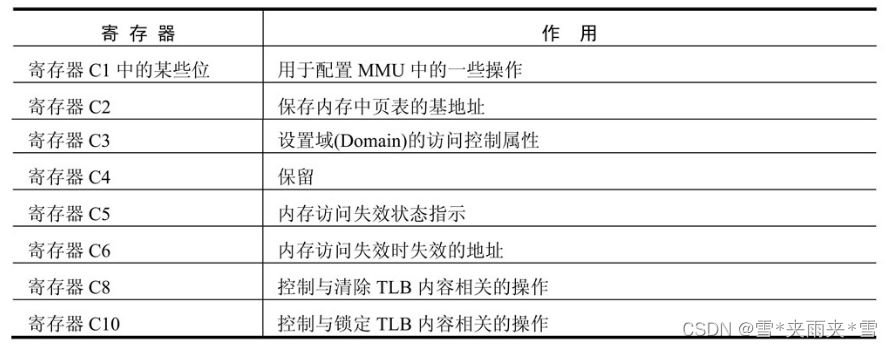
一、KMP算法
参考链接 阮一峰老师 https://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
启发阮一峰老师的jakeboxer的文章(在上一个链接中也有该链接)http://jakeboxer.com/blog/2009/12/13/the-knuth-morris-pratt-algorithm-in-my-own-words/
1.kmp作用是什么?
当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配。
2.关于kmp要了解的基础概念有哪些?
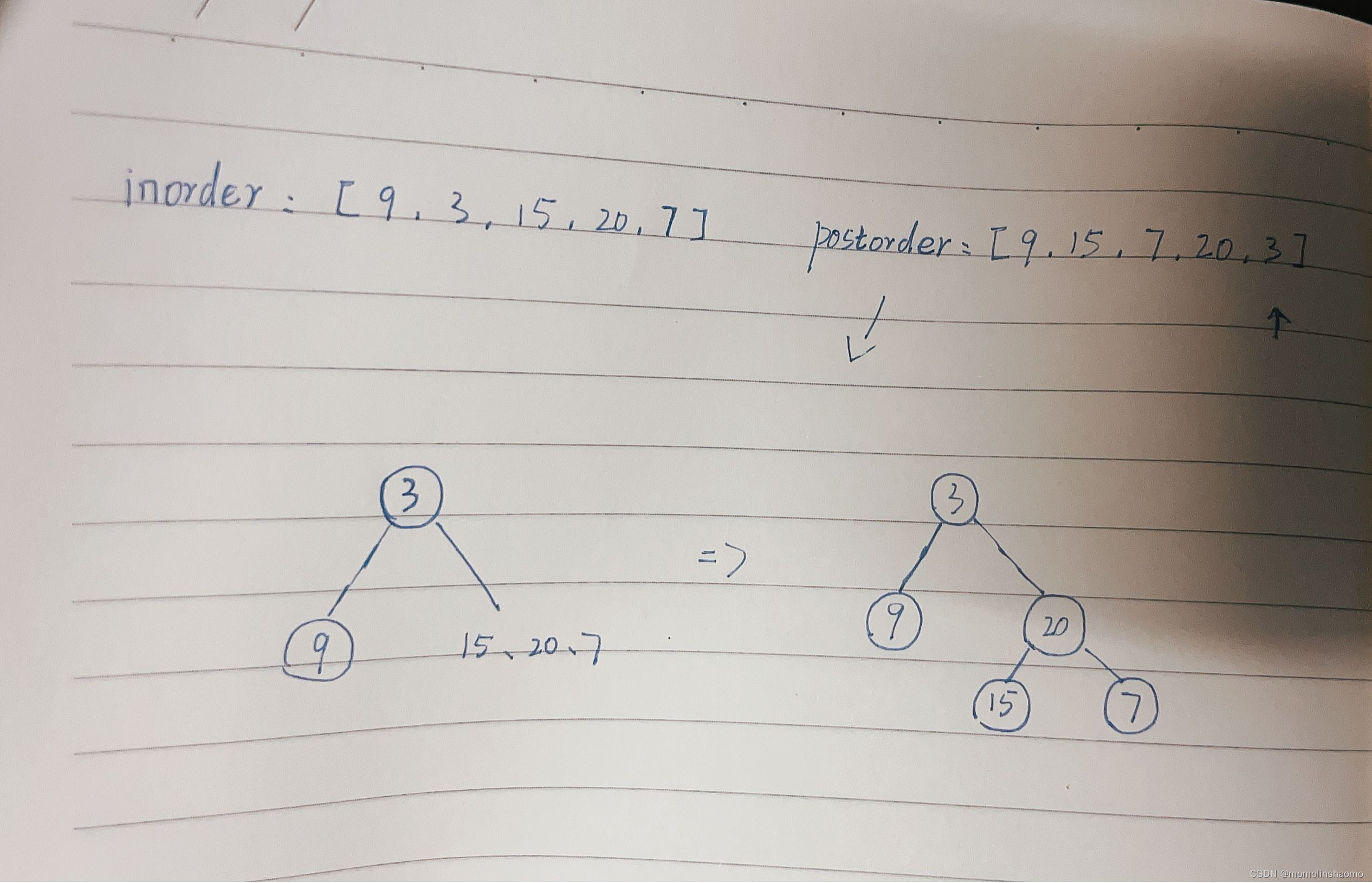
- 文本串 & 模式串:在文本串中寻找是否出现了模式串
- 例,aabaabaafa(文本串) 中寻找是否出现过 aabaaf(模式串)
- 前缀 & 后缀
- 前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串。
- 前缀,例,模式串abcd ->前缀:a,ab,abc
- 后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
- 后缀,模式串 abcd -> d,cd,bcd
- 注意,前缀和后缀通常是针对模式串讨论的
