗忘问题,可以在第二阶段中添加一些 NLP 指令数据。这种多阶段的微调策略也可以应用于其他训练设置。例如,对于不同的微调阶段,训练中可以逐渐增加指令的难度和复杂性,从而逐渐提高大模型遵循复杂指令的能力。 - 结合预训练数据与指令微调数据
为了使得微调过程更加有效和稳定,可以在指令微调期间引入了预训练数据和任务,这可以看作是对于指令微调的正则化。OPT-IML在指令微调阶段引入了 5% 的预训练数据,在分类和生成任务上都能取得增益;然而,进一步增加预训练数据会对生成任务有利,但有可能损失分类任务的表现。
另一方面,将指令数据引入到预训练阶段也成为了一种常见的训练技术。通过提前使用指令微调数据,有可能会帮助模型在预训练阶段更好地感知下游任务,从而更为针对性地从预训练数据中学习知识与能力。如,GLM-130B的预训练过程由 95% 的传统自监督预训练和 5% 的指令微调任务混合组成。MiniCPM提出在预训练阶段和指令微调阶段之间添加一个“退火阶段”,该阶段混合使用高质量的预训练数据和指令微调数据,其实验结果表明该策略优于先预训练再指令微调的两阶段策略。
参数高效的模型微调
参数高效微调(Parameter-efficient Fine-tuning),也称为轻量化微调(Lightweight Fine-tuning)。
LoRA
低秩适配(Low-Rank Adaptation, LoRA)
模型在针对特定任务进行适配时,参数矩阵往往是过参数化(Over-parametrized)的,其存在一个较低的内在秩。
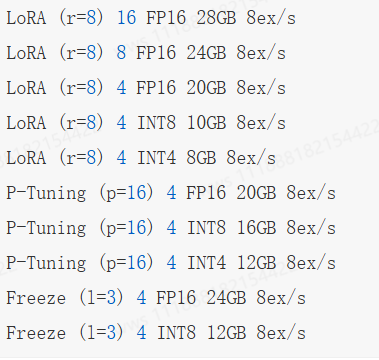
假设 LoRA 需要训练的参数量为 P L o R A P_{LoRA} PLoRA,模型原始参数为P。 P L o R A P_{LoRA} PLoRA ≪ P,LoRA 微调需要的显存大小从全量微调的16P大幅减少为 2 P + 16 P L o R A 2P+16P_{LoRA} 2P+16PLoRA。
LoRA变种
在原始的 LoRA 实现中,每个低秩矩阵的低秩参数 𝑅 都被设置为固定且相同的数值,并且在训练过程中无法进行调整,这种设定忽略了不同的秩在微调任务中可能产生的差异化影响。因此,通过这种方式训练得到的低秩矩阵往往并非最优解。
- AdaLoRA。它讨论了如何更好地进行秩的设置。它引入了一种动态低秩适应技术,在训练过程中动态调整每个参数矩阵需要训练的秩同时控制训练的参数总量。具体来说,模型在微调过程中通过损失来衡量每个参数矩阵对训练结果的重要性,重要性较高的参数矩阵被赋予比较高的秩,进而能够更好地学习到有助于任务的信息。相对而言,不太重要的参数矩阵被赋予比较低的秩,来防止过拟合并节省计算资源。尽管 LoRA 能够有效地节省显存,但对于参数规模达到上百亿级别的模型而言,其微调所需的成本仍然相当高昂。
- QLoRA。它将原始的参数矩阵量化为 4 比特,而低秩参数部分仍使用 16 比特进行训练,在保持微调效果的同时进一步节省了显存开销。根据上一小节的分析,对于给定参数量为 𝑃 的模型,QLoRA 微调所需要的显存由 LoRA 微调所需要的2𝑃 进一步下降为 0.5𝑃。
其它高效微调方法
适配器微调、前缀微调、提示微调。这三种方法在预训练语言模型中被广泛使用,但是在大语言模型中的应用相对较少。
适配器微调
适配器微调(Adapter Tuning)在 Transformer 模型中引入了小型神经网络模块(称为适配器)。为了实现适配器模块,研究者提出使用瓶颈网络架构:它首先将原始的特征向量压缩到较低维度,然后使用激活函数进行非线性变换,最后再将其恢复到原始维度。通常来说,适配器模块将会被集成到Transformer 架构的每一层中,使用串行的方式分别插入在多头注意力层和前馈网络层之后、层归一化之前。在微调过程中,适配器模块将根据特定的任务目标进行优化,而原始的语言模型参数在这个过程中保持不变。通过这种方式,可以在微调过程中有效减少需要训练参数的数量。

