本文来源公众号“极市平台”,仅用于学术分享,侵权删,干货满满。
原文链接:十分钟读懂Diffusion:图解Diffusion扩散模型

0. 极市导读
Diffusion是如何根据文字生成图片的?详解Diffusion的整个生成过程、训练过程等。
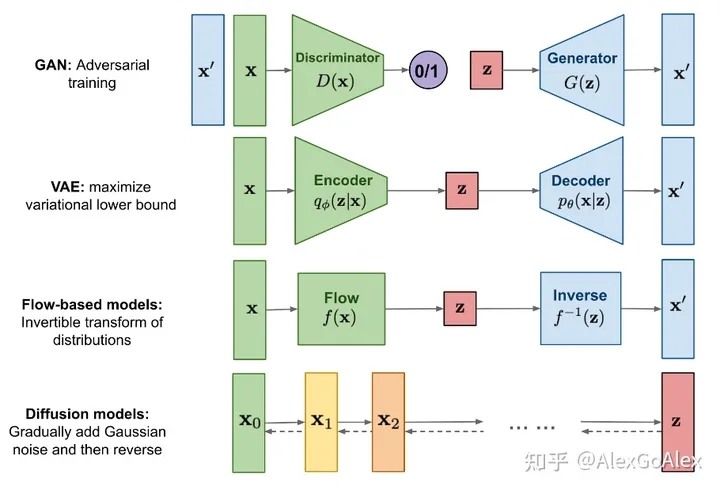
在之前的文章中,我们曾经介绍过Diffusion的具体原理,但是讲的还是比较偏理论,为了让大家快速了解Diffusion原理,这篇文章我们通过图解的方式。
绝密伏击:AIGC爆火的背后——扩散模型DDPM浅析
https://zhuanlan.zhihu.com/p/590840909
1. Diffusion文字生成图片——整体结构
1.1 整个生成过程
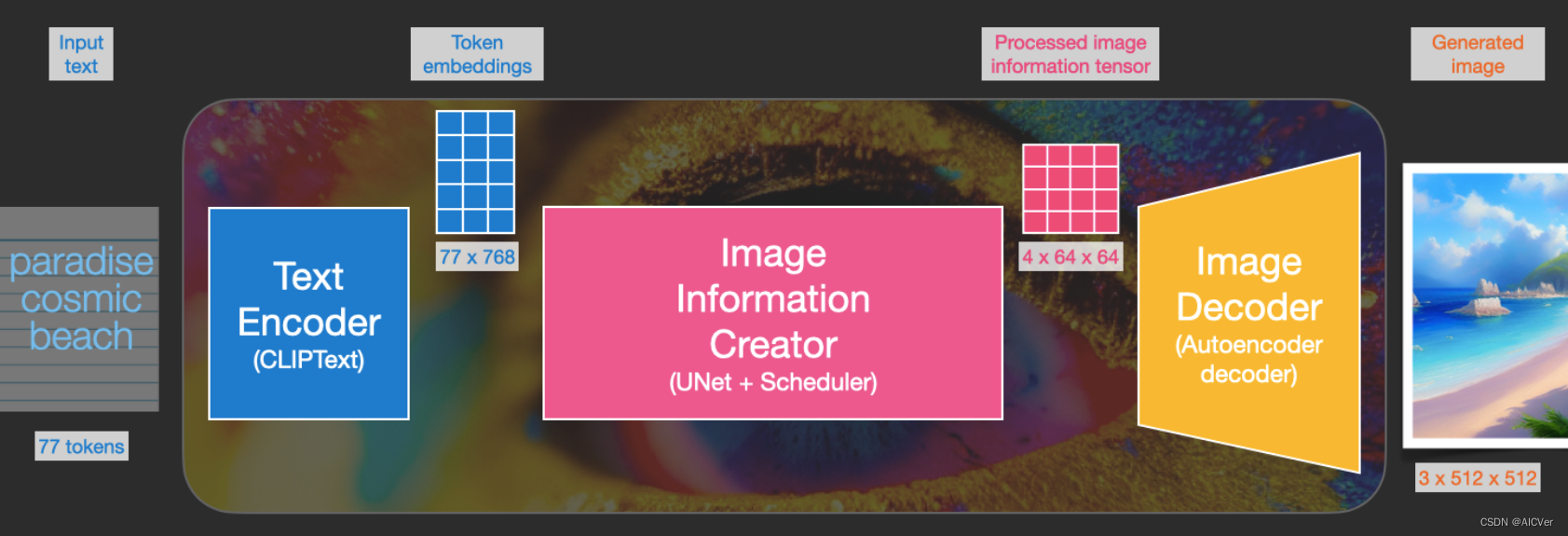
我们知道在使用 Diffusion 的时候,是通过文字生成图片,但是上一篇文章中讲的Diffusion模型输入只有随机高斯噪声和time step。那么文字是怎么转换成Diffusion的输入的呢?加入文字后 Diffusion 又有哪些改变?下图可以找到答案。

