- scaling law
- 大模型评测
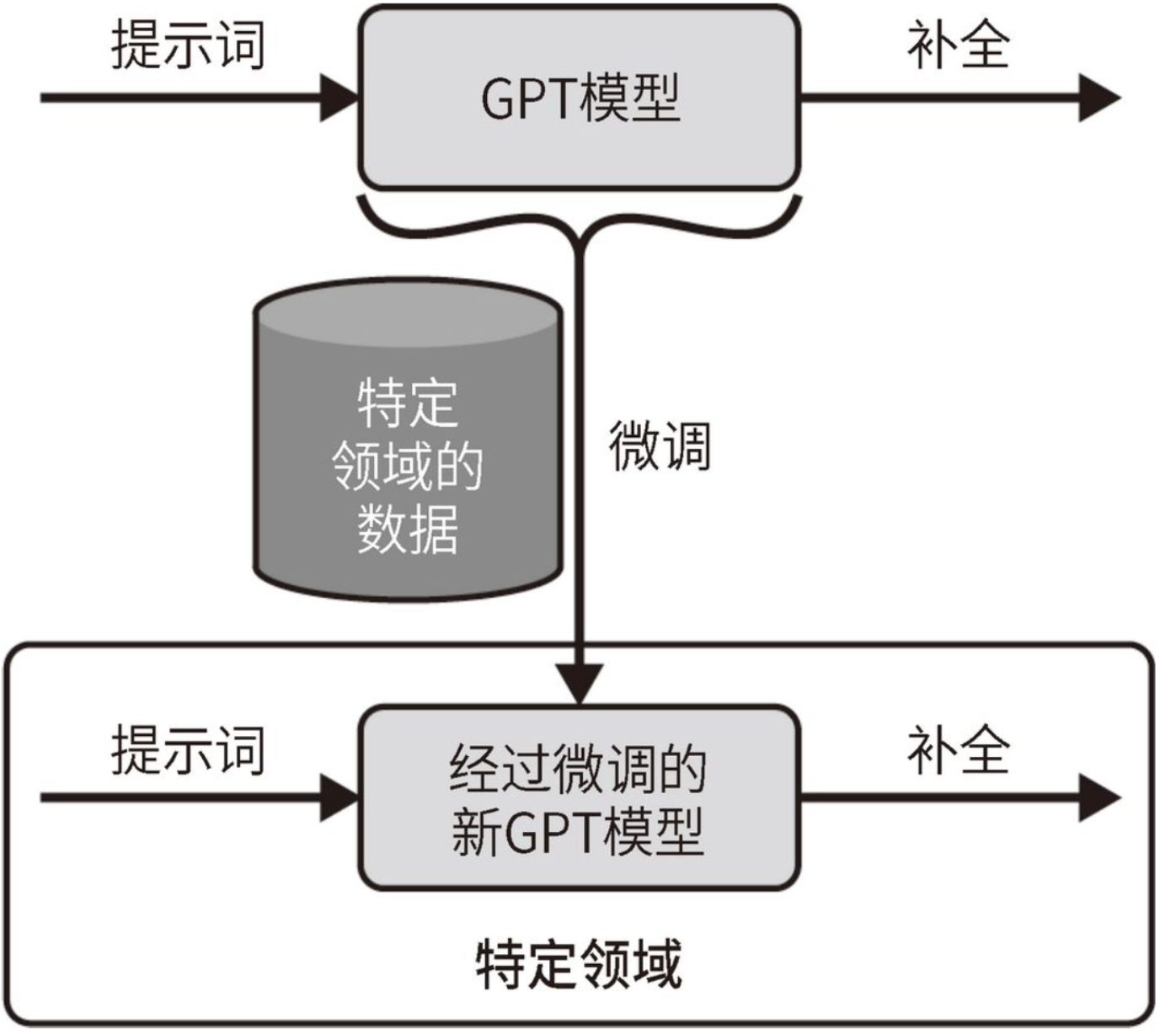
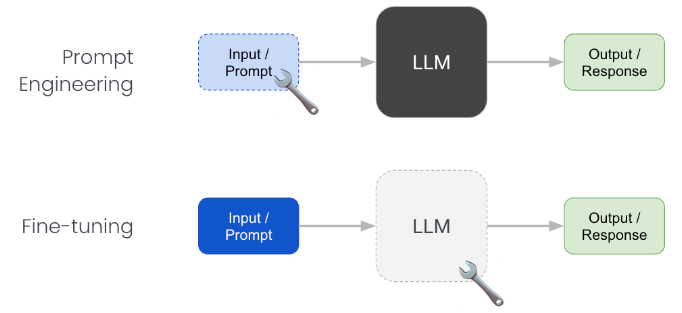
- 指令微调
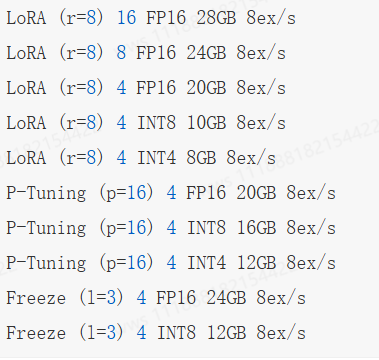
微调7B模型需要3×28G的显存(SGD+Momentum),至少需要2张A100的显卡才能满足
数据
格式
wget https://raw.githubusercontent.com/baichuan-inc/Baichuan2/main/fine-tune/data/belle_chat_ramdon_10k.json
wget https://huggingface.co/datasets/BelleGroup/school_math_0.25M/resolve/main/school_math_0.25M.json
import json
data_path = "/root/autodl-tmp/belle_chat_ramdon_10k.json"
x = json.load(open(data_path))
print(x[0])
print(x[1])
{‘id’: ‘77771’, ‘conversations’: [{‘from’: ‘human’, ‘value’: ‘写一篇关于气候变化对海洋生态的影响的文章。\n’}, {‘from’: ‘gpt’, ‘value’: ‘好的,以下是你要求的文章:\n气候变化对海洋生态的影响\n气候变化对海洋生态产生了广泛的影响。全球变暖导致海洋温度上升,这可能会对许多水生生物的生存、繁殖和迁移造成巨大的影响。另外,海洋酸化也是一个问题,因为大气中二氧化碳的增加导致海水中的pH值下降,使得许多生物的外骨骼变得脆弱,从而影响它们的生存和繁殖。\n此外,气候变化还会引起海平面上升,这不仅对海岸线和沿海居民产生影响,还会对许多海洋生物的栖息地造成影响。一些岛屿上的陆地生物面临几乎完全消失的风险,而另一些生物范围则会扩大到更广泛的领域,这可能会导致新的竞争和生态平衡的改变。\n总之,气候变化并不只是一个地球气温的问题,它对海洋生态系统产生了广泛和深远的影响。\n’}, {‘from’: ‘human’, ‘value’: ‘从刚刚的文章中提取出气候变化对海洋生物繁殖的影响。\n’}, {‘from’: ‘gpt’, ‘value’: ‘文章已经提到过气候变化会对海洋生物的生存、繁殖和迁移造成影响。例如,海洋酸化会使得许多生物的外骨骼变得脆弱,进而影响它们的生存和繁殖。此外,海洋温度上升也可能会对很多生物的生存和繁殖产生负面影响。’}]}
{‘id’: ‘27684’, ‘conversations’: [{‘from’: ‘human’, ‘value’: ‘你好,请问你能帮我查一下明天的天气吗?\n’}, {‘from’: ‘gpt’, ‘value’: ‘当然,你在哪个城市呢?\n’}, {‘from’: ‘human’, ‘value’: ‘我在上海。\n’}, {‘from’: ‘gpt’, ‘value’: ‘好的,根据天气预报,明天上海多云转阴,气温在20到25摄氏度之间。需要我帮你查询其他信息吗?’}]}
也就是每一条id, 和 conversations. 然后conversations中分别是多个from value的组合
f_write = open("/root/autodl-tmp/school_math_0.25M_conv.json", "w")
data_path = "/root/autodl-tmp/school_math_0.25M.json"
with open(data_path) as f:
lines = f.readlines()
num_id = 1
for line in lines:
data = json.loads(line)
print(data)
# conversations = [{"from": "human", "value": data['instruction']+data['input']},{"from": "assistant", "value": data['output']}]
# # conversations = [{"from": "human", "value": data['input']},{"from": "assistant", "value": data['target']}]
# uniq_id = data['id'] if "id" in data else args.dataset_name+"-"+str(num_id)
# item = {"id":uniq_id, "conversations": conversations}
# f_write.write(json.dumps(item, ensure_ascii=False)+"\n")
num_id += 1
if num_id > 3:
break
f_write.close()
{‘instruction’: ‘题目:小明每天早上花费10分钟时间走到学校,如果小明家距离学校2公里,那么他每分钟走多少米?’, ‘input’: ‘’, ‘output’: ‘这是一个关于速度、路程、时间的数学问题。我们可以通过公式:速度=路程÷时间 来解决。\n因为小明每天早上走2公里,所以他的路程为2千米。而他每天早上要花费10分钟时间走到学校,因此他的时间为10分钟,即600秒。\n所以小明每分钟走的距离为 2公里 / 600秒 = 0.0033公里/秒 或 3.3米/秒。\n答案:小明每分钟走3.3米。’}
{‘instruction’: ‘题目:今天小明骑自行车从家到学校用了20分钟,回家用了25分钟。如果小明在上学和回家的路上的速度一样,那么他从家到学校的距离是学校到家的距离的百分之几?’, ‘input’: ‘’, ‘output’: ‘\n假设小明家到学校的距离为x千米,根据速度等于路程除以时间的公式,可以得出小明的速度为:家到学校的速度 = x / 20,学校到家的速度 = x / 25。因为小明在上学和回家的路上的速度一样,所以有:x / 20 = x / 25,解出 x = 5/4 千米。\n因此,家到学校的距离是学校到家的距离的百分之几,可以通过求比值得到:x / (5/4)x = 4/5 = 0.8,即小明从家到学校的距离是学校到家的距离的百分之80。’}
{‘instruction’: ‘题目:\n鹿妈妈买了24个苹果,她想平均分给她的3只小鹿吃,每只小鹿可以分到几个苹果?’, ‘input’: ‘’, ‘output’: ‘\n鹿妈妈买了24个苹果,平均分给3只小鹿吃,那么每只小鹿可以分到的苹果数就是总苹果数除以小鹿的只数。\n24÷3=8\n每只小鹿可以分到8个苹果。所以,答案是每只小鹿可以分到8个苹果。’}
每一条包括instruction, input, output三个item
其中注释的代码,可以将格式转化为与上面相同
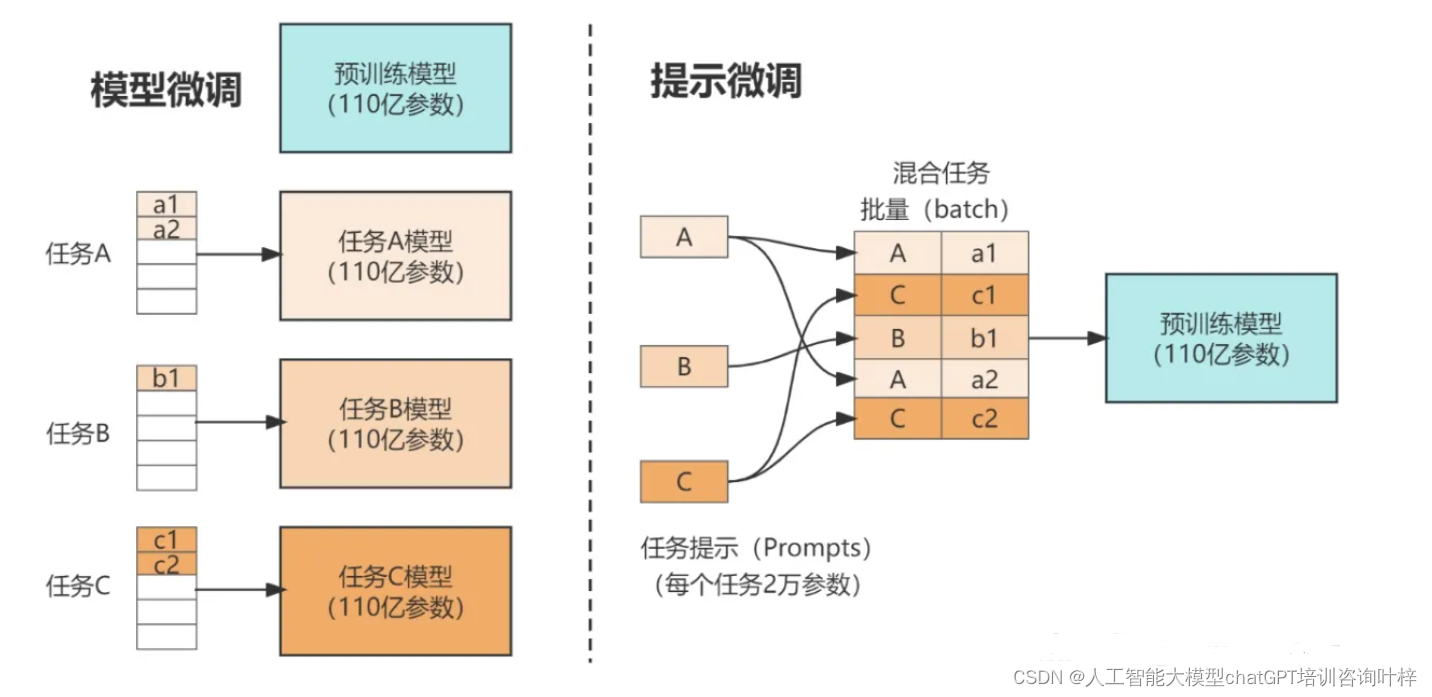
LoRA
低秩适配器
- 图像中可以理解为某种图像风格的适配器
- 本质上是因为大模型的过参数化,认为有某个更小的维度(内部维度,intrinsic dimension)可以足够表征任务,类似找到真正的抽象核心去调整. 对于预训练权重矩阵,我们可以用一个低秩分解来表示参数更新
- 训练参数仅为整体参数的万分之一、GPU显存使用量减少2/3且不会引入额外的推理耗时
实现
- 原模型旁边增加一个旁路,通过低秩分解(先降维再升维)来模拟参数的更新量
- 训练时,原模型固定,只训练降维矩阵A和升维矩阵B. 由于不需要对模型的权重参数重新计算梯度,大大减少了需要训练的计算量。