前缀微调
前缀微调(Prefix Tuning)在语言模型的每个多头注意力层中都添加了一组前缀参数。这些前缀参数组成了一个可训练的连续矩阵,可以视为若干虚拟词元的嵌入向量,它们会根据特定任务进行学习。在前缀微调过程中,整个模型中只有前缀参数会被训练,因此可以实现参数高效的模型优化。

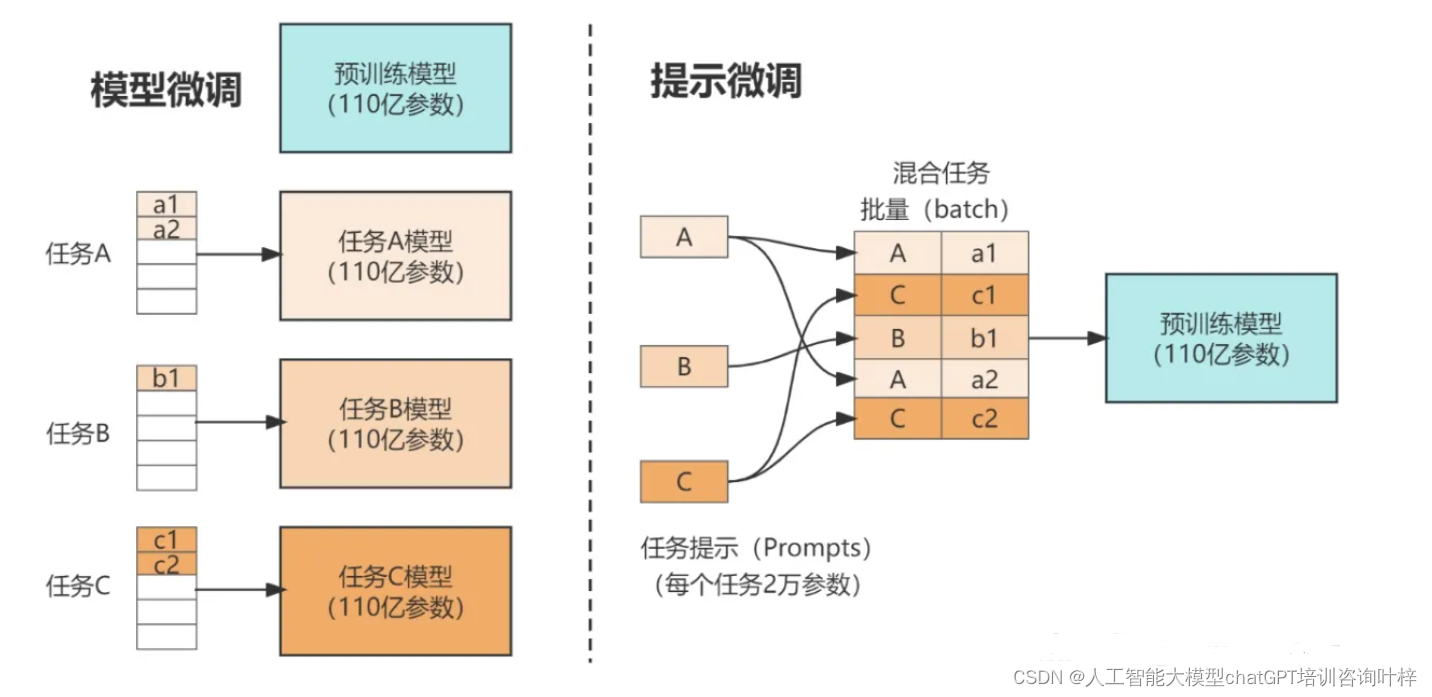
提示微调
提示微调仅在输入嵌入层中加入可训练的提示向量。在离散提示方法的基础上(可查阅系列文章提示学习),提示微调首先在输入文本端插入一组连续嵌入数值的提示词元,这些提示词元可以以自由形式或前缀形式来增强输入文本,用于解决特定的下游任务。在具体实现中,只需要将可学习的特定任务提示向量与输入文本向量结合起来一起输入到语言模型中。

P-tuning提出了使用自由形式来组合输入文本和提示向量,通过双向 LSTM来学习软提示词元的表示,它可以同时适用于自然语言理解和生成任务。
Prompt Tuning以前缀形式添加提示,直接在输入前拼接连续型向量。
在提示微调的训练过程中,只有提示的嵌入向量会根据特定任务进行监督学习,然而由于只在输入层中包含了极少量的可训练参数,有研究工作表明该方法的性能高度依赖底层语言模型的能力。