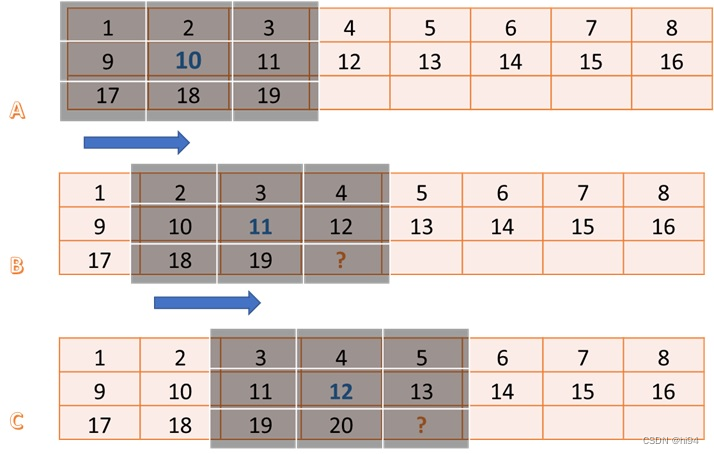
- 最长公共前后缀(长度):Carl哥理解的 最长相等前后缀 更容易帮助理解该概念
- 例,模式串aabaaf
- "子串"a,对应最长相等前后缀为0
- "子串"aa,对应~为1(前缀a,后缀a)
- "子串"aab,~为0(前缀a,aa;后缀b,ab)
- "子串"aaba,~为1(前缀a,aa,aab;后缀a,ba,aba)
- "子串"aabaa,~为2(前缀a,aa,aab,aaba;后缀a,aa,baa,abaa)
- "子串"aabaaf,~为0(前缀a,aa,aab,aaba,aabaa;后缀f,af,aaf,baaf,abaaf)
- 例,模式串aabaaf
- **前缀表,**在jakeboxer的文章中有一个鄙人认为更合适的词,The Partial Match Table(部分匹配表)
“子串” + 对应最长公共前后缀(value) = 前缀表,结合下图
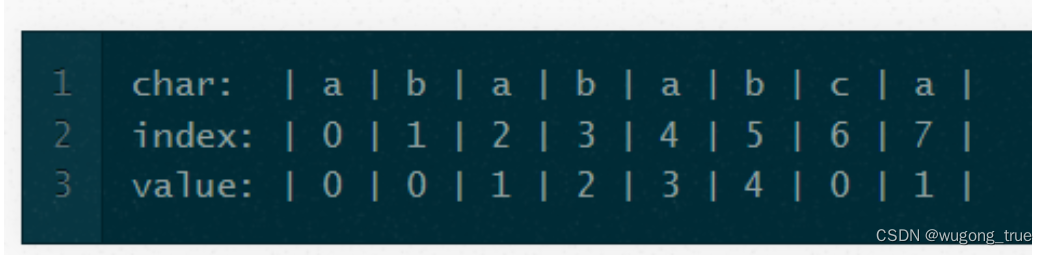
可以看出模式串与前缀表对应位置的数字表示的就是:下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
- next数组
- next数组既可以是前缀表,也可以是前缀表统一减一;
- 只涉及具体代码实现,并不涉及kmp的原理
3.如何获取前缀表/next数组(代码实现)?