- 推理时,可将BA加到原参数上,不引入额外的推理延迟
- 初始化,A采用高斯分布初始化,B初始化为全0,保证训练开始时旁路为0矩阵
- 可插拔式的切换任务,当前任务W0+B1A1,将lora部分减掉,换成B2A2,即可实现任务切换;
- 秩的选取:对于一般的任务,rank=1,2,4,8足矣,而对于一些领域差距比较大的任务可能需要更大的rank。
代码
- 将可微调参数分配到多种类型权重矩阵中,而不应该用更大的秩单独微调某种类型的权重矩阵。
class LoRALayer():
def __init__(
self,
r: int,
lora_alpha: int,
lora_dropout: float,
merge_weights: bool,
):
self.r = r
self.lora_alpha = lora_alpha
# Optional dropout
if lora_dropout > 0.:
self.lora_dropout = nn.Dropout(p=lora_dropout)
else:
self.lora_dropout = lambda x: x
# Mark the weight as unmerged
self.merged = False
self.merge_weights = merge_weights
class Embedding(nn.Embedding, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
num_embeddings: int,
embedding_dim: int,
r: int = 0,
lora_alpha: int = 1,
merge_weights: bool = True,
**kwargs
):
nn.Embedding.__init__(self, num_embeddings, embedding_dim, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=0,
merge_weights=merge_weights)
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, num_embeddings)))
self.lora_B = nn.Parameter(self.weight.new_zeros((embedding_dim, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
def reset_parameters(self):
nn.Embedding.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.zeros_(self.lora_A)
nn.init.normal_(self.lora_B)
def train(self, mode: bool = True):
nn.Embedding.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= (self.lora_B @ self.lora_A).transpose(0, 1) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += (self.lora_B @ self.lora_A).transpose(0, 1) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
if self.r > 0 and not self.merged:
result = nn.Embedding.forward(self, x)
after_A = F.embedding(