文字生成图片全过程
实际上 Diffusion 是使用Text Encoder生成文字对应的embedding(Text Encoder使用CLIP模型),然后和随机噪声embedding,time step embedding一起作为Diffusion的输入,最后生成理想的图片。我们看一下完整的图:

token embedding、随机噪声embedding、time embedding一起输入diffusion
上图我们看到了Diffusion的输入为token embedding和随机embedding,time embedding没有画出来。中间的Image Information Creator是由多个UNet模型组成,更详细的图如下:

更详细的结构
可以看到中间的Image Information Creator是由多个UNet组合而成的,关于UNet的结构我们放在后面来讲。
现在我们了解了加入文字embedding后 Diffusion 的结构,那么文字的embedding是如何生成的?接下来我们介绍下如何使用CLIP模型生成文字embedding。
1.2 使用CLIP模型生成输入文字embedding
CLIP 在图像及其描述的数据集上进行训练。想象一个看起来像这样的数据集,包含4 亿张图片及其说明:

图像及其文字说明
实际上CLIP是根据从网络上抓取的图像及其文字说明进行训练的。CLIP 是图像编码器和文本编码器的组合,它的训练过程可以简化为给图片加上文字说明。首先分别使用图像和文本编码器对它们进行编码。

然后使用余弦相似度刻画是否匹配。最开始训练时,相似度会很低。
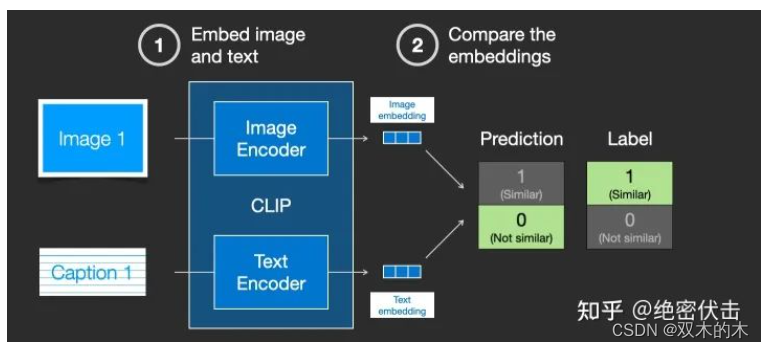
然后计算loss,更新模型参数,得到新的图片embedding和文字embedding
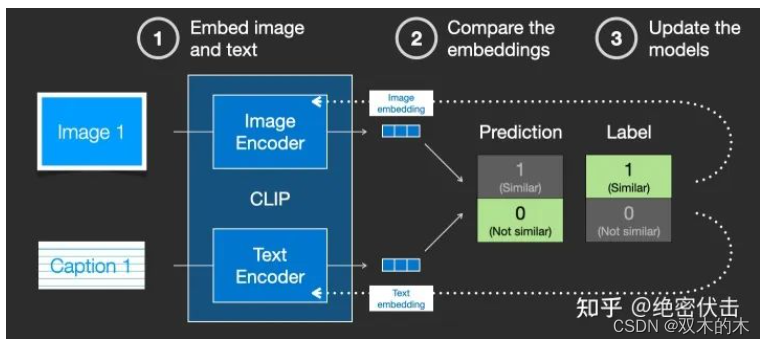
通过在训练集上训练模型,最终得到文字的embedding和图片的embedding。有关CLIP模型的细节,可以参考对应的论文(https://arxiv.org/pdf/2103.00020.pdf)。
1.3 UNet网络中如何使用文字embedding
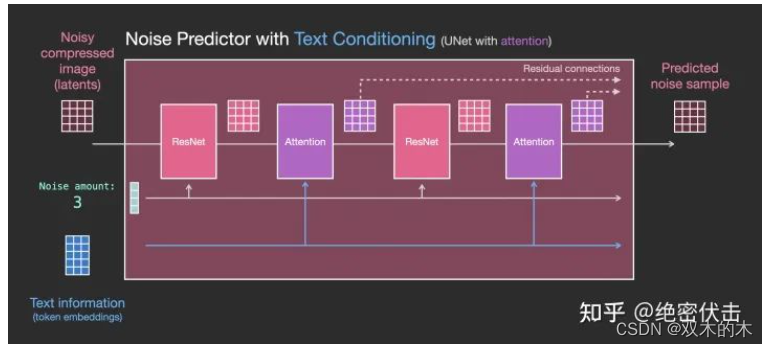
前面已经介绍了如何生成输入文字embedding,那么UNet网络又是如何使用的?实际上是在UNet的每个ResNet之间添加一个Attention,而Attention一端的输入便是文字embedding。如下图所示。