注:
- 鄙人用i作为左指针,j作为右指针习惯了,将Carl哥的代码i,j变量更换了一下
- 最长公共前后缀用 ~ 表示
构造next数组有三部分
这个人写的关于next数组的构建写的挺不错的28. 找出字符串中第一个匹配项的下标 - 力扣(LeetCode)
以下是本人基于参考链接的截图以及个人添加的一些注释
- 通俗讲,
next[j]表示的就是一个字符串中,起始点为 0 ,长度为 j 的子串的最长公共前后缀的大小。(牢记牢记牢记) 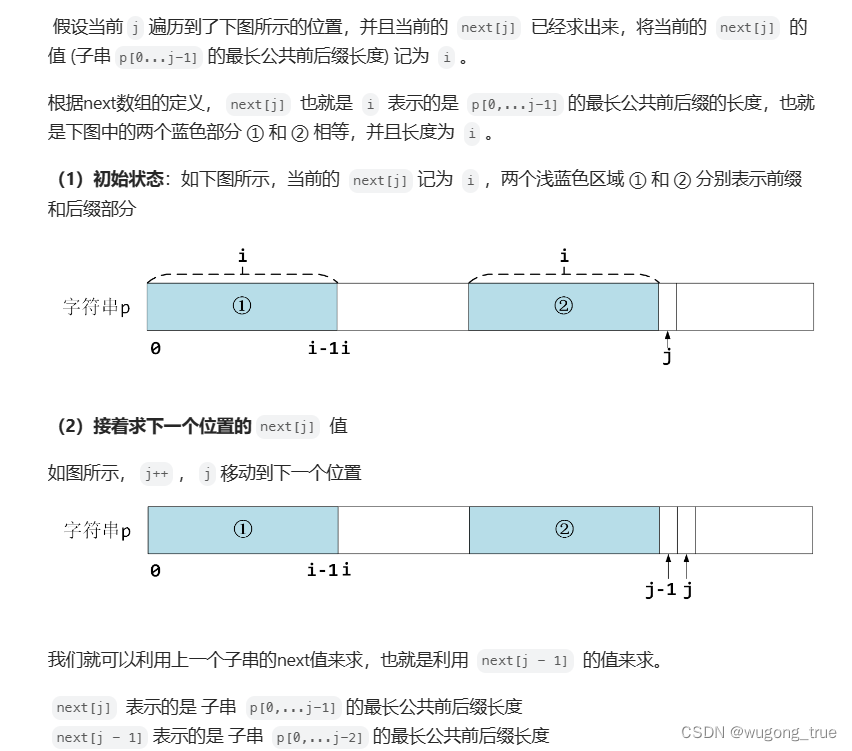
- 相等比较好理解,重点是不相等时 如何移动i来使 charAt(i) == charAt(j)呢?