x, self.lora_A.transpose(0, 1), self.padding_idx, self.max_norm,
self.norm_type, self.scale_grad_by_freq, self.sparse
)
result += (after_A @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return nn.Embedding.forward(self, x)
class Linear(nn.Linear, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.,
fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
merge_weights: bool = True,
**kwargs
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
merge_weights=merge_weights)
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features)))
self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.transpose(0, 1)
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize B the same way as the default for nn.Linear and A to zero
# this is different than what is described in the paper but should not affect performance
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode: bool = True):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
nn.Linear.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
if self.r > 0 and not self.merged:
result = F.linear(x, T(self.weight), bias=self.bias)
result += (self.lora_dropout(x) @ self.lora_A.transpose(0, 1) @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return F.linear(x, T(self.weight), bias=self.bias)
class MergedLinear(nn.Linear, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.,
enable_lora: List[bool] = [False],
fan_in_fan_out: bool = False,
merge_weights: bool = True,
**kwargs
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
merge_weights=merge_weights)
assert out_features % len(enable_lora) == 0, \
'The length of enable_lora must divide out_features'
self.enable_lora = enable_lora
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0 and any(enable_lora):
self.lora_A = nn.Parameter(
self.weight.new_zeros((r * sum(enable_lora), in_features)))
self.lora_B = nn.Parameter(
self.weight.new_zeros((out_features // len(enable_lora) * sum(enable_lora), r))
) # weights for Conv1D with groups=sum(enable_lora)
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
# Compute the indices
self.lora_ind = self.weight.new_zeros(
(out_features, ), dtype=torch.bool
).view(len(enable_lora), -1)
self.lora_ind[enable_lora, :] = True
self.lora_ind = self.lora_ind.view(-1)
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.transpose(0, 1)
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def zero_pad(self, x):
result = x.new_zeros((len(self.lora_ind), *x.shape[1:]))
result[self.lora_ind] = x
return result
def merge_AB(self):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
delta_w = F.conv1d(
self.lora_A.unsqueeze(0),
self.lora_B.unsqueeze(-1),
groups=sum(self.enable_lora)
).squeeze(0)
return T(self.zero_pad(delta_w))
def train(self, mode: bool = True):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
nn.Linear.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0 and any(self.enable_lora):
self.weight.data -= self.merge_AB() * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0 and any(self.enable_lora):
self.weight.data += self.merge_AB() * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
if self.merged:
return F.linear(x, T(self.weight), bias=self.bias)
else:
result = F.linear(x, T(self.weight), bias=self.bias)
if self.r > 0:
result += self.lora_dropout(x) @ T(self.merge_AB().T) * self.scaling
return result