更详细的图如下:
2. 扩散模型Diffusion
前面介绍了Diffusion是如何根据输入文字生成图片的,让大家有个大概的了解,接下来会详细介绍扩散模型Diffusion是如何训练的,又是如何生成图片的。
2.1 扩散模型Duffison的训练过程
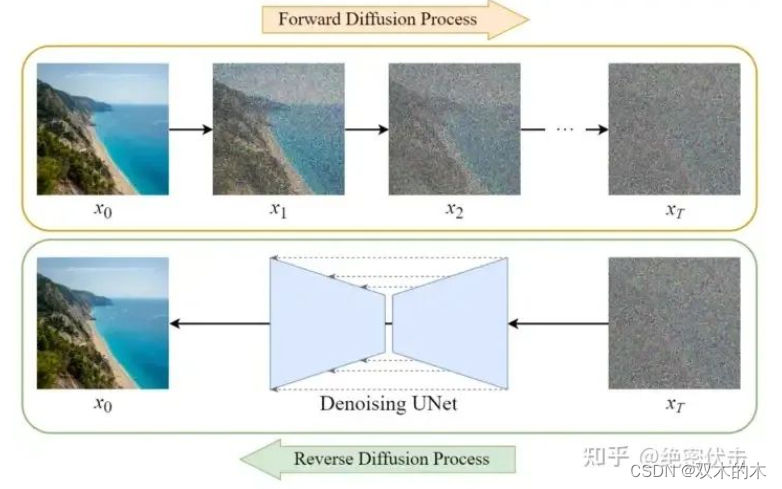
扩散模型Diffusion
Diffusion模型的训练可以分为两个部分:
前向扩散过程(Forward Diffusion Process) \rightarrow\rightarrow 图片中添加噪声
反向扩散过程(Reverse Diffusion Process) \rightarrow\rightarrow 去除图片中的噪声
2.2 前向扩散过程

前向扩散过程是不断往输入图片中添加高斯噪声。
2.3 反向扩散过程
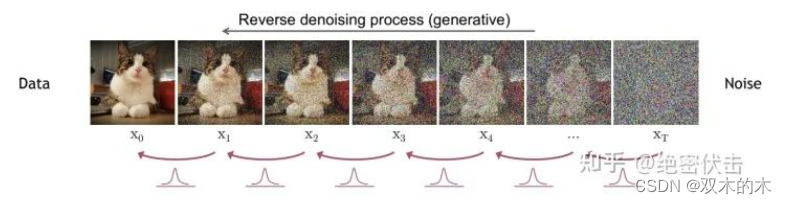
反向扩散过程是将噪声不断还原为原始图片。
2.4 训练过程

在每一轮的训练过程中,包含以下内容:
每一个训练样本选择一个随机时间步长 tt
将time step tt 对应的高斯噪声应用到图片中
将time step转化为对应embedding
下面是每一轮详细的训练过程:

2.5 从高斯噪声中生成原始图片(反向扩散过程)
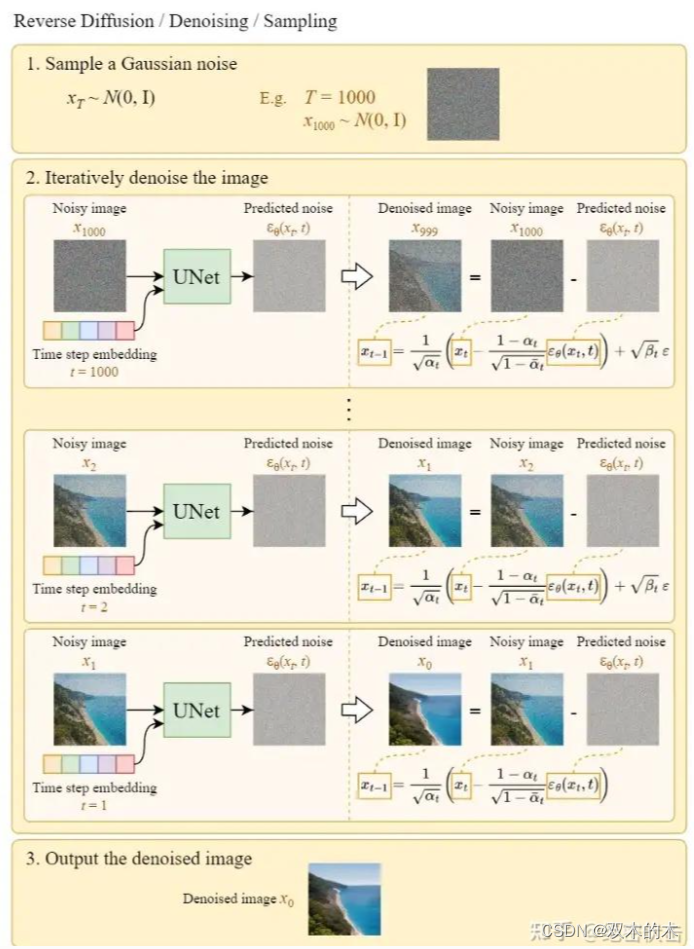
上图的Sample a Gaussian表示生成随机高斯噪声,Iteratively denoise the image表示反向扩散过程,如何一步步从高斯噪声变成输出图片。可以看到最终生成的Denoised image非常清晰。
补充1:UNet模型结构
前面已经介绍了Diffusion的整个过程,这里补充以下UNet的模型结构,如下图所示
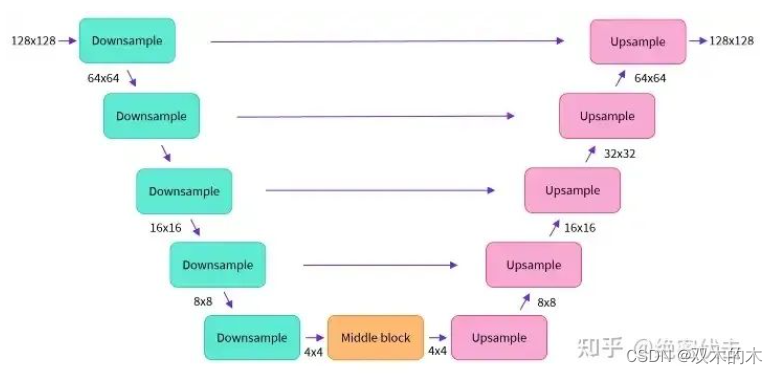
这里面Downsampe、Middle block、Upsample中都包含了ResNet残差网络。
补充2:Diffusion模型的缺点及改进版——Stable Diffusion
前面我们在介绍整个文字生成图片的架构中,图里面用的都是Stable Diffusion,后面介绍又主要介绍的是Diffusion。其实Stable Diffusion是Diffusion的改进版。
Diffusion的缺点是在反向扩散过程中需要把完整尺寸的图片输入到U-Net,这使得当图片尺寸以及time step t足够大时,Diffusion会非常的慢。Stable Diffusion就是为了解决这一问题而提出的。后面有时间再介绍下Stable Diffusion是如何改进的。
补充3:UNet网络同时输入文字embedding
在第2节介绍Diffusion原理的时候,为了方便,都是没有把输入文字embedding加进来,只用了time embedding和随机高斯噪声,怎么把文字embedding也加进来可以参考前面的1.3节。
补充4:DDPM为什么要引入时间步长_t_
引入时间步长 tt 是为了模拟一个随时间逐渐增强的扰动过程。每个时间步长 tt 代表一个扰动过程,从初始状态开始,通过多次应用噪声来逐渐改变图像的分布。因此,较小的 tt 代表较弱的噪声扰动,而较大的 tt 代表更强的噪声扰动。
这里还有一个原因,DDPM 中的 UNet 都是共享参数的,那如何根据不同的输入生成不同的输出,最后从一个完全的一个随机噪声变成一个有意义的图片,这还是一个非常难的问题。我们希望这个 UNet 模型在刚开始的反向过程之中,它可以先生成一些物体的大体轮廓,随着扩散模型一点一点往前走,然后到最后快生成逼真图像的时候,这时候希望它学习到高频的一些特征信息。由于 UNet 都是共享参数,这时候就需要 time embedding 去提醒这个模型,我们现在走到哪一步了,现在输出是想要粗糙一点的,还是细致一点的。
所以加入时间步长 tt 对生成和采样过程都有帮助。
补充5:为什么训练过程中每一次引入的是随机时间步长 t
我们知道模型在训练过程中 loss 会逐渐降低,越到后面 loss 的变化幅度越小。如果时间步长 tt 是递增的,那么必然会使得模型过多的关注较早的时间步长(因为早期 loss 大),而忽略了较晚的时间步长信息。
参考
https://medium.com/@steinsfu/stable-diffusion-clearly-explained-ed008044e07e
http://jalammar.github.io/illustrated-stable-diffusion/
https://pub.towardsai.net/getting-started-with-stable-diffusion-f343639e4931
https://zhuanlan.zhihu.com/p/597924053
https://zhuanlan.zhihu.com/p/590840909?
https://arxiv.org/abs/2103.00020
THE END!
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。