- 看到 i’ 时其实比较懵,对应代码是 (前缀表不减一 :i = next[i - 1]) 或 (前缀表减一:i = next[i+1],判断条件是 while(i >= 0 && s.charAt(j) != s.charAt**(i+1**)) ,相当于 i = next[i - 1])
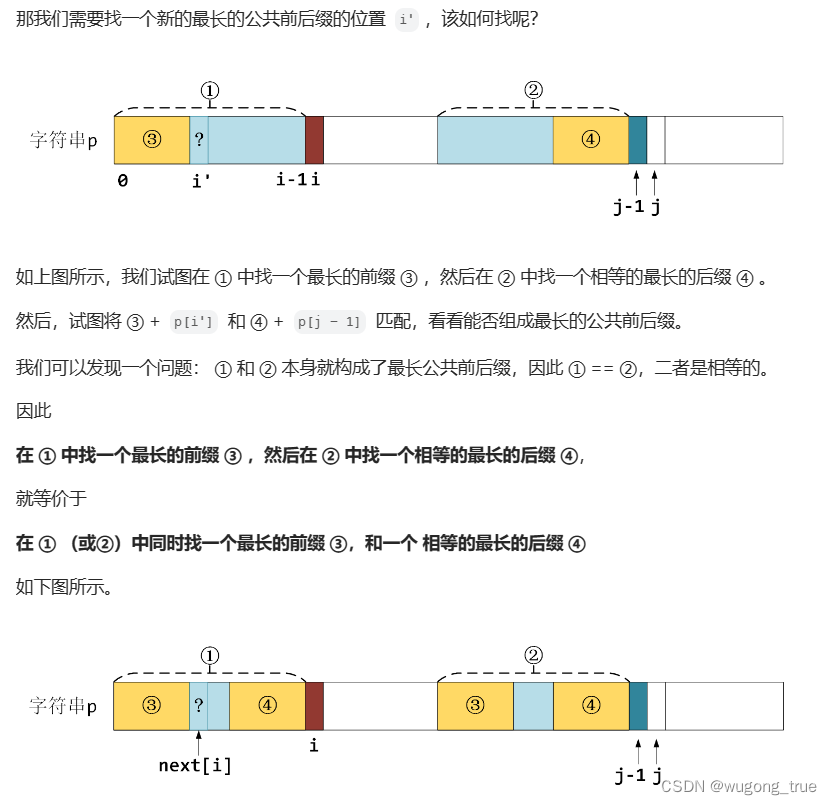

方法一
// 方法一,减一
class Solution {
public void getNext(int[] next, String s){
int i = -1;
next[0] = i;
for (int j = 1; j < s.length(); j++){
while(i >= 0 && s.charAt(j) != s.charAt(i+1)){
i=next[i];
}
if(s.charAt(j) == s.charAt(i+1)){
i++;
}
next[j] = i;
}
}
public int strStr(String haystack, String needle) {
if(needle.length()==0) return 0;
int[] next = new int[needle.length()];
getNext(next, needle);
int i = -1;
for(int j = 0; j < haystack.length(); j++){
while(i>=0 && haystack.charAt(i+1) != needle.charAt(j)){
i = next[i];
}
if(haystack.charAt(i+1) == needle.charAt(j)){
i++;
}
if(i == needle.length()-1){
return j - needle.length() + 1;
}
}
return -1;
}
}
方法二
class Solution {
//前缀表(不减一)Java实现
public int strStr(String haystack, String needle) {
if (needle.length() == 0) return 0;
int[] next = new int[needle.length()];
getNext(next, needle);
int i = 0;
for (int j = 0; j < haystack.length(); j++) {
while (i > 0 && needle.charAt(i) != haystack.charAt(j))
i = next[i - 1];
if (needle.charAt(i) == haystack.charAt(j))
i++;
if (i == needle.length())
return j - needle.length() + 1;
}
return -1;
}
//双指针,i是左指针,j是右指针
//j表示子串不断变长最后达到字符串末尾
private void getNext(int[] next, String s) {
int i = 0;
next[0] = 0;
for (int j = 1; j < s.length(); j++) {
while (i > 0 && s.charAt(i) != s.charAt(j))
i = next[i - 1]; //重置i到前一个位置的最长公共前缀位置
//1.i = 0 < 1、j = 1, 第一次遍历先执行下面的代码,如果i,j对应字符相同,左索引增加 i = 1, next[j] = 1; 表示~为1
if (s.charAt(i) == s.charAt(j))
i++;
next[j] = i;
}
//2.i = 1, j = 2, 若i,j字符不相等 -> i=next[i-1],即 将i重置为上一个字符的~的长度,while继续判断,直至相等进行if判断,或一直不等将i置为0;若i,j字符相等,则i++;无论相不相等,最后都会将i的值赋值给next[j]
}
}
小结
4.如何使用前缀表?
参考Carl哥的结论如图https://programmercarl.com/0028.%E5%AE%9E%E7%8E%B0strStr.html#%E6%80%9D%E8%B7%AF
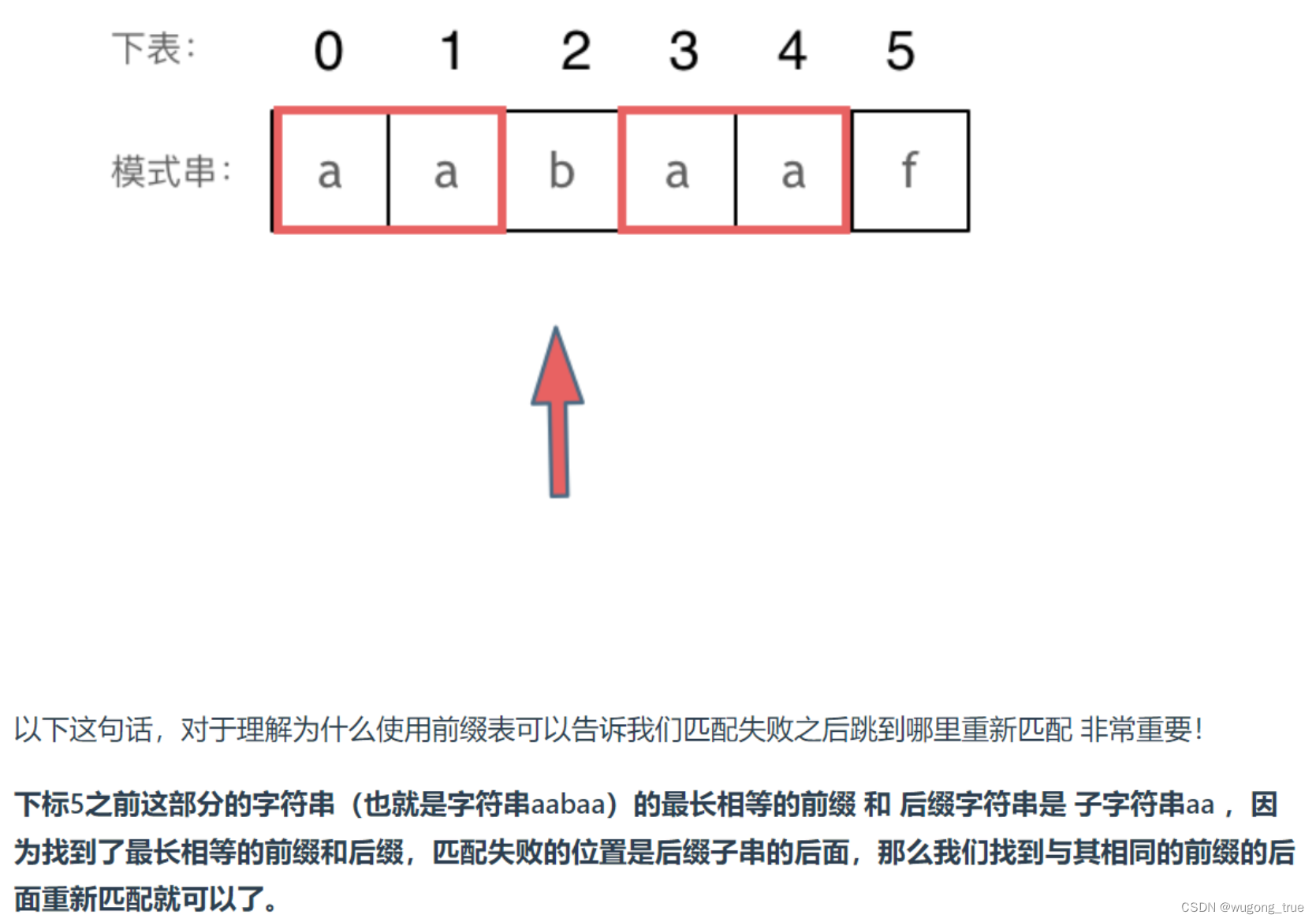
了解了原理,也就知道该如何操作
例,f 在文本串中匹配少一百,回退到索引为4的a,其最长公共前后缀长度为2,那么该模式串需要移动的长度为 (‘子串长度’ - next[i])(注意这里的) 5 - 2 = 3,移动3位
二、字符串总结
- 关于字符串的题核心逻辑尽量少使用库函数,多参照leetCode答案,在书写代码的过程中体会原理及相关时间复杂度和空间复杂度
- 字符串转成字符数组使用广泛
- StringBuffer&StringBuilder是值得了解和掌握的可变"String类"
三、双指针
- 双指针的种类
- 左右双指针:右旋转字符串,有序数组的平方…
- 快慢双指针:环形链表1,2;删除链表倒数第N个节点…
- 特殊左右指针:三数之和,四数之和…
24-04-11, 今天硬啃KMP消耗能量有点严重,之后再把next数组的构造过程写具体一点,然后把Boyer-Moore算法补充上去
四、比KMP更高效的算法 - Boyer–Moore算法
参考阮一峰老师的文章https://www.ruanyifeng.com/blog/2013/05/boyer-moore_string_search_algorithm.html
1.广泛应用,各种文本编译器的Ctrl + F 查找,大多使用Boyer-Moore算法
2.构思巧妙,容易理解
3.1需要理解的基础概念
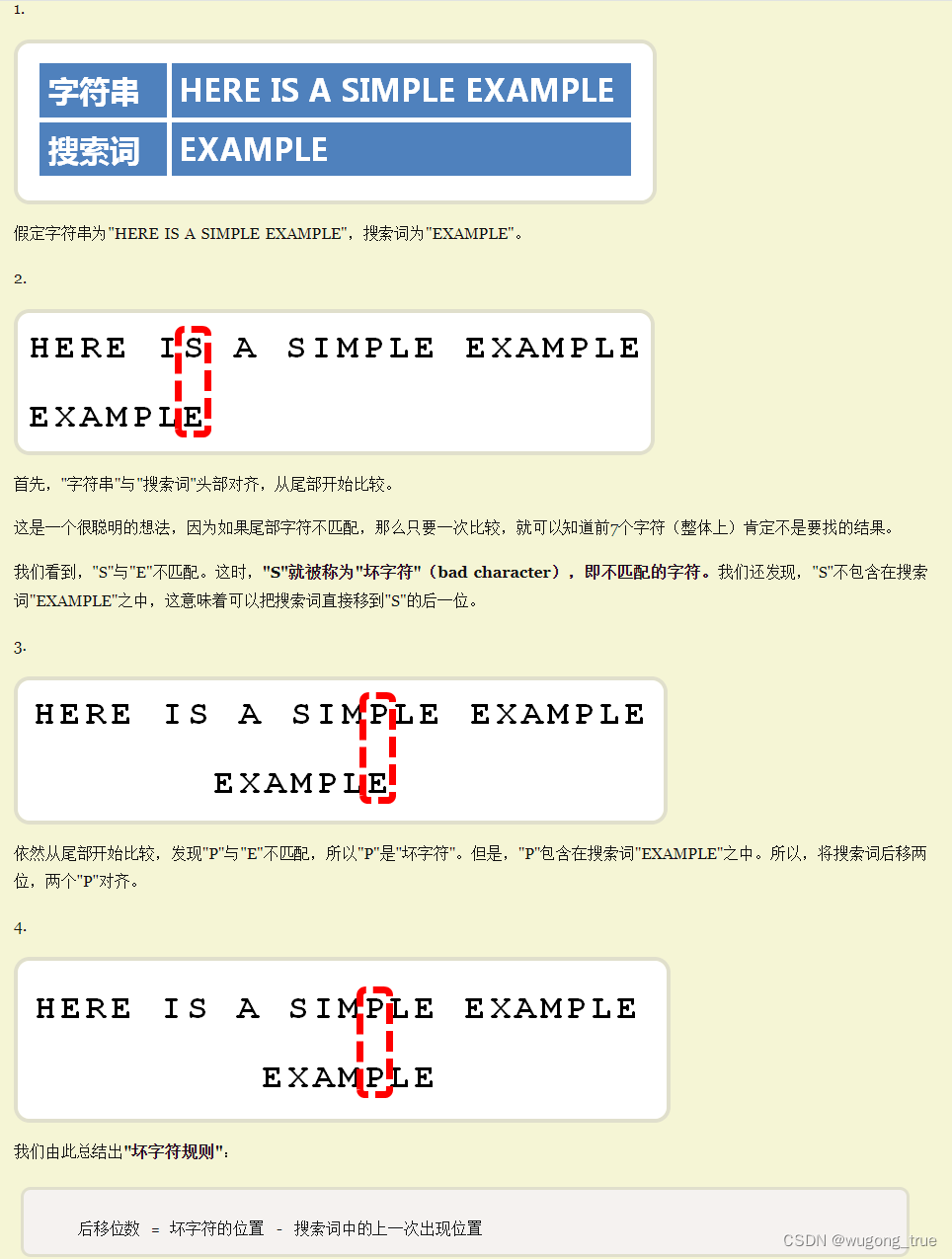



总结
坏字符(bad character),即不匹配的字符
匹配到坏字符时移动规则,后移位数 = 坏字符的位置 - 其在搜索词中的上一次出现位置
如果"坏字符"不包含在搜索词之中,则上一次出现位置为 -1。
用一个例子解释 “搜索词中的上一次出现位置” (杜撰模式串"EXAPMLEP",其中有两个P)
String hay = "HERE IS ASIMPLEP EXAMPLE"; // 01234567 //1.EXAPMLEP 第一次匹配 失败,且空格(坏字符)没有出现在模式串中,移动7-(-1) = 8位 // EXAPMLEP 第二次匹配,文本串P,模式串M匹配失败 //此时注意,文本串中未匹配的字符是P,但是EXAPMELP(模式串中有两个P,如以最后的P来计算,移动4 - 7 = -3,显然是不合理的) //正确做法如4,移动 4 - 3 = 1 移动1位 // EXAPMLEP String needle = "EXAPMLEP";
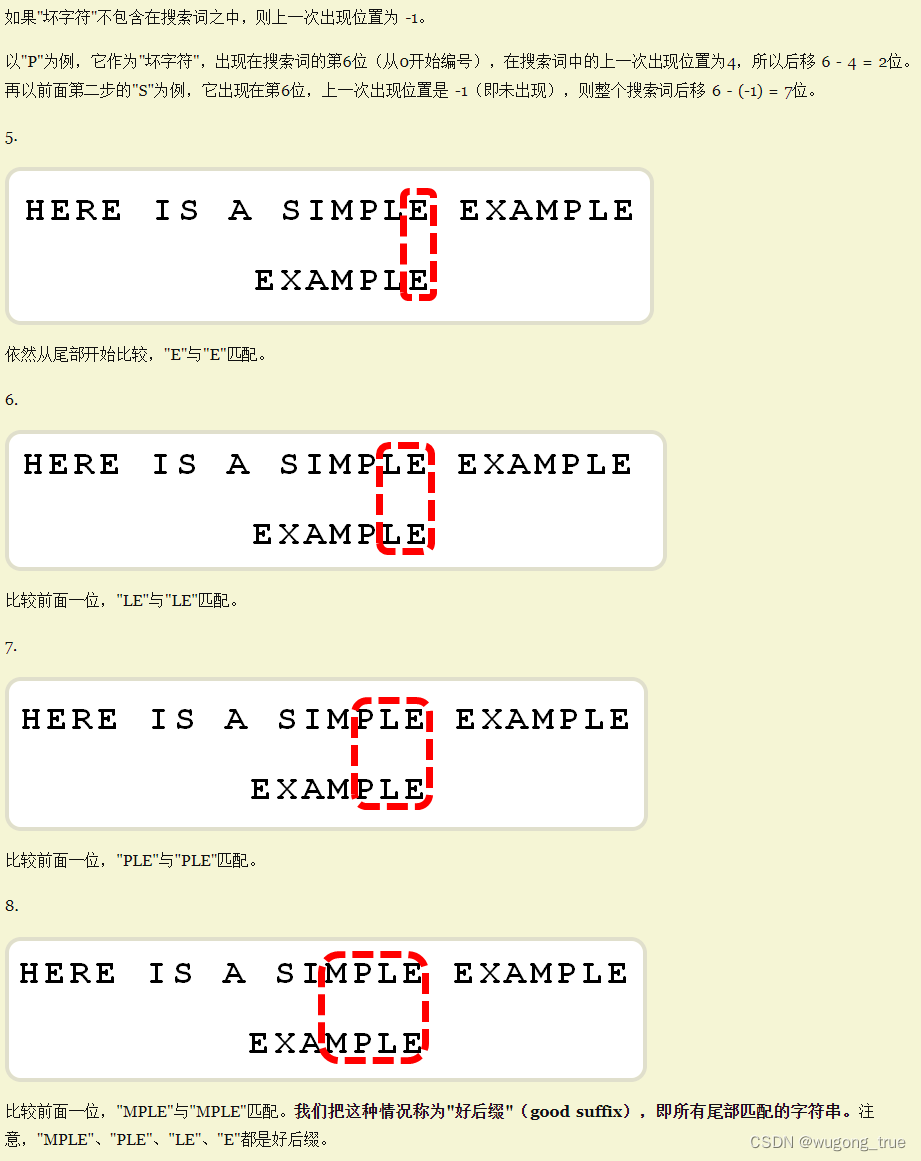
模式串和文本串 部分匹配成功,匹配成功的部分叫"好后缀"
- 例 ASIMPLE & EXAMPLE,其中 MPLE就是好后缀,同理PLE/LE/E都是好后缀
- 好后缀规则,后移位数 = 好后缀的位置 - 搜索词中的上一次出现位置
- 三个注意
- **"好后缀"的位置以最后一个字符为准。**假定"ABCDEF"的"EF"是好后缀,则它的位置以"F"为准,即5(从0开始计算)。
- 如果"好后缀"在搜索词中只出现一次,则它的上一次出现位置为 -1。比如,"EF"在"ABCDEF"之中只出现一次,则它的上一次出现位置为-1(即未出现)。
- 如果"好后缀"有多个,则除了最长的那个"好后缀",其他"好后缀"的上一次出现位置必须在头部。比如,假定"BABCDAB"的"好后缀"是"DAB"、“AB”、“B”,请问这时"好后缀"的上一次出现位置是什么?回答是,此时采用的好后缀是"B",它的上一次出现位置是头部,即第0位。这个规则也可以这样表达:如果最长的那个"好后缀"只出现一次,则可以把搜索词改写成如下形式进行位置计算"(DA)BABCDAB",即虚拟加入最前面的"DA"。
- 结合例子,所有的"好后缀"(MPLE、PLE、LE、E)之中,只"E"在"EXAMPLE"还出现在头部,所以后移 6 - 0 = 6位。(表示EXAMPLE到A匹配失败,结合第一条注意,好后缀以E为准)